DeepSeek-V3, AI me burim të hapur ultra të madh, i kalon Llama dhe Qwen në fillim

Startup kinez i AI DeepSeek, i njohur për sfidimin e shitësve kryesorë të AI me teknologjitë e tij inovative me burim të hapur, lëshoi sot një model të ri ultra të madh: DeepSeek-V3.
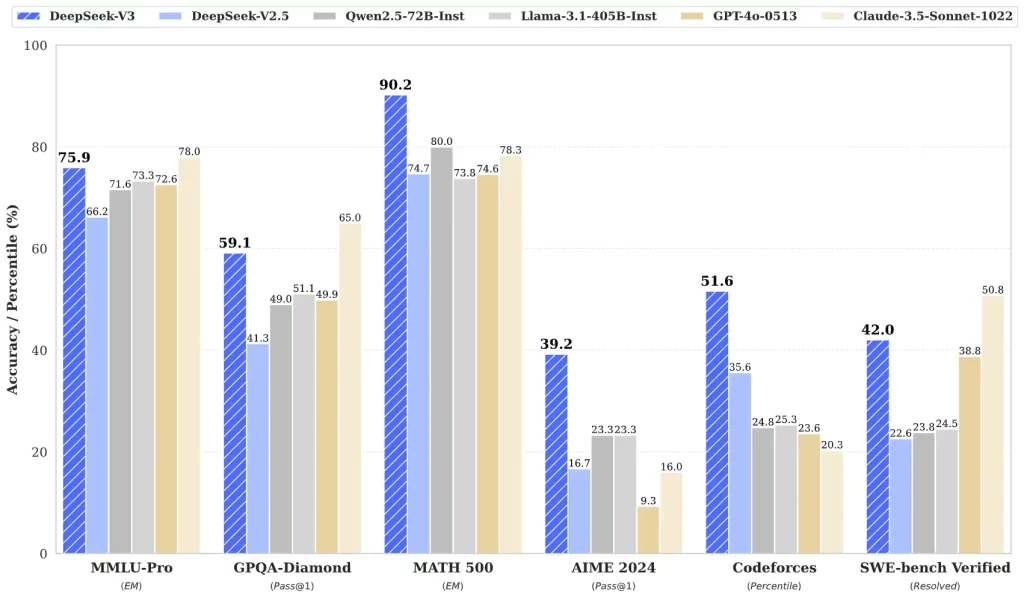
I disponueshëm përmes Hugging Face sipas marrëveshjes së licencës së kompanisë, modeli i ri vjen me parametra 671B, por përdor një arkitekturë të përzier ekspertësh për të aktivizuar vetëm parametra të zgjedhur, në mënyrë që të trajtojë detyrat e dhëna me saktësi dhe efikasitet. Sipas standardeve të përbashkëta nga DeepSeek, oferta tashmë është në krye të tabelave, duke tejkaluar modelet kryesore me burim të hapur, duke përfshirë Llama 3.1-405B të Meta, dhe duke përputhur ngushtë performancën e modeleve të mbyllura nga Anthropic dhe OpenAI.
Publikimi shënon një tjetër zhvillim të madh që mbyll hendekun midis AI të mbyllur dhe me burim të hapur. Në fund të fundit, DeepSeek, i cili filloi si një degë e fondit të mbrojtjes sasiore kineze High-Flyer Capital Management, shpreson se këto zhvillime do të hapin rrugën për inteligjencën e përgjithshme artificiale (AGI), ku modelet do të kenë aftësinë për të kuptuar ose mësuar çdo detyrë intelektuale që një qenia njerëzore mund.
Ashtu si paraardhësi i tij DeepSeek-V2, modeli i ri ultra i madh përdor të njëjtën arkitekturë bazë që rrotullohet rreth vëmendjes latente me shumë kokë (MLA) dhe DeepSeekMoE. Kjo qasje siguron që ajo të mbajë trajnime dhe përfundime efikase – me “ekspertë” të specializuar dhe të përbashkët (rrjete nervore individuale, më të vogla brenda modelit më të madh) duke aktivizuar 37B parametra nga 671B për çdo shenjë.
