DeepSeek po sfidon Midjourney dhe DALL-E

DeepSeek, laboratori kinez i AI që së fundi përmbysi supozimet e industrisë në lidhje me kostot e zhvillimit të sektorit, ka lëshuar një familje të re modelesh multimodale të AI me burim të hapur që thuhet se tejkalojnë DALL-E 3 të OpenAI në standardet kryesore.
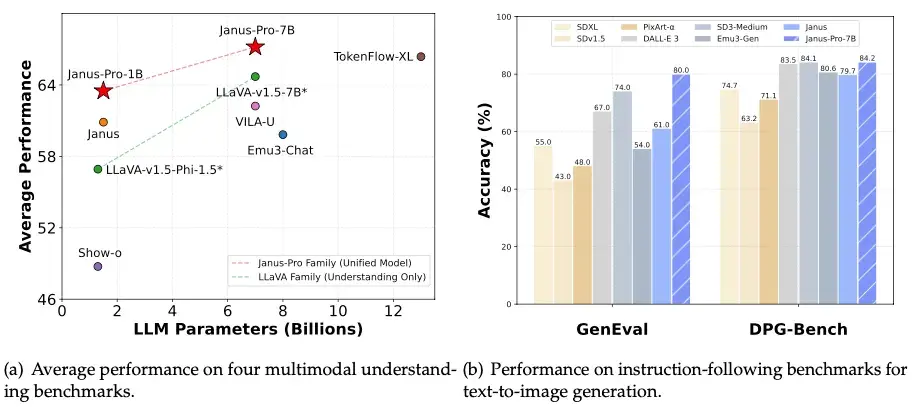
I quajtur Janus Pro , modeli varion nga 1 miliard (jashtëzakonisht i vogël) në 7 miliardë parametra (afër madhësisë së SD 3.5L) dhe është i disponueshëm për shkarkim të menjëhershëm në qendrën e mësimit të makinerive dhe shkencës së të dhënave Huggingface.
Versioni më i madh, Janus Pro 7B, mund jo vetëm DALL-E 3 të OpenAI, por edhe modele të tjera kryesore si PixArt-alpha, Emu3-Gen dhe SDXL në standardet e industrisë GenEval dhe DPG-Bench, sipas informacionit të shpërndarë nga DeepSeek AI.
Publikimi i tij vjen vetëm disa ditë pasi DeepSeek u bë tituj me modelin e tij të gjuhës R1, i cili përputhej me aftësitë e GPT-4 ndërsa kushtoi vetëm 5 milionë dollarë për t’u zhvilluar – duke ndezur një debat të nxehtë rreth gjendjes aktuale të industrisë së AI.
Produkti i startup-it kinez ka shkaktuar gjithashtu shqetësime në të gjithë sektorin se mund të përmbysë operatorët aktualë dhe të rrëzojë trajektoren e rritjes së prodhuesit kryesor të çipave Nvidia, i cili pësoi humbjen më të madhe njëditore të kapitalit të tregut në histori të hënën.
Modeli Janus Pro i DeepSeek përdor atë që kompania e quan një “kornizë e re autoregresive” që shkëput kodimin vizual në shtigje të veçanta duke ruajtur një arkitekturë të vetme transformatori të unifikuar.
Ky dizajn i lejon modelit të analizojë imazhet dhe të gjenerojë imazhe me rezolucion 768×768.
“Janus Pro tejkalon modelin e mëparshëm të unifikuar dhe përputhet ose tejkalon performancën e modeleve specifike për detyra,” pohoi DeepSeek në dokumentacionin e lëshimit të tij. “Thjeshtësia, fleksibiliteti i lartë dhe efektiviteti i Janus Pro e bëjnë atë një kandidat të fortë për modelet multimodale të unifikuara të gjeneratës së ardhshme.”
Ndryshe nga DeepSeek R1, kompania nuk publikoi një letër të plotë të bardhë për modelin, por publikoi dokumentacionin e saj teknik dhe e bëri modelin të disponueshëm për shkarkim të menjëhershëm pa pagesë — duke vazhduar praktikën e saj të lëshimeve me burim të hapur që është në kontrast të fortë me ato të mbyllura. qasje pronësore e gjigantëve të teknologjisë amerikane.
Pra, cili është verdikti ynë? Epo, modeli është shumë i gjithanshëm.
Megjithatë, mos prisni që ai të zëvendësojë ndonjë nga modelet më të specializuara që doni. Mund të gjenerojë tekst, të analizojë imazhe dhe të gjenerojë foto, por kur vihet përballë modeleve që bëjnë mirë vetëm një nga këto gjëra, në rastin më të mirë, është në të njëjtin nivel.
Vini re se nuk ka asnjë mënyrë të menjëhershme për të përdorur UI-të tradicionale për ta ekzekutuar atë – Comfy, A1111, Focus dhe Draw Things nuk janë në përputhje me të për momentin. Kjo do të thotë se është pak jopraktike të ekzekutosh modelin në nivel lokal dhe kërkon kalimin e komandave të tekstit në një terminal.
