Botët e AI tani mundën 100% të atyre CAPTCHA-ve të imazhit të trafikut
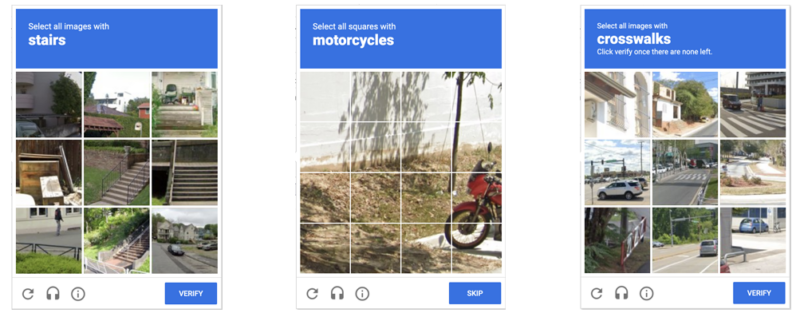
Kushdo që ka shfletuar në internet për një kohë, ndoshta është mësuar të klikojë përmes një rrjeti CAPTCHA të imazheve të rrugëve, duke identifikuar objektet e përditshme për të provuar se ata janë një njeri dhe jo një bot i automatizuar. Megjithatë, tani, hulumtimi i ri pohon se bot-et e drejtuara në nivel lokal duke përdorur modele të trajnuara posaçërisht për njohjen e imazhit mund të përputhen me performancën e nivelit njerëzor në këtë stil të CAPTCHA, duke arritur një shkallë suksesi 100 për qind pavarësisht se janë të paqartë që nuk janë njerëz.
Studenti i doktoraturës në ETH Cyrih, Andreas Plesner dhe kërkimi i ri i kolegëve të tij, i disponueshëm si një letër para printimi, fokusohet në ReCAPTCHA v2 të Google, i cili sfidon përdoruesit të identifikojnë se cilat imazhe rrugësh në një rrjet përmbajnë artikuj si biçikletat, vendkalimet, malet, shkallët ose semaforët. Google filloi ta heqë atë sistem vite më parë në favor të një re CAPTCHA v3 “të padukshme” që analizon ndërveprimet e përdoruesve në vend që të ofronte një sfidë të qartë.
Pavarësisht kësaj, reCAPTCHA v2 më i vjetër ende përdoret nga miliona faqe interneti. Dhe madje edhe sajtet që përdorin reCAPTCHA v3 të përditësuar ndonjëherë do të përdorin reCAPTCHA v2 si një rikthim kur sistemi i përditësuar i jep një përdoruesi një vlerësim të ulët të besimit “njerëzor”.
Për të krijuar një robot që mund të mposhtte reCAPTCHA v2, studiuesit përdorën një version të akorduar të modelit me burim të hapur YOLO (“Ju vetëm shikoni një herë”) për njohjen e objektit, i cili lexuesit prej kohësh mund të kujtojnë se është përdorur gjithashtu në lojëra video mashtrojnë bots. Studiuesit thonë se modeli YOLO është “i njohur për aftësinë e tij për të zbuluar objekte në kohë reale” dhe “mund të përdoret në pajisje me fuqi të kufizuar llogaritëse, duke lejuar sulme në shkallë të gjerë nga përdoruesit me qëllim të keq”.
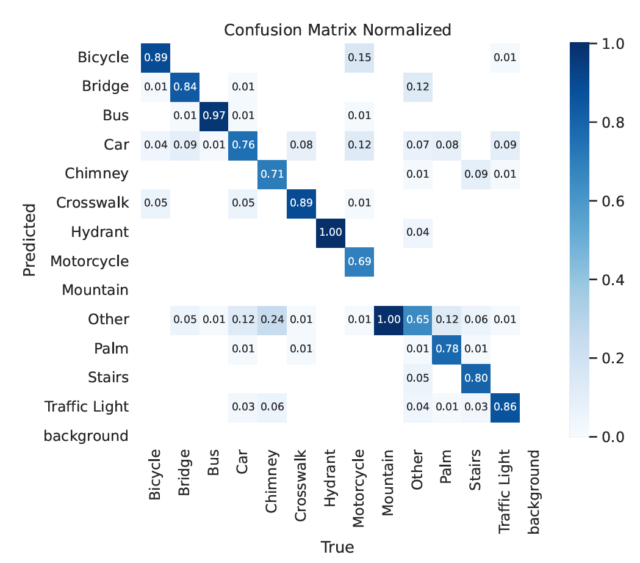
Pas trajnimit të modelit në 14,000 imazhe të etiketuara të trafikut, studiuesit patën një sistem që mund të identifikonte probabilitetin që çdo imazh i rrjetit i ofruar CAPTCHA t’i përkiste një prej 13 kategorive kandidate të reCAPTCHA v2. Studiuesit përdorën gjithashtu një model të veçantë, të trajnuar paraprakisht YOLO për ato që i quajtën sfidat “tipi 2”, ku një CAPTCHA u kërkon përdoruesve të identifikojnë se cilat pjesë të një imazhi të vetëm të segmentuar përmbajnë një lloj të caktuar objekti (ky model segmentimi ka punuar vetëm në nëntë nga 13 kategori objektesh dhe thjesht kërkoi një imazh të ri kur u paraqit me katër kategoritë e tjera).
