Apple tregon aftësinë e hapur të AI modelet e reja i tejkalojnë ofertat Mistral dhe Hugging Face

Ndërsa bota vazhdon të lulëzojë mbi aftësitë e GPT-4o-mini krejtësisht të re, Apple ka zgjedhur të zgjerojë familjen e saj të modeleve të vogla. Pak orë më parë, ekipi hulumtues në Apple që punon si pjesë e projektit DataComp for Language Models, publikoi një familje modelesh të hapura DCLM në Hugging Face.

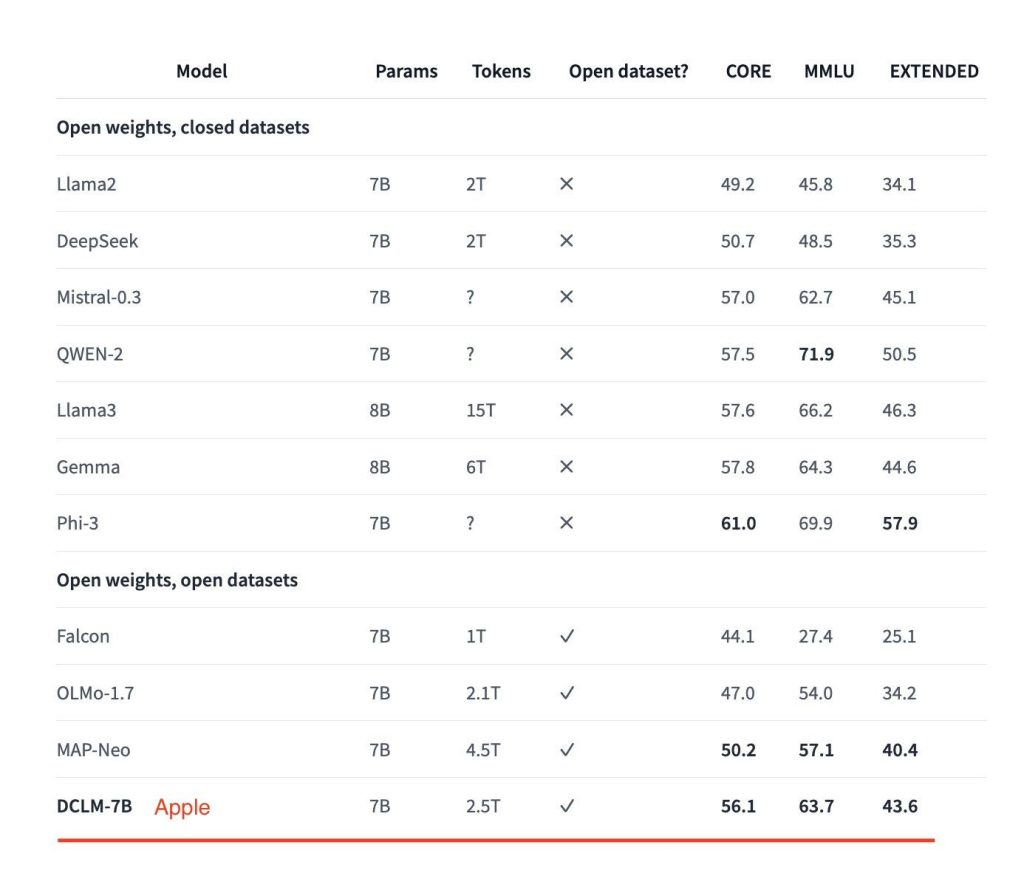
Paketa përfshin dy modele kryesore në thelb: një me 7 miliardë parametra dhe tjetri me 1.4 miliardë parametra. Ata të dy performojnë mjaft mirë në standardet, veçanërisht atë më të madhin – i cili ka tejkaluar Mistral-7B dhe po afrohet me modelet e tjera kryesore të hapura, duke përfshirë Llama 3 dhe Gemma.
Vaishaal Shankar nga ekipi i Apple ML i përshkroi këto si modelet me burim të hapur “me performancën më të mirë” atje. Diçka që vlen të përmendet është se projekti është bërë me burim të vërtetë të hapur me lëshimin e peshave të modelit, kodit të trajnimit dhe grupit të të dhënave para-trajnuese.
