Modeli i ri Claude 4 i AI-së rifaktorizoi kodin pa ndërprerje për 7 orë rresht

Të enjten, Anthropic publikoi Claude Opus 4 dhe Claude Sonnet 4, duke shënuar rikthimin e kompanisë në lançimet e modeleve më të mëdha, pasi ishte përqendruar kryesisht në variantet e Sonnet të nivelit të mesëm që nga qershori i vitit të kaluar. Modelet e reja përfaqësojnë atë që kompania i quan modelet e saj më të afta të kodimit deri më tani, me Opus 4 të projektuar për detyra komplekse dhe afatgjata që mund të funksionojnë në mënyrë autonome për orë të tëra.
Alex Albert, kreu i Claude Relations në Anthropic, i tha Ars Technica se kompania zgjodhi të ringjallë linjën Opus për shkak të kërkesës në rritje për aplikacione të inteligjencës artificiale agjentike. “Në të gjitha kompanitë që po ndërtojnë gjëra, ka një valë vërtet të madhe të këtyre aplikacioneve agjentike që po shfaqen, dhe një kërkesë dhe vlerësim shumë i lartë po i vihet inteligjencës”, tha Albert. “Mendoj se Opus do t’i përshtatet kësaj rryme në mënyrë të përkryer.”
Para se të vazhdojmë më tej, ndoshta është e nevojshme të bëjmë një rifreskim të shkurtër mbi tre emrat e “madhësive” të modelit të inteligjencës artificiale të Claude ( të prezantuar në mars 2024). Haiku, Sonnet dhe Opus ofrojnë një kompromis midis çmimit (në API), shpejtësisë dhe aftësisë.
Modelet Haiku janë më të voglat, më pak të kushtueshmet për t’u ekzekutuar dhe më pak të aftat për sa i përket asaj që mund ta quani “thellësi konteksti” (duke marrë parasysh marrëdhëniet konceptuale në kërkesë) dhe njohurive të koduara. Për shkak të madhësisë së vogël në numërimin e parametrave, modelet Haiku mbajnë më pak fakte konkrete dhe kështu kanë tendencë të konfabulojnë më shpesh (duke iu përgjigjur pyetjeve bazuar në mungesën e të dhënave) sesa modelet më të mëdha, por ato janë shumë më të shpejta në detyrat themelore sesa modelet më të mëdha. Sonnet është tradicionalisht një model i nivelit të mesëm që arrin një ekuilibër midis kostos dhe aftësisë, dhe modelet Opus kanë qenë gjithmonë më të mëdhatë dhe më të ngadaltat për t’u ekzekutuar. Megjithatë, modelet Opus përpunojnë kontekstin më thellë dhe hipotetikisht janë më të përshtatshme për ekzekutimin e detyrave të thella logjike.
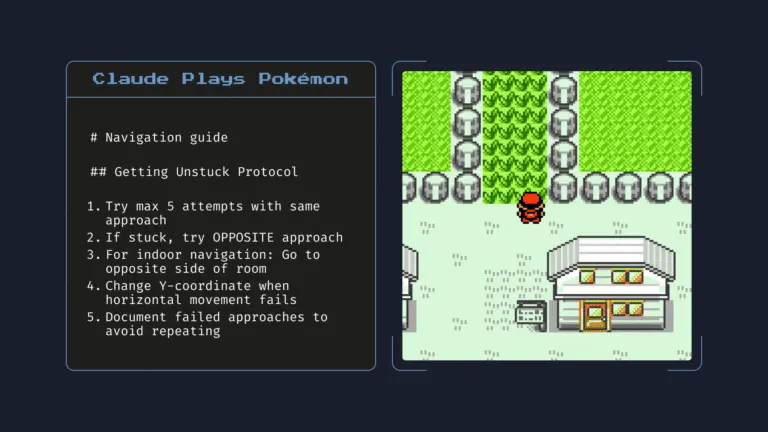
Ende nuk ka Claude 4 Haiku, por modelet e reja Sonnet dhe Opus thuhet se mund të trajtojnë detyra që versionet e mëparshme nuk mund t’i trajtonin. Në intervistën tonë me Albert, ai përshkroi skenarë testimi ku Opus 4 punonte në mënyrë koherente deri në 24 orë në detyra si të luaje Pokémon, ndërsa detyrat e rifaktimit të kodimit në Claude Code funksiononin për shtatë orë pa ndërprerje. Modelet e mëparshme Claude zakonisht zgjasnin vetëm një deri në dy orë para se të humbisnin koherencën, tha Albert, që do të thotë se modelet mund të prodhonin rezultate të dobishme vetë-referuese vetëm për aq kohë para se të fillonin të prodhonin shumë gabime.
