Alibaba Cloud lëshon modelin e ri të AI Qwen2-VL që mund të analizojë video më shumë se 20 minuta

Alibaba Cloud, ndarja e shërbimeve cloud dhe ruajtjes së gjigantit kinez të tregtisë elektronike, ka njoftuar lëshimin e Qwen2-VL, modelin e tij më të fundit të avancuar të gjuhës së vizionit, i krijuar për të përmirësuar kuptimin vizual, të kuptuarit e videos dhe përpunimin shumëgjuhësh të imazhit të tekstit.
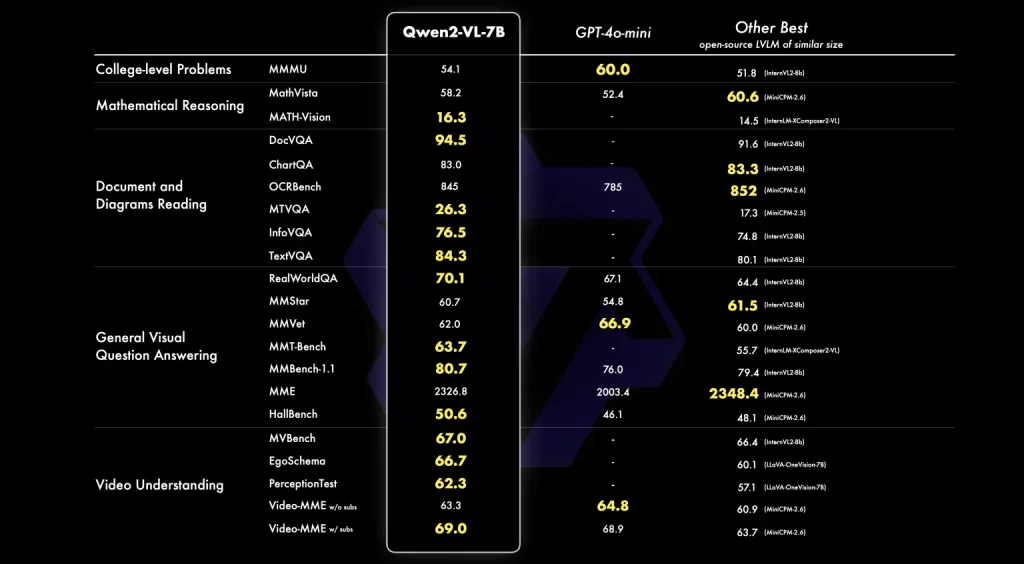
Dhe tashmë, ai krenohet me performancë mbresëlënëse në testet e standardeve të palëve të treta në krahasim me modelet e tjera më të avancuara si Llama 3.1 e Meta, GPT-4o e OpenAI, Claude 3 Haiku e Anthropic dhe Gemini-1.5 Flash e Google. Mund të provoni një konkluzion të tij të organizuar këtu në Hugging Face.
Gjuhët e mbështetura përfshijnë anglisht, kinezisht, shumicën e gjuhëve evropiane, japoneze, koreane, arabisht dhe vietnameze.
Me Qwen-2VL-në e re, Alibaba po kërkon të vendosë standarde të reja për ndërveprimin e modeleve të AI me të dhënat vizuale, duke përfshirë aftësinë për të analizuar dhe dalluar shkrimin e dorës në shumë gjuhë, për të identifikuar, përshkruar dhe dalluar midis objekteve të shumta në imazhe statike, madje edhe për të analizuar. video live në kohë pothuajse reale, duke ofruar përmbledhje ose komente që mund të hapin derën për t’u përdorur për mbështetje teknike dhe operacione të tjera të dobishme drejtpërdrejt.
Siç shkruan ekipi hulumtues Qwen në një postim në blog në GitHub në lidhje me familjen e re të modeleve Qwen2-VL: “Përtej imazheve statike, Qwen2-VL zgjeron aftësinë e tij në analizën e përmbajtjes së videos. Mund të përmbledhë përmbajtjen e videos, t’u përgjigjet pyetjeve në lidhje me të dhe të mbajë një rrjedhë të vazhdueshme bisedash në kohë reale, duke ofruar mbështetje për bisedat e drejtpërdrejta. Ky funksionalitet e lejon atë të veprojë si një asistent personal, duke ndihmuar përdoruesit duke ofruar njohuri dhe informacione të nxjerra drejtpërdrejt nga përmbajtja e videos.