Megjithatë, disa përdorues të Hugginface kanë krijuar hapësira për të provuar modelin. Hapësira zyrtare e DeepSeek nuk është e disponueshme, prandaj ju rekomandojmë të përdorni hapësirën e lirë të NeuroSenko për të provuar Janus 7b.
Jini të vetëdijshëm për atë që bëni, pasi disa tituj mund të jenë mashtrues. Për shembull, Space e drejtuar nga AP123 thotë se funksionon Janus Pro 7b, por në vend të kësaj ekzekuton Janus Pro 1.5b—i cili mund të përfundojë duke ju bërë të humbni shumë kohë të lirë duke testuar modelin dhe duke marrë rezultate të këqija. Na besoni: ne e dimë sepse na ka ndodhur.
Modeli është i mirë në kuptimin vizual dhe mund të përshkruajë me saktësi elementet në një foto.
Ai tregoi një vetëdije të mirë hapësinore dhe lidhjen midis objekteve të ndryshme.
Është gjithashtu më i saktë se LlaVa – modeli më i popullarizuar i vizionit me burim të hapur – duke qenë në gjendje të ofrojë përshkrime më të sakta të skenave dhe të ndërveprojë me përdoruesin bazuar në kërkesat vizuale.
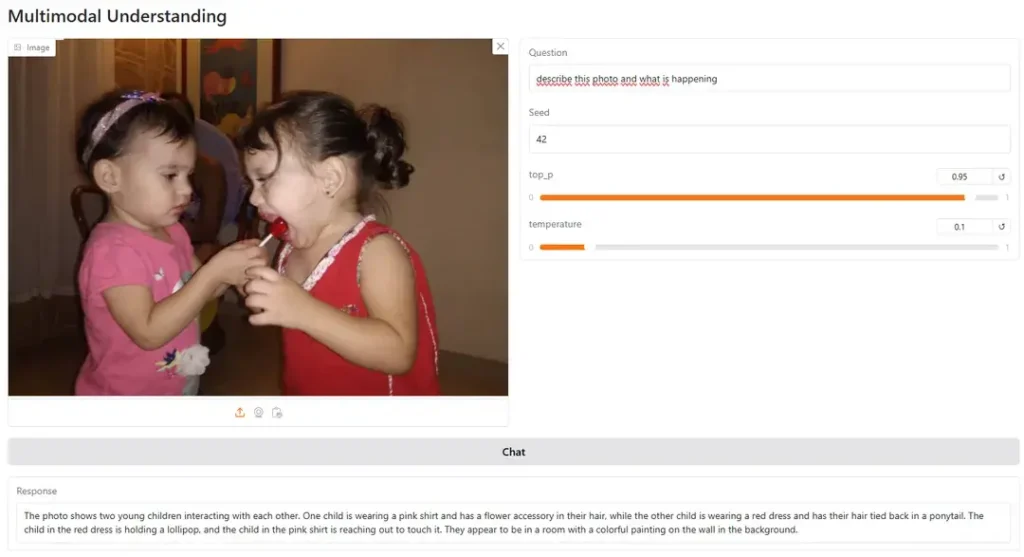
Megjithatë, nuk është akoma më i mirë se GPT Vision, veçanërisht për detyrat që kërkojnë logjikë ose disa analiza përtej asaj që duket qartë në foto. Për shembull, ne i kërkuam modeles të analizonte këtë foto dhe të shpjegonte mesazhin e saj.

Modelja u përgjigj: “Imazhi duket të jetë një karikaturë humoristike që përshkruan një skenë ku një grua lëpin fundin e një gjuhe të gjatë të kuqe që i është ngjitur një djali”.
Ai përfundoi analizën e tij duke thënë se “toni i përgjithshëm i imazhit duket të jetë i lehtë dhe lozonjar, duke sugjeruar ndoshta një skenar ku gruaja është duke u përfshirë në një akt të djallëzuar ose ngacmues”.
