DeepSeek-R1 me burim të hapur përdor mësim përforcues të pastër për t’iu përshtatur OpenAI o1 – me 95% më pak kosto
Startup kinez i AI DeepSeek, i njohur për sfidimin e shitësve kryesorë të AI me teknologji me burim të hapur, sapo hodhi një tjetër bombë: një LLM të ri arsyetimi të hapur të quajtur DeepSeek-R1.
Bazuar në modelin e përzierjes së ekspertëve të prezantuar së fundmi DeepSeek V3, DeepSeek-R1 përputhet me performancën e o1, LLM-ja e arsyetimit kufitar të OpenAI, përgjatë detyrave të matematikës, kodimit dhe arsyetimit. Pjesa më e mirë? E bën këtë me një kosto shumë më joshëse, duke u dëshmuar se është 90-95% më e përballueshme se kjo e fundit.
Publikimi shënon një hap të madh përpara në arenën me burim të hapur. Ajo tregon se modelet e hapura po e mbyllin më tej hendekun me modelet tregtare të mbyllura në garën ndaj inteligjencës së përgjithshme artificiale (AGI). Për të treguar aftësinë e punës së tij, DeepSeek përdori gjithashtu R1 për të distiluar gjashtë modele Llama dhe Qwen, duke e çuar performancën e tyre në nivele të reja. Në një rast, versioni i distiluar i Qwen-1.5B ia kalonte modeleve shumë më të mëdha, GPT-4o dhe Claude 3.5 Sonnet, në standarde të zgjedhura matematikore.
Këto modele të distiluara, së bashku me R1 kryesore, kanë qenë me burim të hapur dhe janë në dispozicion në Hugging Face nën një licencë MIT.
Fokusi është duke u mprehur në inteligjencën e përgjithshme artificiale (AGI), një nivel i AI që mund të kryejë detyra intelektuale si njerëzit. Shumë ekipe po dyfishojnë në rritjen e aftësive të arsyetimit të modeleve. OpenAI bëri lëvizjen e parë të dukshme në domen me modelin e tij o1, i cili përdor një proces të arsyetimit të zinxhirit të mendimit për të trajtuar një problem. Nëpërmjet RL (të mësuarit përforcues, ose optimizimi i nxitur nga shpërblimi), o1 mëson të përmirësojë zinxhirin e tij të mendimit dhe të rafinojë strategjitë që përdor – në fund të fundit të mësojë të njohë dhe korrigjojë gabimet e tij, ose të provojë qasje të reja kur ato aktuale nuk funksionojnë.
Tani, duke vazhduar punën në këtë drejtim, DeepSeek ka lëshuar DeepSeek-R1, i cili përdor një kombinim të RL dhe rregullim të mirë të mbikëqyrur për të trajtuar detyra komplekse arsyetimi dhe për të përputhur performancën e o1.
Kur u testua, DeepSeek-R1 shënoi 79,8% në testet e matematikës AIME 2024 dhe 97,3% në MATH-500. Ai gjithashtu arriti një vlerësim 2,029 në Codeforces – më mirë se 96.3% e programuesve njerëzorë. Në të kundërt, o1-1217 shënoi respektivisht 79.2%, 96.4% dhe 96.6% në këto standarde.
Ai gjithashtu tregoi njohuri të forta të përgjithshme, me saktësi 90.8% në MMLU, pak pas 91.8% të o1.
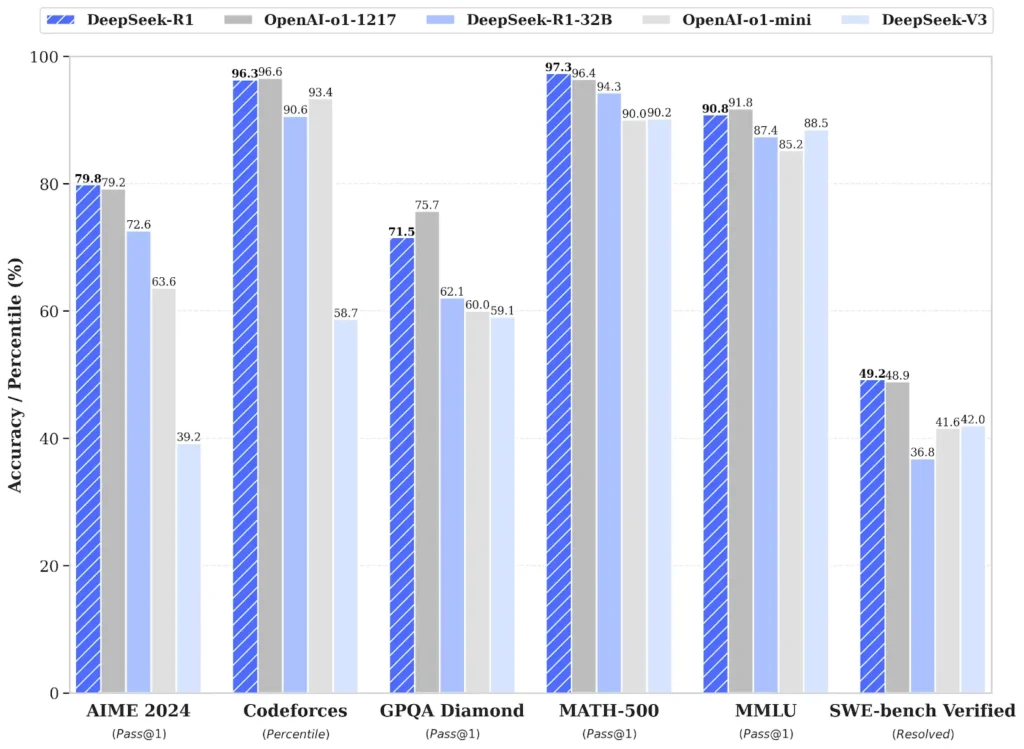
Performanca e arsyetimit të DeepSeek-R1 shënon një fitore të madhe për startupin kinez në hapësirën e inteligjencës artificiale të dominuar nga SHBA, veçanërisht pasi e gjithë puna është me burim të hapur, duke përfshirë mënyrën se si kompania e ka trajnuar të gjithë.
