Burime të brendshme thonë se DeepSeek V4 do të mundë Claude dhe ChatGPT në kodim dhe do të lançohet brenda javësh

DeepSeek thuhet se planifikon të lançojë modelin e saj V4 rreth mesit të shkurtit, dhe nëse testet e brendshme janë ndonjë tregues, gjigantët e inteligjencës artificiale të Silicon Valley duhet të jenë nervozë.
Startupi i inteligjencës artificiale me seli në Hangzhou mund të synojë një lançim rreth 17 shkurtit – Vitit të Ri Hënor, natyrisht – me një model të projektuar posaçërisht për detyra kodimi, sipas The Information. Njerëzit me njohuri të drejtpërdrejta të projektit pretendojnë se V4 i tejkalon seritë Claude të Anthropic dhe GPT të OpenAI në testet e brendshme, veçanërisht kur trajtohen kërkesa jashtëzakonisht të gjata për kod.
Sigurisht, asnjë pikë referimi ose informacion në lidhje me modelin nuk është ndarë publikisht, kështu që është e pamundur të verifikohen drejtpërdrejt pretendime të tilla. DeepSeek gjithashtu nuk i ka konfirmuar thashethemet.
Megjithatë, komuniteti i zhvilluesve nuk po pret për ndonjë lajm zyrtar. r/DeepSeek dhe r/LocalLLaMA i Reddit tashmë po nxehen, përdoruesit po grumbullojnë kredite API dhe entuziastët e X kanë nxituar të ndajnë parashikimet e tyre se V4 mund të çimentojë pozicionin e DeepSeek si autsajderi i guximshëm që refuzon të luajë sipas rregullave miliarda dollarëshe të Silicon Valley.
Kjo nuk do të ishte ndërprerja e parë e DeepSeek. Kur kompania publikoi modelin e saj të arsyetimit R1 në janar 2025, kjo shkaktoi një shitje prej 1 trilion dollarësh në tregjet globale.
Arsyeja? R1 i DeepSeek përputhej me modelin o1 të OpenAI në testet e matematikës dhe arsyetimit, pavarësisht se thuhet se kushtoi vetëm 6 milionë dollarë për t’u zhvilluar – afërsisht 68 herë më lirë se sa shpenzonin konkurrentët. Modeli i tij V3 më vonë arriti 90.2% në testin e MATH-500, duke tejkaluar 78.3% të Claude dhe përditësimi i fundit ” V3.2 Speciale ” e përmirësoi performancën e tij edhe më shumë.
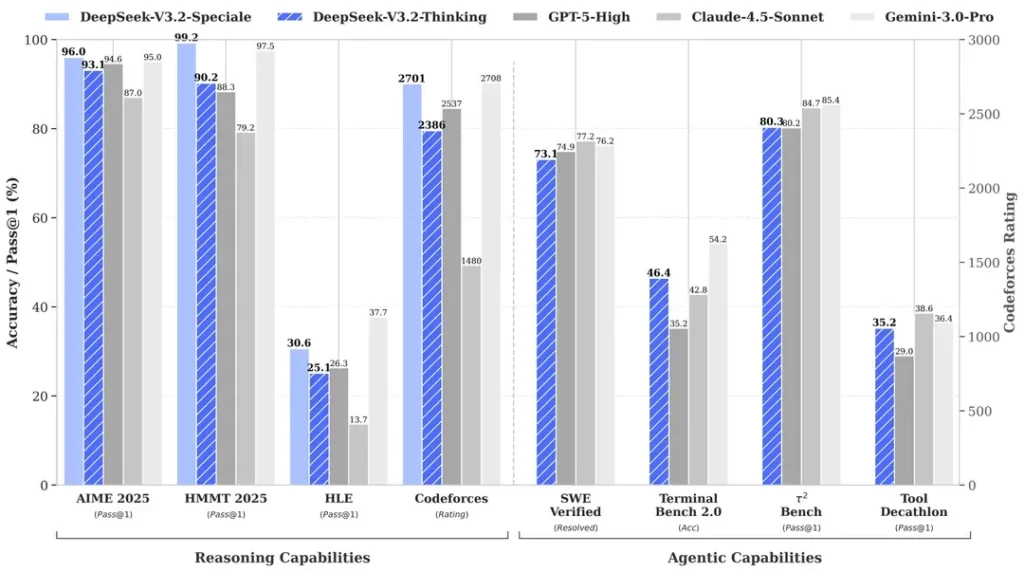
Fokusi i kodimit të V4 do të ishte një pikë kthese strategjike. Ndërsa R1 theksonte arsyetimin e pastër – logjikën, matematikën, provat formale – V4 është një model hibrid (detyra arsyetimi dhe jo-arsyetimi) që synon tregun e zhvilluesve të ndërmarrjeve ku gjenerimi i kodit me saktësi të lartë përkthehet drejtpërdrejt në të ardhura.
Për të pretenduar dominim, V4 do të duhej të mposhtte Claude Opus 4.5, i cili aktualisht mban rekordin e verifikuar të SWE-bench me 80.9%. Por nëse lançimet e kaluara të DeepSeek janë ndonjë udhëzues, atëherë kjo mund të mos jetë e pamundur të arrihet edhe me të gjitha kufizimet me të cilat do të përballet një laborator kinez i inteligjencës artificiale.
Duke supozuar se thashethemet janë të vërteta, si mund ta arrijë një gjë të tillë ky laborator i vogël?
