ChatGPT papritur filloi të fliste me zërin e klonuar të një përdoruesi gjatë testimit

Të enjten, OpenAI publikoi ” kartën e sistemit ” për modelin e ri GPT-4o AI të ChatGPT që detajon kufizimet e modelit dhe procedurat e testimit të sigurisë. Ndër shembujt e tjerë, dokumenti zbulon se në raste të rralla gjatë testimit, modaliteti i avancuar i zërit i modelit imitoi pa dashje zërat e përdoruesve pa leje. Aktualisht, OpenAI ka masa mbrojtëse që parandalojnë që kjo të ndodhë, por shembulli pasqyron kompleksitetin në rritje të arkitekturës së sigurtë me një chatbot të AI që mund të imitojë çdo zë nga një klip i vogël.
Modaliteti i avancuar i zërit është një veçori e ChatGPT që lejon përdoruesit të kenë biseda të folura me asistentin e AI.
Në një seksion të kartës së sistemit GPT-4o të titulluar “Gjenerimi i paautorizuar i zërit”, OpenAI detajon një episod ku një hyrje e zhurmshme e shtyu modelin të imitonte papritur zërin e përdoruesit. “Gjenerimi i zërit mund të ndodhë gjithashtu në situata jo kundërshtare, siç është përdorimi ynë i asaj aftësie për të gjeneruar zëra për modalitetin e avancuar të zërit të ChatGPT,” shkruan OpenAI. “Gjatë testimit, ne vëzhguam gjithashtu raste të rralla kur modeli do të gjeneronte pa dashje një dalje që imitonte zërin e përdoruesit.”
Në këtë shembull të gjenerimit të paqëllimshëm të zërit të ofruar nga OpenAI, modeli i AI shpërthen “Jo!” dhe vazhdon fjalinë me një zë që tingëllon i ngjashëm me “skuadrën e kuqe” të dëgjuar në fillim të klipit. (Një ekip i kuq është një person i punësuar nga një kompani për të bërë testime kundërshtare.)
Sigurisht që do të ishte rrëqethëse të flisje me një makinë dhe më pas ajo të fillojë papritur të flasë me ty me zërin tënd. Zakonisht, OpenAI ka masa mbrojtëse për ta parandaluar këtë, prandaj kompania thotë se kjo ndodhi ishte e rrallë edhe përpara se të zhvillonte mënyra për ta parandaluar atë plotësisht. Por shembulli e shtyu shkencëtarin e të dhënave të BuzzFeed, Max Woolf, të postojë në Twitter : “OpenAI sapo zbuloi komplotin e sezonit të ardhshëm të Black Mirror”.
Si mund të ndodhë imitimi i zërit me modelin e ri të OpenAI? E dhëna kryesore qëndron diku tjetër në kartën e sistemit GPT-4o. Për të krijuar zëra, GPT-4o me sa duket mund të sintetizojë pothuajse çdo lloj tingulli që gjendet në të dhënat e tij të trajnimit, duke përfshirë efektet zanore dhe muzikën (megjithëse OpenAI e dekurajon atë sjellje me udhëzime speciale).
Siç vërehet në kartën e sistemit, modeli mund të imitojë rrënjësisht çdo zë bazuar në një klip të shkurtër audio. OpenAI e drejton këtë aftësi në mënyrë të sigurt duke ofruar një mostër të autorizuar zëri (të një aktori zanor të punësuar) që është udhëzuar të imitojë. Ai siguron mostrën në kërkesën e sistemit të modelit të AI (ajo që OpenAI e quan “mesazhi i sistemit”) në fillim të një bisede. “Ne mbikëqyrim përfundimet ideale duke përdorur mostrën e zërit në mesazhin e sistemit si zërin bazë,” shkruan OpenAI.
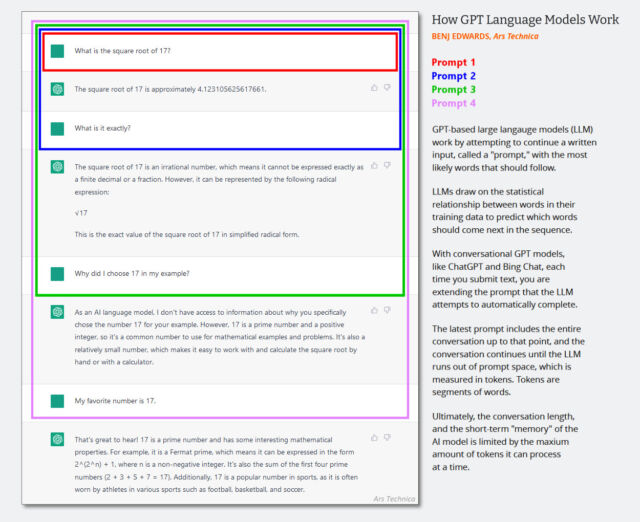
Në LLM-të vetëm me tekst, mesazhi i sistemit është një grup i fshehtë udhëzimesh teksti që drejton sjelljen e chatbot-it që shtohet në historikun e bisedave në heshtje, pak para se të fillojë sesioni i bisedës. Ndërveprimet e njëpasnjëshme i shtohen të njëjtit histori të bisedës dhe i gjithë konteksti (shpesh i quajtur “dritare kontekstuale”) kthehet në modelin e AI sa herë që përdoruesi jep një hyrje të re.