Në veçanti, ky pretendim për rifaktorizim maratonë thuhet se vjen nga Rakuten, një konglomerat japonez i shërbimeve teknologjike që “vërtetoi aftësitë e [Claude] me një rifaktorizim kërkues me burim të hapur që funksiononte në mënyrë të pavarur për 7 orë me performancë të qëndrueshme”, tha Anthropic në një njoftim për shtyp.
Nëse do të dëshironit ta linit një model të IA-së pa mbikëqyrje për kaq gjatë është një pyetje krejtësisht tjetër, sepse edhe modelet më të afta të IA-së mund të fusin gabime të vogla, të futen në gropa joproduktive ose të bëjnë zgjedhje që i duken logjike modelit, por që humbasin kontekstin e rëndësishëm që një zhvillues njerëzor do ta kapte. Ndërsa shumë njerëz tani përdorin Claude për kodim të lehtë me vibra, siç e trajtuam në mars, “debugging i vibrave” i mundësuar nga njeriu (dhe i quajtur ironikisht) që shpesh rezulton nga seanca të gjata të kodimit me IA është gjithashtu një gjë shumë reale. Më shumë për këtë më poshtë.
Për të kompensuar disa nga këto mangësi, Anthropic ndërtoi aftësi memorieje në të dy modelet e reja Claude 4, duke u lejuar atyre të ruajnë skedarë të jashtëm për ruajtjen e informacionit kyç gjatë seancave të gjata. Kur zhvilluesit ofrojnë qasje në skedarët lokalë, modelet mund të krijojnë dhe përditësojnë “skedarë memorieje” për të ndjekur progresin dhe gjërat që i konsiderojnë të rëndësishme me kalimin e kohës. Albert e krahasoi këtë me mënyrën se si njerëzit mbajnë shënime gjatë seancave të zgjatura të punës.
Të dy modelet Claude 4 prezantojnë atë që Anthropic e quan “të menduarit e zgjeruar me përdorimin e mjeteve”, një veçori e re beta që u lejon modeleve të alternojnë midis arsyetimit të simuluar dhe përdorimit të mjeteve të jashtme si kërkimi në internet, ngjashëm me atë që modelet o3 dhe 04-mini-high AI të OpenAI bëjnë aktualisht në ChatGPT. Ndërsa Claude 3.7 Sonnet tashmë kishte aftësi të forta përdorimi të mjeteve, modelet e reja tani mund të ndërthurin arsyetimin e simuluar dhe thirrjen e mjeteve në një përgjigje të vetme.
“Pra, tani ne mund të mendojmë, të thërrasim një mjet për procesin, rezultatet, të mendojmë edhe pak, të thërrasim një mjet tjetër dhe të përsërisim derisa të arrijmë në një përgjigje përfundimtare”, i shpjegoi Albert Ars-it. Modelet vetëpërcaktojnë kur kanë arritur në një përfundim të dobishëm, një aftësi e fituar përmes trajnimit në vend që të qeveriset nga programimi i qartë njerëzor.
Në praktikë, ne kemi gjetur anekdotike se aftësia e përdorimit paralel të mjeteve është shumë e dobishme në asistentët e IA-së si OpenAI o3, pasi ata nuk duhet të mbështeten në atë që është trajnuar në rrjetin e tyre nervor për të ofruar përgjigje të sakta. Në vend të kësaj, këto modele më agjentike mund të kërkojnë në mënyrë iterative në internet, të analizojnë rezultatet, të analizojnë imazhet dhe të krijojnë detyra kodimi për analizë në mënyra që mund të shmangin rënien në një kurth konfabulacioni duke u mbështetur vetëm në rezultatet e pastra të LLM-së.