Përtej modelit të njohjes së imazhit, studiuesit duhej të ndërmerrnin edhe hapa të tjerë për të mashtruar sistemin e reCAPTCHA. Një VPN u përdor për të shmangur zbulimin e përpjekjeve të përsëritura nga e njëjta adresë IP, për shembull, ndërsa një model i veçantë i lëvizjes së miut u krijua për të përafruar aktivitetin njerëzor. Informacioni i rremë i shfletuesit dhe cookie-t nga seancat reale të shfletimit të internetit u përdorën gjithashtu për ta bërë agjentin e automatizuar të duket më njerëzor.
Në varësi të llojit të objektit që identifikohej, modeli YOLO ishte në gjendje të identifikonte me saktësi imazhet individuale CAPTCHA diku nga 69 përqind të rasteve (për motoçikletat) deri në 100 përqind të kohës (për hidrantët e zjarrit). Ajo performancë – e kombinuar me masat e tjera paraprake – ishte mjaft e fortë për të kaluar përmes rrjetit CAPTCHA çdo herë, ndonjëherë pas sfidave të shumta individuale të paraqitura nga sistemi. Në fakt, roboti ishte në gjendje të zgjidhte mesataren CAPTCHA në pak më pak sfida sesa një njeri në prova të ngjashme (megjithëse përmirësimi ndaj njerëzve nuk ishte statistikisht i rëndësishëm).
Ndërsa ka pasur studime të mëparshme akademike që përpiqeshin të përdornin modele të njohjes së imazhit për të zgjidhur reCAPTCHA-të, ato ishin në gjendje të kishin sukses vetëm midis 68 dhe 71 për qind të rasteve. Rritja në një shkallë suksesi 100 për qind “tregon se tani jemi zyrtarisht në epokën përtej captchas”, sipas autorëve të gazetës së re.
Por ky nuk është një problem krejtësisht i ri në botën e CAPTCHA-ve. Që në vitin 2008, studiuesit po tregonin se si robotët mund të trajnohen për të depërtuar në CAPTCHA audio të destinuara për përdoruesit me dëmtim të shikimit. Dhe deri në vitin 2017, rrjetet neurale po përdoreshin për të mposhtur CAPTCHA-të e bazuara në tekst që u kërkonin përdoruesve të shkruanin shkronjat që shiheshin në fontet e ngatërruara.
Tani që AI-të e drejtuara në nivel lokal mund të kenë lehtësisht edhe CAPTCHA-të e bazuara në imazhe, beteja e identifikimit njerëzor do të vazhdojë të zhvendoset drejt metodave më delikate të marrjes së gjurmëve të gishtave të pajisjes. “Ne kemi një fokus shumë të madh për të ndihmuar klientët tanë të mbrojnë përdoruesit e tyre pa shfaqur sfida vizuale, kjo është arsyeja pse ne lançuam reCAPTCHA v3 në 2018,” tha një zëdhënës i Google Cloud për New Scientist. “Sot, shumica e mbrojtjeve të reCAPTCHA në 7 [milion] sajte globalisht tani janë plotësisht të padukshme. Ne po përmirësojmë vazhdimisht reCAPTCHA.”
Megjithatë, ndërsa sistemet e inteligjencës artificiale bëhen gjithnjë e më të mira për të imituar gjithnjë e më shumë detyra që më parë konsideroheshin ekskluzivisht njerëzore, mund të vazhdojë të bëhet gjithnjë e më e vështirë të sigurohet që përdoruesi në anën tjetër të atij shfletuesi të internetit është në të vërtetë një person.
“Në një farë kuptimi, një captcha e mirë shënon kufirin e saktë midis makinës më inteligjente dhe njeriut më pak inteligjent,” shkruajnë autorët e gazetës. “Ndërsa modelet e mësimit të makinerive afrohen me aftësitë njerëzore, gjetja e kapçave të mira është bërë më e vështirë.”