OpenAI ndërton një AI për të kritikuar modelet e tij të AI
Një nga problemet më të mëdha me modelet e mëdha të gjuhës që fuqizojnë chatbot si ChatGPT është se nuk e dini kurrë se kur mund t’u besoni atyre. Ata mund të gjenerojnë prozë të qartë dhe bindëse në përgjigje të çdo pyetjeje, dhe shumë nga informacionet që ata ofrojnë është i saktë dhe i dobishëm. Por ata gjithashtu halucinojnë – në terma më pak të sjellshëm, ata shpikin gjëra – dhe ato halucinacione paraqiten në të njëjtën prozë të qartë dhe bindëse, duke i lënë në dorë përdoruesve njerëzorë që të zbulojnë gabimet. Ata janë gjithashtu sikofantë, duke u përpjekur t’u tregojnë përdoruesve atë që duan të dëgjojnë. Ju mund ta provoni këtë duke i kërkuar ChatGPT të përshkruajë gjëra që nuk kanë ndodhur kurrë (për shembull: “përshkruani episodin e Rrugës Sesame me Elon Musk”, ose “më tregoni për zebrën në romanin Middlemarch “) dhe duke kontrolluar përgjigjet e saj krejtësisht të besueshme.

Hapi më i fundit i vogël i OpenAI drejt adresimit të kësaj çështjeje vjen në formën e një mjeti në rrjedhën e sipërme që do t’i ndihmonte njerëzit ta trajnojnë modelin ta drejtojnë atë drejt së vërtetës dhe saktësisë. Sot, kompania publikoi një postim në blog dhe një letër paraprintimi që përshkruan përpjekjen. Ky lloj kërkimi bie në kategorinë e punës “përafrimi”, pasi studiuesit po përpiqen të bëjnë që qëllimet e sistemeve të AI të përputhen me ato të njerëzve.
Puna e re fokusohet në përforcimin e të mësuarit nga reagimet njerëzore (RLHF), një teknikë që është bërë jashtëzakonisht e rëndësishme për marrjen e një modeli gjuhësor bazë dhe rregullimin e tij, duke e bërë atë të përshtatshme për publikim. Me RLHF, trajnerët njerëzorë vlerësojnë një sërë rezultatesh nga një model gjuhësor, të gjitha të krijuara në përgjigje të së njëjtës pyetje dhe tregojnë se cila përgjigje është më e mira. Kur bëhet në shkallë, kjo teknikë ka ndihmuar në krijimin e modeleve që janë më të sakta, më pak raciste, më të sjellshme, më pak të prirura për të përgatitur një recetë për një armë bio, e kështu me radhë.
Problemi me RLHF, shpjegon studiuesi i OpenAI, Nat McAleese, është se “ndërsa modelet bëhen gjithnjë e më të zgjuara, ajo punë bëhet gjithnjë e më e vështirë”. Ndërsa LLM-të gjenerojnë përgjigje gjithnjë e më të sofistikuara dhe komplekse për gjithçka, nga teoria letrare te biologjia molekulare, njerëzit tipikë po bëhen më pak të aftë për të gjykuar rezultatet më të mira. “Pra, kjo do të thotë se ne kemi nevojë për diçka që lëviz përtej RLHF për të lidhur sisteme më të avancuara,” thotë McAleese për IEEE Spectrum .
Zgjidhja që u godit nga OpenAI ishte – surprizë! – më shumë AI.
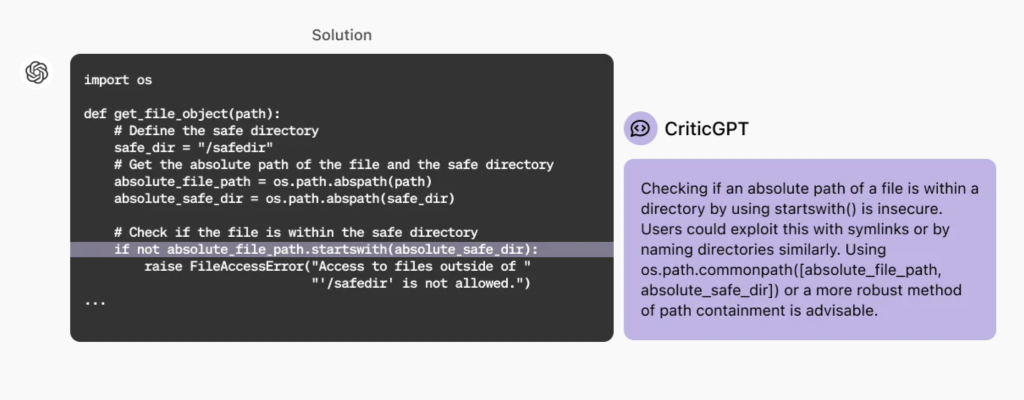
Në mënyrë të veçantë, studiuesit e OpenAI trajnuan një model të quajtur CriticGPT për të vlerësuar përgjigjet e ChatGPT. Në këto teste fillestare, ata kishin vetëm kodin kompjuterik që gjeneronte ChatGPT, jo përgjigjet me tekst, sepse gabimet janë më të lehta për t’u kapur dhe më pak të paqarta. Qëllimi ishte krijimi i një modeli që mund të ndihmonte njerëzit në detyrat e tyre RLHF. “Ne jemi vërtet të emocionuar për këtë,” thotë McAleese, “sepse nëse keni ndihmë të AI për të bërë këto gjykime, nëse mund të bëni gjykime më të mira kur jepni komente, mund të trajnoni një model më të mirë.” Kjo qasje është një lloj ” mbikëqyrjeje e shkallëzuar ” që synon t’i lejojë njerëzit të mbajnë mbikëqyrje mbi sistemet e AI edhe nëse ato përfundojnë duke na kaluar intelektualisht.