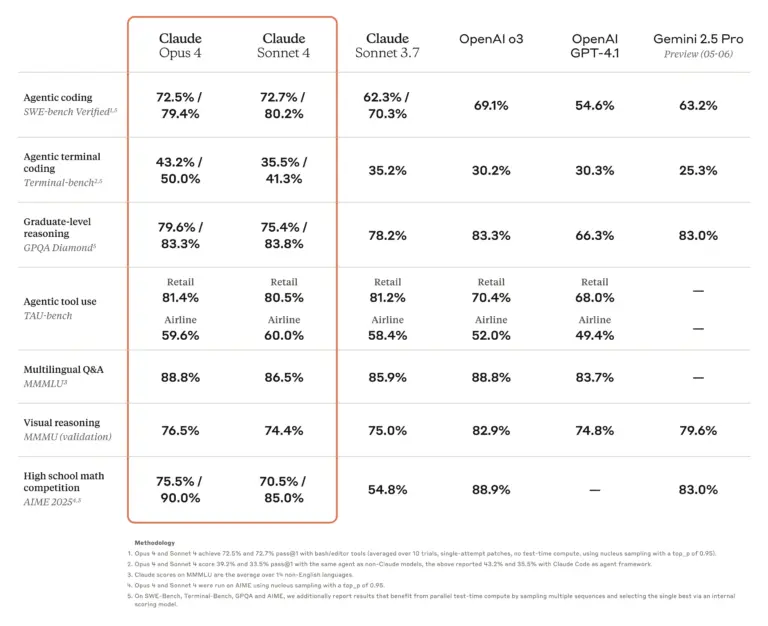
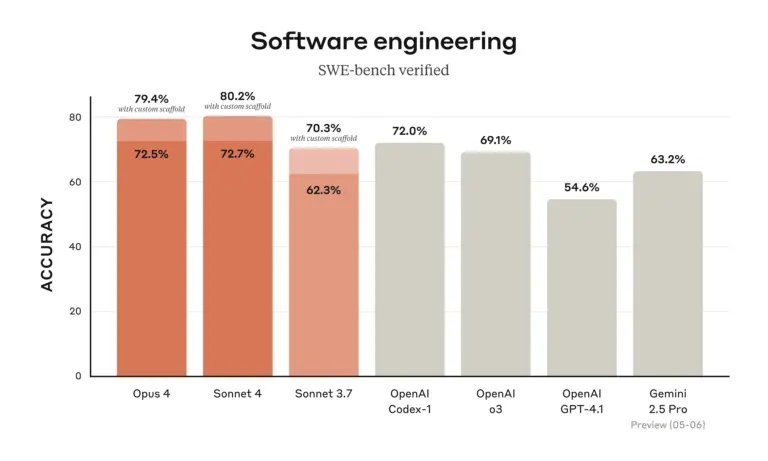
Anthropic thotë se Opus 4 kryeson standardet e industrisë për detyrat e kodimit, duke arritur 72.5 përqind në SWE-bench dhe 43.2 përqind në Terminal-bench , duke e quajtur atë “modeli më i mirë i kodimit në botë”. Sipas Anthropic, kompanitë që përdorin versionet e hershme raportojnë përmirësime. Cursor e përshkroi atë si “më të përparuar për kodimin dhe një hap përpara në kuptimin e bazës komplekse të kodit”, ndërsa Replit vuri në dukje “saktësi të përmirësuar dhe përparime dramatike për ndryshime komplekse në skedarë të shumtë”.
Në fakt, GitHub njoftoi se do të përdorë Sonnet 4 si modelin bazë për agjentin e saj të ri të kodimit në GitHub Copilot, duke përmendur performancën e modelit në “skenarët agjentë” në njoftimin për shtyp të Anthropic. Sonnet 4 shënoi 72.7 përqind në SWE-bench duke ruajtur kohë reagimi më të shpejta se Opus 4. Fakti që GitHub po vë bast te Claude në vend të një modeli nga kompania e saj mëmë Microsoft (e cila ka lidhje të ngushta me OpenAI) sugjeron që Anthropic ka ndërtuar diçka vërtet konkurruese.