Përveç kësaj, Alibaba krenohet se mund të analizojë video më të gjata se 20 minuta dhe t’u përgjigjet pyetjeve në lidhje me përmbajtjen.
Alibaba madje tregoi një shembull të modelit të ri duke analizuar dhe përshkruar saktë videon e mëposhtme:
Këtu është përmbledhja e Qwen-2VL:
Videoja fillon me një burrë që flet para kamerës, i ndjekur nga një grup njerëzish të ulur në një dhomë kontrolli. Kamera më pas pret dy burra që notojnë brenda një stacioni hapësinor, ku ata shihen duke folur me kamerën. Burrat duket se janë astronautë dhe kanë veshur kostume hapësinore. Stacioni hapësinor është i mbushur me pajisje dhe makineri të ndryshme, dhe kamera rrotullohet për të treguar zonat e ndryshme të stacionit. Burrat vazhdojnë të flasin para kamerës dhe duket se po diskutojnë misionin e tyre dhe detyrat e ndryshme që po kryejnë. Në përgjithësi, video ofron një pamje magjepsëse në botën e eksplorimit të hapësirës dhe jetën e përditshme të astronautëve.
Modeli i ri i Alibaba vjen në tre variante të madhësive të ndryshme të parametrave – Qwen2-VL-72B (72 miliardë parametra), Qwen2-VL-7B dhe Qwen2-VL-2B. (Një kujtesë se parametrat përshkruajnë cilësimet e brendshme të një modeli, me më shumë parametra që përgjithësisht nënkuptojnë një model më të fuqishëm dhe më të aftë.)
Variantet 7B dhe 2B janë të disponueshme me licenca Apache 2.0 me burim të hapur, duke i lejuar ndërmarrjet t’i përdorin ato sipas dëshirës për qëllime komerciale, duke i bërë ato tërheqëse si opsione për vendimmarrësit e mundshëm. Ato janë krijuar për të ofruar performancë konkurruese në një shkallë më të aksesueshme dhe janë të disponueshme në platforma si Hugging Face dhe ModelScope.
Megjithatë, modeli më i madh 72B ende nuk është publikuar publikisht dhe do të vihet në dispozicion vetëm më vonë përmes një licence të veçantë dhe ndërfaqes së programimit të aplikacionit (API) nga Alibaba.
Seria Qwen2-VL është ndërtuar mbi bazën e familjes së modeleve Qwen, duke sjellë përparime të rëndësishme në disa fusha kryesore:
Modelet mund të integrohen në pajisje të tilla si telefonat celularë dhe robotët, duke lejuar operacione të automatizuara bazuar në mjedise vizuale dhe udhëzime me tekst.
Kjo veçori nxjerr në pah potencialin e Qwen2-VL si një mjet i fuqishëm për detyra që kërkojnë arsyetim dhe vendimmarrje komplekse.
Për më tepër, Qwen2-VL mbështet thirrjet funksionale — duke u integruar me softuer, aplikacione dhe mjete të tjera të palëve të treta — dhe nxjerrjen vizuale të informacionit nga këto burime informacioni të palëve të treta. Me fjalë të tjera, modeli mund të shikojë dhe kuptojë “statuset e fluturimit, parashikimet e motit ose gjurmimin e paketave”, të cilat Alibaba thotë se e bën atë të aftë “të lehtësojë ndërveprime të ngjashme me perceptimet njerëzore për botën”.
Qwen2-VL prezanton disa përmirësime arkitekturore që synojnë rritjen e aftësisë së modelit për të përpunuar dhe kuptuar të dhënat vizuale.
Mbështetja Naive Dynamic Resolution i lejon modelet të trajtojnë imazhe me rezolucione të ndryshme, duke siguruar qëndrueshmëri dhe saktësi në interpretimin vizual. Për më tepër, sistemi Multimodal Rotary Position Embedding (M-ROPE) u mundëson modeleve të kapin dhe integrojnë njëkohësisht informacionin pozicional nëpër tekst, imazhe dhe video.
Ekipi Qwen i Alibaba-s është i përkushtuar të avancojë më tej aftësitë e modeleve të gjuhës së vizionit, duke u mbështetur në suksesin e Qwen2-VL me planet për të integruar modalitete shtesë dhe për të përmirësuar dobinë e modeleve në një gamë më të gjerë aplikacionesh.
Modelet Qwen2-VL tani janë të disponueshme për përdorim dhe Ekipi Qwen inkurajon zhvilluesit dhe studiuesit të eksplorojnë potencialin e këtyre mjeteve të fundit.