Sidoqoftë, puna nuk është aq e drejtpërdrejtë sa duket.
Sipas letrës që përshkruan hulumtimin, DeepSeek-R1 u zhvillua si një version i përmirësuar i DeepSeek-R1-Zero – një model përparimtar i trajnuar vetëm nga të mësuarit përforcues.
Kompania përdori fillimisht bazën DeepSeek-V3 si model bazë, duke zhvilluar aftësitë e saj të arsyetimit pa përdorur të dhëna të mbikëqyrura, duke u fokusuar në thelb vetëm në vetë-evoluimin e saj përmes një procesi të pastër provë dhe gabimi të bazuar në RL. E zhvilluar në thelb nga puna, kjo aftësi siguron që modeli të mund të zgjidhë detyra arsyetimi gjithnjë e më komplekse duke shfrytëzuar llogaritjen e zgjatur të kohës së testimit për të eksploruar dhe përmirësuar proceset e tij të mendimit në thellësi më të madhe.
“Gjatë trajnimit, DeepSeek-R1-Zero u shfaq natyrshëm me sjellje të shumta arsyetimi të fuqishme dhe interesante,” shënojnë studiuesit në letër. “Pas mijëra hapash RL, DeepSeek-R1-Zero shfaq super performancë në standardet e arsyetimit. Për shembull, rezultati pass@1 në AIME 2024 rritet nga 15.6% në 71.0%, dhe me votimin e shumicës, rezultati përmirësohet më tej në 86.7%, duke përputhur performancën e OpenAI-o1-0912.
Megjithatë, pavarësisht se tregoi performancë të përmirësuar, duke përfshirë sjellje si reflektimi dhe eksplorimi i alternativave, modeli fillestar tregoi disa probleme, duke përfshirë lexueshmërinë e dobët dhe përzierjen e gjuhës. Për ta rregulluar këtë, kompania ndërtoi punën e bërë për R1-Zero, duke përdorur një qasje me shumë faza që kombinon mësimin e mbikëqyrur dhe mësimin përforcues, dhe kështu doli me modelin e përmirësuar R1.
“Në mënyrë të veçantë, ne fillojmë me mbledhjen e mijëra të dhënave të fillimit të ftohtë për të rregulluar mirë modelin DeepSeek-V3-Base,” shpjeguan studiuesit. “Pas kësaj, ne kryejmë RL të orientuar drejt arsyetimit si DeepSeek-R1- Zero. Me afrimin e konvergjencës në procesin e RL, ne krijojmë të dhëna të reja SFT përmes kampionimit të refuzimit në pikën e kontrollit RL, të kombinuara me të dhëna të mbikëqyrura nga DeepSeek-V3 në fusha të tilla si shkrimi, siguria e sigurimit faktik dhe njohja e vetvetes, dhe më pas ritrajnojmë DeepSeek-V3 – Modeli bazë. Pas rregullimit të imët me të dhënat e reja, pika e kontrollit i nënshtrohet një procesi shtesë RL, duke marrë parasysh kërkesat nga të gjithë skenarët. Pas këtyre hapave, ne morëm një pikë kontrolli të referuar si DeepSeek-R1, e cila arrin performancë të barabartë me OpenAI-o1-1217.
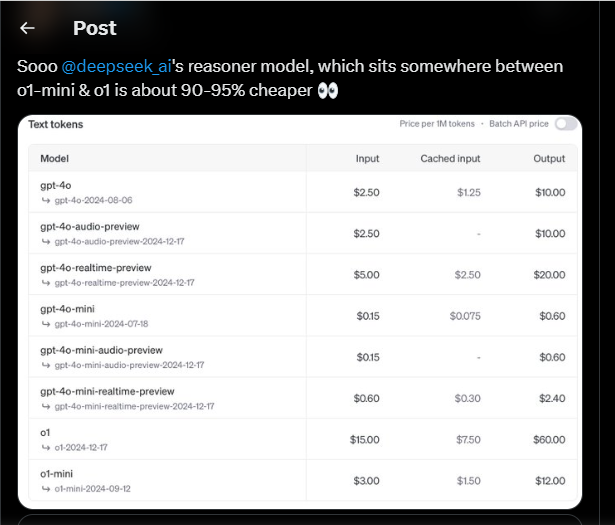
Përveç performancës së përmirësuar që pothuajse përputhet me o1 të OpenAI në të gjithë standardet, DeepSeek-R1 i ri është gjithashtu shumë i përballueshëm. Në mënyrë të veçantë, ku OpenAI o1 kushton 15 dollarë për milion argumente hyrëse dhe 60 dollarë për milion argumente dalëse, DeepSeek Reasoner, i cili bazohet në modelin R1, kushton 0,55 dollarë për milion hyrje dhe 2,19 dollarë për milion argumente dalëse.
Modeli mund të testohet si “DeepThink” në platformën e bisedës DeepSeek, e cila është e ngjashme me ChatGPT. Përdoruesit e interesuar mund të hyjnë në depon e peshave të modelit dhe kodeve nëpërmjet Hugging Face, nën një licencë MIT, ose mund të shkojnë me API për integrim të drejtpërdrejtë.