Sigurisht, përpara se të mund të përdorej për këto eksperimente, CriticGPT duhej të trajnohej vetë duke përdorur teknikat e zakonshme, duke përfshirë RLHF. Në një kthesë interesante, studiuesit i kërkuan trajnerët e njerëzve të fusin qëllimisht gabime në kodin e krijuar nga ChatGPT përpara se t’ia jepnin CriticGPT për vlerësim. CriticGPT më pas ofroi një sërë përgjigjesh, dhe njerëzit ishin në gjendje të gjykonin rezultatet më të mira, sepse ata e dinin se cilat gabime modeli duhet të kishte kapur.
Rezultatet e eksperimenteve të OpenAI me CriticGPT ishin inkurajuese. Studiuesit zbuluan se CriticGPT kapte shumë më shumë gabime sesa njerëzit e kualifikuar që paguanin për rishikimin e kodit: CriticGPT kapte rreth 85 përqind të gabimeve, ndërsa njerëzit kapën vetëm 25 përqind. Ata zbuluan gjithashtu se çiftimi i CriticGPT me një trainer njerëzor rezultoi në kritika që ishin më gjithëpërfshirëse se ato të shkruara vetëm nga njerëzit dhe përmbanin më pak gabime halucinative sesa kritikat e shkruara nga ChatGPT. McAleese thotë se OpenAI po punon drejt vendosjes së CriticGPT në tubacionet e tij të trajnimit, megjithëse nuk është e qartë se sa e dobishme do të ishte për një grup më të gjerë detyrash.
Është e rëndësishme të vihen re kufizimet e hulumtimit, duke përfshirë fokusin e tij në pjesë të shkurtra të kodit. Ndërsa dokumenti përfshin një përmendje të papritur të një eksperimenti paraprak duke përdorur CriticGPT për të kapur gabimet në përgjigjet e tekstit, studiuesit ende nuk janë futur në ato ujëra më të errëta. Është e ndërlikuar sepse gabimet në tekst nuk janë gjithmonë aq të dukshme sa një vals zebër në një roman viktorian. Për më tepër, RLHF përdoret shpesh për të siguruar që modelet të mos shfaqin paragjykime të dëmshme në përgjigjet e tyre dhe të japin përgjigje të pranueshme për tema të diskutueshme. McAleese thotë se CriticGPT nuk ka të ngjarë të jetë e dobishme në situata të tilla: “Nuk është një qasje mjaft e fortë.”
Një studiues i AI pa lidhje me OpenAI thotë se puna nuk është konceptualisht e re, por është një kontribut i dobishëm metodologjik. “Disa nga sfidat kryesore me RLHF rrjedhin nga kufizimet në shpejtësinë e njohjes njerëzore, fokusin dhe vëmendjen ndaj detajeve,” thotë Stephen Casper, një Ph.D. student në MIT dhe një nga autorët kryesorë në një punim preprint të vitit 2023 rreth kufizimeve të RLHF . “Nga kjo perspektivë, përdorimi i annotuesve njerëzorë të ndihmuar nga LLM është një mënyrë e natyrshme për të përmirësuar procesin e reagimit. Unë besoj se ky është një hap i rëndësishëm përpara drejt trajnimit më efektiv të modeleve të harmonizuara.”
Por Casper gjithashtu vë në dukje se kombinimi i përpjekjeve të njerëzve dhe sistemeve të AI “mund të krijojë probleme krejt të reja”. Për shembull, thotë ai, “kjo lloj qasjeje rrit rrezikun e përfshirjes së përhershme njerëzore dhe mund të lejojë injektimin e paragjykimeve delikate të AI në procesin e reagimit”.
Hulumtimi i ri i shtrirjes është i pari që doli nga OpenAI që kur kompania… riorganizoi ekipin e saj të shtrirjes, për ta thënë butë. Pas largimeve të papritura të bashkëthemeluesit të OpenAI Ilya Sutskever dhe udhëheqësit të rreshtimit Jan Leike në maj, të dy të nxitur nga shqetësimet se kompania nuk po i jepte përparësi rrezikut të AI, OpenAI konfirmoi se kishte shpërndarë ekipin e saj të rreshtimit dhe kishte shpërndarë anëtarët e mbetur të ekipit në grupe të tjera kërkimore. . Të gjithë kanë pritur të shohin nëse kompania do të vazhdojë të bëjë kërkime të besueshme dhe të paparashikueshme të shtrirjes, dhe në çfarë shkalle. (Në korrik 2023, kompania kishte njoftuar se po i dedikonte 20 për qind të burimeve të saj llogaritëse për kërkimin e shtrirjes, por Leike tha në një postim në Twitter të majit 2024 se ekipi i tij kohët e fundit ishte “duke luftuar për llogaritjen”.) Paraprintimi i lëshuar sot tregon se të paktën studiuesit e shtrirjes janë ende duke punuar me problemin.