Anthropic thotë se ka adresuar një problem të vazhdueshëm me Claude 3.7 Sonnet, në të cilin përdoruesit ankoheshin se modeli do të kryente veprime të paautorizuara ose do të ofronte rezultate të tepërta. Albert tha se kompania e uli këtë “sjellje të hakimit të shpërblimeve” me afërsisht 80 përqind në modelet e reja përmes rregullimeve të trajnimit. Një ulje prej 80 përqind e sjelljes së padëshiruar duket mbresëlënëse, por kjo gjithashtu sugjeron se 20 përqind e sjelljes problematike mbetet – një shqetësim i madh kur flasim për modele të IA-së që mund të kryejnë detyra autonome për orë të tëra.
Kur e pyetëm për saktësinë e kodit, Albert tha se rishikimi i kodit nga njeriu është ende një pjesë e rëndësishme e transportimit të çdo kodi prodhimi. “Ekziston një paralele njerëzore, apo jo? Pra, ky është thjesht një problem me të cilin kemi pasur të merremi në të gjithë natyrën e inxhinierisë së softuerëve. Dhe kjo është arsyeja pse ekziston procesi i rishikimit të kodit, në mënyrë që të mund t’i kapni këto gjëra. Ne nuk parashikojmë që kjo të zhduket me modelet”, tha Albert. “Nëse ka ndonjë gjë, rishikimi nga njeriu do të bëhet më i rëndësishëm dhe më shumë nga puna juaj si zhvillues do të jetë në këtë rishikim sesa në pjesën e gjenerimit.”
Të dy modelet Claude 4 ruajnë të njëjtën strukturë çmimesh si paraardhësit e tyre: Opus 4 kushton 15 dollarë për milion tokena për hyrje dhe 75 dollarë për milion për dalje, ndërsa Sonnet 4 mbetet në 3 dollarë dhe 15 dollarë. Modelet ofrojnë dy mënyra përgjigjeje: LLM tradicionale dhe arsyetim të simuluar (“të menduarit e zgjeruar”) për probleme komplekse. Duke pasur parasysh se disa seanca të Claude Code me sa duket mund të zgjasin me orë të tëra, ato kosto për token ka të ngjarë të shtohen shumë shpejt për përdoruesit që i lënë modelet të funksionojnë pa masë.
Anthropic i bëri të dy modelet të disponueshme përmes API-t të saj, Amazon Bedrock dhe Google Cloud Vertex AI. Sonnet 4 mbetet i arritshëm për përdoruesit falas, ndërsa Opus 4 kërkon një abonim me pagesë.
Modelet Claude 4 gjithashtu prezantojnë Claude Code ( prezantuar në shkurt) si një produkt të disponueshëm gjerësisht pas muajsh testimesh paraprake. Anthropic thotë se mjedisi i kodimit tani integrohet me IDE-të e VS Code dhe JetBrains, duke shfaqur ndryshimet e propozuara direkt në skedarë. Një SDK i ri u lejon zhvilluesve të ndërtojnë agjentë të personalizuar duke përdorur të njëjtin kuadër.
Edhe pse e ardhmja e Anthropic varet nga aftësitë e këtyre modeleve të reja, kur e pyetëm se si ato e orientojnë sjelljen e Claude-it duke i përshtatur ato me imtësi, Albert pranoi se paparashikueshmëria e natyrshme e këtyre sistemeve paraqet sfida të vazhdueshme si për ta ashtu edhe për zhvilluesit. “Në sferën dhe botën e softuerëve për 40, 50 vitet e fundit, ne kemi përdorur sisteme deterministe, dhe tani papritmas, kjo është bërë jo-deterministe, dhe kjo ndryshon mënyrën se si ndërtojmë”, tha ai.
“Unë kuptoj shumë njerëz që përpiqen të përdorin API-të dhe modelet tona gjuhësore në përgjithësi, sepse atyre u duhet pothuajse të ndryshojnë perspektivën e tyre mbi atë që do të thotë kjo për besueshmërinë, çfarë do të thotë kjo për fuqizimin e një bërthame të aplikacionit tuaj në një mënyrë jo-deterministe”, shtoi Albert. “Këto janë çuditshmëri të përgjithshme që sapo janë përmbysur dhe padyshim që i bëjnë gjërat më të vështira, por mendoj se hap edhe shumë mundësi.”