Studimi zbulon një rritje të shpejtë të domeneve të internetit që bllokojnë modelet e AI nga të dhënat e trajnimit

Një studim i ri zbulon se modelet e AI po humbasin gjithnjë e më shumë aksesin në të dhënat e tyre të trajnimit të bazuara në ueb. Ky trend në rritje i kufizimeve mund t’i detyrojë modelet të mësojnë nga informacione më pak, më të njëanshme dhe të vjetruara në të ardhmen.
Iniciativa e origjinës së të dhënave, një grup i pavarur akademik, kreu një studim në shkallë të gjerë që dokumenton një rënie të shpejtë të aksesit të të dhënave në ueb për modelet e AI. Studiuesit analizuan skedarët robots.txt dhe kushtet e përdorimit për 14,000 domene ueb që shërbejnë si burime për grupet e të dhënave të trajnimit të AI si C4, RefinedWeb dhe Dolma.
Nga prilli 2023 deri në prill 2024, përqindja e shenjave në këto grupe të dhënash të bllokuara plotësisht për zvarritësit e AI u rrit nga rreth 1% në 5-7%. Shenjat janë përbërësit individualë të fjalive dhe fjalëve që përdoren për të trajnuar modelet e AI.
Rritja ishte edhe më e rëndësishme për burimet kryesore të të dhënave, ku përqindja e tokenëve të bllokuar u hodh nga më pak se 3% në 20-33%. Studiuesit parashikojnë se ky trend do të vazhdojë edhe në muajt e ardhshëm. OpenAI përballet me blloqet më të shpeshta, të ndjekura nga Anthropic dhe Google.
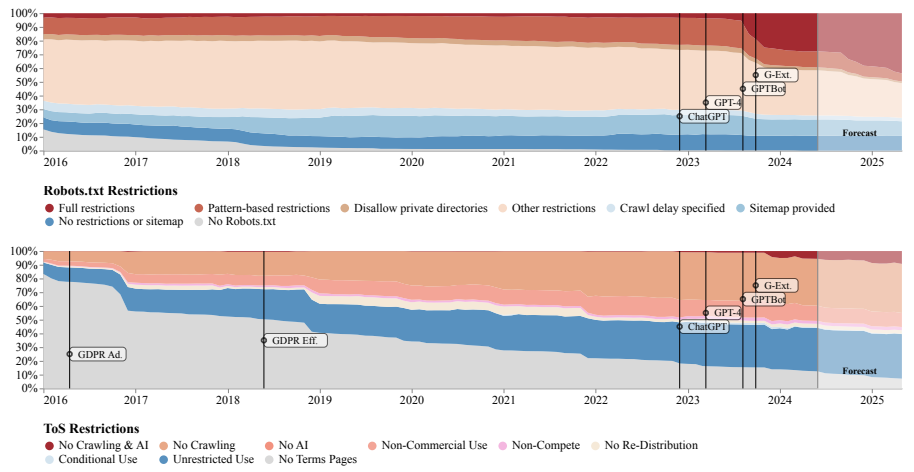
Uebsajtet e lajmeve, forumet dhe platformat e mediave sociale janë burimet kryesore që vendosin kufizime. Në faqet e lajmeve, pjesa e tokenëve plotësisht të bllokuar u rrit nga 3% në 45% brenda një viti.
Si rezultat, përfaqësimi i tyre në të dhënat e trajnimit ka të ngjarë të bjerë në favor të faqeve të korporatave dhe të tregtisë elektronike, të cilat kanë më pak kufizime, por shpesh përmbajtje me cilësi më të ulët. Ky trend mund të prekë veçanërisht zhvilluesit e AI, pasi industria ka kuptuar se të mësuarit nga të dhënat me cilësi të lartë prodhon modele më të mira.
Studimi gjithashtu thekson një pabarazi midis përdorimit aktual të modeleve gjeneruese të AI dhe përmbajtjes së të dhënave të tyre të trajnimit. Kjo mund të jetë e rëndësishme në rastet ligjore kur botuesit padisin kompanitë e AI, duke pretenduar se shërbime si ChatGPT konkurrojnë me ofertat e tyre të informacionit bazuar në përmbajtjen e botuesve.

Në përgjithësi, ky zhvillim mund ta bëjë më të vështirë, ose të paktën më të kushtueshëm, trajnimin e sistemeve të fuqishme dhe të besueshme të AI. Ofruesit e përmbajtjes me cilësi të lartë mund të gjejnë burime të reja të ardhurash dhe të bëhen përfitues kryesorë. Por CEO i OpenAI dhe Meta Mark Zuckerberg thanë gjithashtu se licencimi i të gjitha të dhënave që u nevojiten për të trajnuar një model të mirë të AI do të ishte i pamundur ose i papërballueshëm.
Për shembull, OpenAI kohët e fundit ka negociuar disa marrëveshje shumë milionëshe me botuesit për të hyrë në përmbajtjen e tyre për shfaqje në kohë reale në sistemet e bisedave dhe trajnimin e AI. Kompanitë e tjera ka të ngjarë të ndjekin shembullin, përveç nëse një vendim i përdorimit të drejtë e ndryshon në mënyrë dramatike situatën.