I udhëhequr nga një ekip studiuesish multidisiplinar, duke përfshirë ata në Apple, Universiteti i Uashingtonit, Universiteti i Tel Avivit dhe Instituti i Kërkimeve Toyota, projekti DataComp mund të përshkruhet si një përpjekje bashkëpunuese për të hartuar grupe të dhënash me cilësi të lartë për trajnimin e modeleve të AI, veçanërisht në domeni multimodal. Ideja është shumë e thjeshtë këtu: përdorni një kornizë të standardizuar – me arkitektura modelesh fikse, kod trajnimi, hiperparametra dhe vlerësime – për të kryer eksperimente të ndryshme dhe për të kuptuar se cila strategji e kurimit të të dhënave funksionon më mirë për trajnimin e një modeli me performancë të lartë.
Puna në projekt filloi pak kohë më parë dhe eksperimentet e çuan ekipin të kuptonte se filtrimi i bazuar në model, ku modelet e mësimit të makinerive (ML) filtrojnë automatikisht dhe zgjedhin të dhëna me cilësi të lartë nga grupe të dhënash më të mëdha, mund të jetë çelësi për montimin e një niveli të lartë. – set trajnimi cilësor. Për të demonstruar efektivitetin e teknikës së kurimit, grupi i të dhënave që rezultoi, DCLM-Baseline, u përdor për të trajnuar modelet e reja në gjuhën angleze të transformatorëve vetëm me dekoder DCLM me 7 miliardë e 1.4 miliardë parametra nga e para.
Modeli 7B, i trajnuar në 2.5 trilion argumente duke përdorur receta para-trajnimi bazuar në kornizën OpenLM, vjen me një dritare konteksti 2K dhe jep 63,7% saktësi me 5 shkrepje në MMLU. Sipas studiuesve, kjo përfaqëson një përmirësim prej 6.6 pikë përqindjeje në krahasim me MAP-Neo – teknologjia e mëparshme më e fundit në kategorinë e modelit të gjuhës së të dhënave të hapura – duke përdorur 40% më pak llogaritje për trajnim.
Më e rëndësishmja, performanca e tij MMLU është shumë afër me atë të modeleve kryesore të hapura – pesha të hapura por të dhëna të mbyllura – në treg, duke përfshirë Mistral-7B-v0.3 (62.7%), Llama3 8B (66.2%), Gemma të Google (64.3 %) dhe Phi-3 i Microsoft (69.9%).
Performanca e modelit në standardet Core dhe Extended (mesatarja e dhjetëra detyrave të ndryshme, duke përfshirë HellaSwag dhe ARC-E) pa përmirësime të mëtejshme kur studiuesit zgjeruan gjatësinë e kontekstit në 8K duke bërë një trajnim shtesë 100B në të njëjtin grup të dhënash, duke përdorur grupin e të dhënave Teknika e zbërthimit. Rezultati i MMLU, megjithatë, mbeti i pandryshuar.
“Rezultatet tona theksojnë rëndësinë e dizajnit të të dhënave për modelet e trajnimit të gjuhës dhe ofrojnë një pikënisje për kërkime të mëtejshme mbi kurimin e të dhënave,” vunë në dukje studiuesit në një punim që detajon punën në DataComp-LM.
Ashtu si DCLM-7B, versioni më i vogël 1.4B i modelit, i trajnuar së bashku me Toyota Research Insitute në 2.6 trilion argumente, gjithashtu jep performancë mbresëlënëse në testet MMLU, Core dhe Extended.
Në testin MMLU me 5 goditje, ai shënoi 41.9%, që është dukshëm më i lartë se modelet e tjera në kategori, duke përfshirë SmolLM të lëshuar së fundmi nga Hugging Face. Sipas standardeve, versioni 1.7B i SmolLM ka një rezultat MMLU prej 39.97%. Ndërkohë, Qwen-1.5B dhe Phi-1.5B gjithashtu pasojnë me rezultate përkatësisht 37.87% dhe 35.90%.
Aktualisht, modeli më i madh është i disponueshëm nën licencën e kodit të mostrës së Apple, ndërsa ai më i vogël është lëshuar nën Apache 2.0, duke lejuar përdorim komercial, shpërndarje dhe modifikim. Veçanërisht, ekziston gjithashtu një version i akorduar me udhëzim të modelit të parametrave 7B në bibliotekën HF.
Është gjithashtu e rëndësishme të theksohet këtu se ky është vetëm një hulumtim i hershëm, duke theksuar efektivitetin e kurimit të të dhënave. Modelet nuk janë për pajisjet Apple dhe mund të shfaqin paragjykime të caktuara nga të dhënat e trajnimit të testimit ose të prodhojnë përgjigje të dëmshme.