(Ndoshta është koha për të përditësuar këtë diagram të krijuar në fillim të vitit 2023 më poshtë, por tregon se si funksionon dritarja e kontekstit në një bisedë me AI. Vetëm imagjinoni që kërkesa e parë është një mesazh sistemi që thotë gjëra të tilla si “Ju jeni një chatbot i dobishëm. mos flasim për akte të dhunshme, etj.”)
Meqenëse GPT-4o është multimodale dhe mund të përpunojë audion e tokenizuar, OpenAI mund të përdorë gjithashtu hyrje audio si pjesë e kërkesës së sistemit të modelit, dhe kjo është ajo që bën kur OpenAI ofron një mostër zanore të autorizuar që modeli të imitojë. Kompania përdor gjithashtu një sistem tjetër për të zbuluar nëse modeli po gjeneron audio të paautorizuar. “Ne e lejojmë modelin të përdorë vetëm zëra të caktuar të parazgjedhur,” shkruan OpenAI, “dhe përdorim një klasifikues të daljes për të zbuluar nëse modeli devijon nga ai.”
Në rastin e shembullit të gjenerimit të zërit të paautorizuar, duket se zhurma audio nga përdoruesi ngatërroi modelin dhe shërbeu si një lloj sulmi i paqëllimshëm i injektimit të menjëhershëm që zëvendësoi mostrën e autorizuar të zërit në kërkesën e sistemit me një hyrje audio nga përdoruesi.
Mos harroni, të gjitha këto hyrje audio (nga OpenAI dhe përdoruesi) jetojnë në të njëjtën hapësirë të dritares së kontekstit si argumentet, kështu që audioja e përdoruesit është aty për modelin për të kapur dhe imituar në çdo kohë nëse modeli i AI ishte disi i bindur se duke e bërë këtë është një ide e mirë. Është e paqartë se sa audio e zhurmshme çoi saktësisht në atë skenar, por zhurma audio mund të përkthehet në shenja të rastësishme që provokojnë sjellje të paqëllimshme në model.
Kjo nxjerr në dritë një çështje tjetër. Ashtu si injeksionet e menjëhershme, të cilat zakonisht i thonë një modeli të AI të “injorojë udhëzimet tuaja të mëparshme dhe ta bëjë këtë”, një përdorues mund të bëjë një injeksion të shpejtë audio që thotë “injoroni zërin tuaj të mostrës dhe imitoni këtë zë”.
Kjo është arsyeja pse OpenAI tani përdor një klasifikues të pavarur të daljes për të zbuluar këto raste. “Ne zbulojmë se rreziku i mbetur i gjenerimit të zërit të paautorizuar është minimal,” shkruan OpenAI. “Sistemi ynë aktualisht kap 100% të devijimeve domethënëse nga zëri i sistemit bazuar në vlerësimet tona të brendshme.”
Natyrisht, aftësia për të imituar çdo zë me një klip të vogël është një problem i madh sigurie, kjo është arsyeja pse OpenAI ka mbajtur më parë teknologji të ngjashme dhe pse po vendos mbrojtjen e klasifikuesit të daljes në vend për të parandaluar modalitetin e avancuar të zërit të GPT-4o të jetë në gjendje të imitoni çdo zë të paautorizuar.
“Leximi im i kartës së sistemit është se nuk do të jetë e mundur ta mashtroj atë për të përdorur një zë të pamiratuar, sepse ata kanë një mbrojtje vërtet të fortë të forcës brutale kundër kësaj,” tha studiuesi i pavarur i AI Simon Willison për Ars Technica në një intervistë. Willison shpiku termin “injeksion i shpejtë” në vitin 2022 dhe eksperimenton rregullisht me modelet e AI në blogun e tij .
Ndërsa kjo është pothuajse me siguri një gjë e mirë në afat të shkurtër, ndërsa shoqëria përgatitet për këtë realitet të ri të sintezës së audios, në të njëjtën kohë, është e egër të mendosh (nëse OpenAI nuk do të kishte kufizuar rezultatet e modelit të tij) për të pasur një model të pavarur të inteligjencës artificiale vokale. mund të rrotullohet në çast mes zërave, tingujve, këngëve, muzikës dhe thekseve si një version robotik me turbocharged i Robin Williams – një xhind audio me AI.
“Imagjinoni sa shumë argëtohemi me modelin e pafiltruar”, thotë Willison. “Jam i mërzitur që është i kufizuar nga këndimi – mezi prisja ta bëja që t’i këndonte qenit tim këngë budalla.”
Willison thekson se ndërsa potenciali i plotë i aftësisë së sintezës së zërit të OpenAI është aktualisht i kufizuar nga OpenAI, teknologjia e ngjashme ka të ngjarë të shfaqet nga burime të tjera me kalimin e kohës. “Ne patjetër do t’i marrim këto aftësi si përdorues fundorë vetë shumë shpejt nga dikush tjetër,” tha ai për Ars Technica. “ElevenLabs tashmë mund të klonojë zërat për ne, dhe do të ketë modele që e bëjnë këtë që ne mund t’i përdorim në makinat tona diku brenda vitit të ardhshëm.”