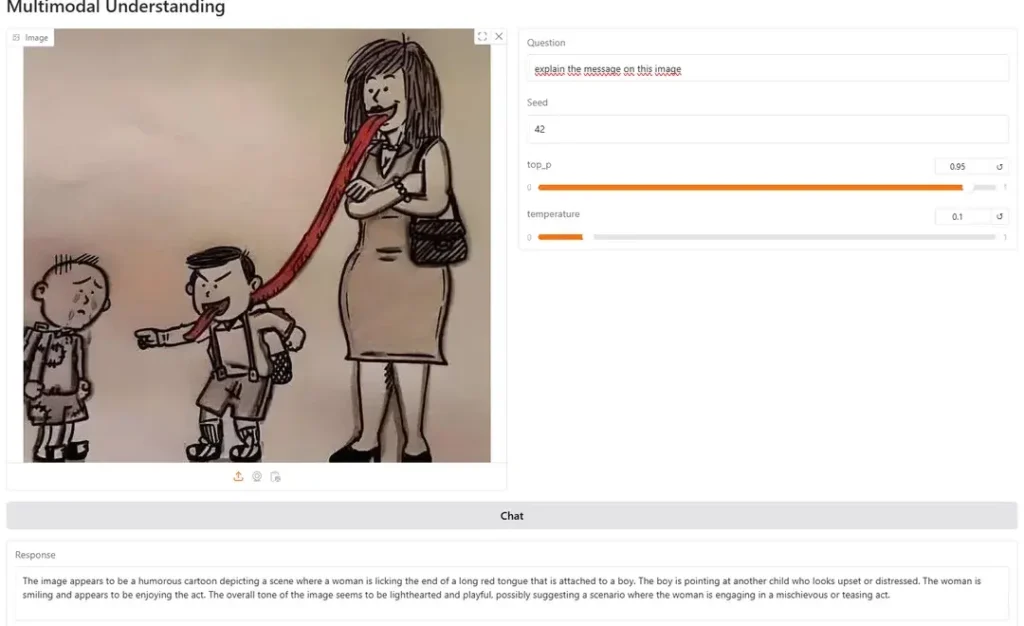
Në këto situata ku kërkohet një arsyetim përtej një përshkrimi të thjeshtë, modeli dështon shumicën e kohës.
Nga ana tjetër, ChatGPT, për shembull, në fakt e kuptoi kuptimin pas imazhit: “Kjo metaforë sugjeron që qëndrimet, fjalët ose vlerat e nënës po ndikojnë drejtpërdrejt në veprimet e fëmijës, veçanërisht në një mënyrë negative si ngacmimi ose diskriminimi.” përfundoi – me saktësi, le të shtojmë.

Gjenerimi i imazhit duket i fuqishëm dhe relativisht i saktë, megjithëse kërkon nxitje të kujdesshme për të arritur rezultate të mira.
DeepSeek pretendon se Janus Pro mund SD 1.5, SDXL dhe Pixart Alpha, por është e rëndësishme të theksohet se ky duhet të jetë një krahasim me modelet bazë, jo të rregulluara mirë.
Me fjalë të tjera, krahasimi i drejtë është midis versioneve më të këqija të modeleve të disponueshme aktualisht, pasi, me siguri, askush nuk përdor një bazë SD 1.5 për gjenerimin e artit kur ka qindra melodi të shkëlqyera të afta për të arritur rezultate që mund të konkurrojnë madje edhe me gjendjen. modelet e artit si Flux ose Stable Diffusion 3.5.
Pra, gjeneratat nuk janë aspak mbresëlënëse për sa i përket cilësisë, por ato duken më të mira se ato që nxirrnin SD1.5 ose SDXL kur u lansuan.
Për shembull, këtu është një krahasim ballë për ballë i imazheve të krijuara nga Janus dhe SDXL për kërkesën: Një dhelpër e lezetshme dhe e adhurueshme foshnje me sy të mëdhenj kafe, gjethe vjeshte në sfond magjepsëse, të pavdekshme, me gëzof, me shkëlqim, petale, zanë, ngjyra shumë të detajuara, fotorealiste, kinematografike, natyrale.

Janus mund SDXL në kuptimin e konceptit thelbësor: ai mund të gjenerojë një foshnjë dhelpër në vend të një dhelpre të pjekur, si në rastin e SDXL.
E kuptoi më mirë edhe stilin fotorealist dhe nuk munguan edhe elementët e tjerë (me gëzof, kinematografik).
Thënë kështu, SDXL gjeneroi një imazh më të qartë pavarësisht se nuk iu përmbajt urdhrit. Cilësia e përgjithshme është më e mirë, sytë janë realistë dhe detajet dallohen më lehtë.
Ky model ishte i qëndrueshëm në gjeneratat e tjera: kuptim i mirë i shpejtë, por ekzekutim i dobët, me imazhe të paqarta që ndihen të vjetruara duke marrë parasysh sa të mirë janë gjeneratorët aktualë të imazheve.
Sidoqoftë, është e rëndësishme të theksohet se Janus është një LLM multimodal i aftë të gjenerojë biseda me tekst, të analizojë imazhe dhe t’i gjenerojë ato gjithashtu. Flux, SDXL dhe modelet e tjera nuk janë krijuar për ato detyra.
Pra, Janus është shumë më i gjithanshëm në thelbin e tij – thjesht jo i shkëlqyeshëm në asgjë kur krahasohet me modelet e specializuara që shkëlqejnë në një detyrë specifike.
Duke qenë me burim të hapur, e ardhmja e Janusit si një lider midis entuziastëve gjenerues të AI do të varet nga një sërë përditësimesh që synojnë të përmirësojnë ato pika.