Arma sekrete e kompanisë mund të përmbahet në punimin e saj kërkimor të 1 janarit: Lidhjet Hiper të Kufizuara nga Shumëllojshmëria, ose mHC. E bashkautorizuar nga themeluesi Liang Wenfeng, metoda e re e trajnimit adreson një problem themelor në shkallëzimin e modeleve të mëdha gjuhësore – si të zgjerohet kapaciteti i një modeli pa u bërë i paqëndrueshëm ose pa shpërthyer gjatë trajnimit.
Arkitekturat tradicionale të IA-së i detyrojnë të gjitha informacionet të kalojnë nëpër një rrugë të vetme të ngushtë. mHC-ja e zgjeron atë rrugë në rrjedha të shumta që mund të shkëmbejnë informacion pa shkaktuar kolaps të trajnimit.
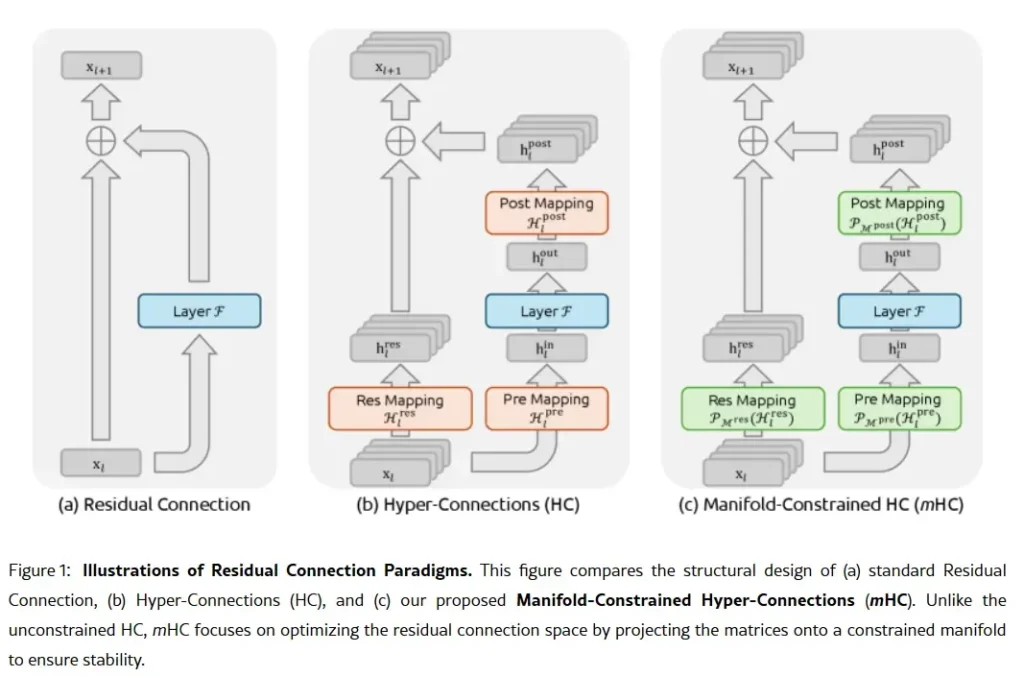
Wei Sun, analistja kryesore për IA-në në Counterpoint Research, e quajti mHC-në një “zbulim të jashtëzakonshëm” në komentet për Business Insider . Teknika, tha ajo, tregon se DeepSeek mund të “anashkalojë pengesat llogaritëse dhe të zhbllokojë hapa të mëdhenj në inteligjencë”, edhe me qasje të kufizuar në çipa të përparuar për shkak të kufizimeve të eksportit të SHBA-së.
Lian Jye Su, analisti kryesor në Omdia, vuri në dukje se gatishmëria e DeepSeek për të publikuar metodat e saj sinjalizon një “besim të rigjetur në industrinë kineze të inteligjencës artificiale”. Qasja me burim të hapur e kompanisë e ka bërë atë një të preferuar midis zhvilluesve që e shohin atë si mishërim të asaj që ishte OpenAI, përpara se të kalonte në modele të mbyllura dhe raunde mbledhjeje fondesh prej miliarda dollarësh.
Jo të gjithë janë të bindur. Disa zhvillues në Reddit ankohen se modelet e arsyetimit të DeepSeek shpenzojnë shumë llogaritje në detyra të thjeshta, ndërsa kritikët argumentojnë se standardet e kompanisë nuk pasqyrojnë rrëmujën e botës reale. Një postim në Medium me titull “DeepSeek është i keq—Dhe nuk pretendoj më se nuk është” u bë viral në prill 2025, duke akuzuar modelet se prodhonin “marrëzi standarde me gabime” dhe “biblioteka halucinante”.
DeepSeek gjithashtu mbart barrë. Shqetësimet për privatësinë e kanë shqetësuar kompaninë, me disa qeveri që kanë ndaluar aplikacionin vendas të DeepSeek. Lidhjet e kompanisë me Kinën dhe pyetjet rreth censurës në modelet e saj shtojnë fërkime gjeopolitike në debatet teknike.
Megjithatë, momenti është i pamohueshëm. Deepseek është përdorur gjerësisht në Azi dhe nëse V4 i përmbush premtimet e tij të kodimit, atëherë mund të pasojë edhe përdorimi i tij në Perëndim.
Ekziston edhe koha. Sipas Reuters, DeepSeek fillimisht kishte planifikuar të lançonte modelin e saj R2 në maj 2025, por e zgjeroi pistën pasi themeluesi Liang u pakënaq me performancën e tij. Tani, me V4 që thuhet se synon shkurtin dhe R2 që mund të vijë në gusht, kompania po ecën me një ritëm që sugjeron urgjencë – ose besim. Ndoshta të dyja.