Ndërsa arkitektura bazë siguron performancë të fortë për DeepSeek-V3, kompania ka debutuar gjithashtu dy risi për të shtyrë më tej shiritin.
E para është një strategji ndihmëse e balancimit të ngarkesës pa humbje. Kjo monitoron dhe rregullon në mënyrë dinamike ngarkesën e ekspertëve për t’i përdorur ato në një mënyrë të ekuilibruar pa kompromentuar performancën e përgjithshme të modelit. E dyta është parashikimi me shumë shenja (MTP), i cili lejon modelin të parashikojë disa argumente të së ardhmes në të njëjtën kohë. Kjo risi jo vetëm që rrit efikasitetin e trajnimit, por i mundëson modelit të performojë tre herë më shpejt, duke gjeneruar 60 token në sekondë.
“Gjatë trajnimit paraprak, ne trajnuam DeepSeek-V3 në 14.8T argumente me cilësi të lartë dhe të larmishme… Më pas, ne kryem një zgjatje të gjatësisë së kontekstit me dy faza për DeepSeek-V3,” shkroi kompania në një dokument teknik që detajon modelin e ri. “Në fazën e parë, gjatësia maksimale e kontekstit zgjatet në 32K dhe në fazën e dytë zgjatet më tej në 128K. Në vijim të kësaj, ne kemi kryer trajnime pas, duke përfshirë Rregullimin e Përsosur të Mbikëqyrur (SFT) dhe Mësimin e Përforcimit (RL) në modelin bazë të DeepSeek-V3, për ta përshtatur atë me preferencat njerëzore dhe për të zhbllokuar më tej potencialin e tij. Gjatë fazës pas trajnimit, ne distilojmë aftësinë e arsyetimit nga seria e modeleve DeepSeekR1, dhe ndërkohë ruajmë me kujdes ekuilibrin midis saktësisë së modelit dhe gjatësisë së gjenerimit.
Veçanërisht, gjatë fazës së trajnimit, DeepSeek përdori optimizime të shumta harduerike dhe algoritmike, duke përfshirë kornizën e trajnimit me saktësi të përzier FP8 dhe algoritmin DualPipe për paralelizmin e tubacionit, për të ulur kostot e procesit.
Në përgjithësi, ajo pretendon se ka përfunduar të gjithë trajnimin e DeepSeek-V3 në rreth 2788K orë GPU H800, ose rreth 5.57 milionë dollarë, duke supozuar një çmim qiraje prej 2 dollarë për orë GPU. Kjo është shumë më e ulët se qindra miliona dollarë që zakonisht shpenzohen për para-trajnimin e modeleve të mëdha gjuhësore.
Llama-3.1, për shembull, vlerësohet të jetë trajnuar me një investim prej mbi 500 milion dollarë.
Pavarësisht trajnimit ekonomik, DeepSeek-V3 është shfaqur si modeli më i fortë me burim të hapur në treg.
Kompania zbatoi standarde të shumta për të krahasuar performancën e AI dhe vuri në dukje se në mënyrë bindëse tejkalon modelet kryesore të hapura, duke përfshirë Llama-3.1-405B dhe Qwen 2.5-72B. Ai madje tejkalon GPT-4o me burim të mbyllur në shumicën e standardeve, përveç SimpleQA dhe FRAMES të përqendruara në anglisht – ku modeli OpenAI ishte përpara me rezultate 38.2 dhe 80.5 (kundrejt 24.9 dhe 73.3), respektivisht.
Veçanërisht, performanca e DeepSeek-V3 u dallua veçanërisht në standardet kineze dhe matematikore, duke shënuar më mirë se të gjithë homologët. Në testin Math-500, ai shënoi 90.2, me rezultatin 80 të Qwen më të mirën e radhës.
Modeli i vetëm që arriti të sfidonte DeepSeek-V3 ishte Soneti Claude 3.5 i Anthropic, duke e tejkaluar atë me rezultate më të larta në MMLU-Pro, IF-Eval, GPQA-Diamond, SWE Verified dhe Aider-Edit.
Puna tregon se burimi i hapur po afrohet me modelet me burim të mbyllur, duke premtuar performancë pothuajse ekuivalente në detyra të ndryshme. Zhvillimi i sistemeve të tilla është jashtëzakonisht i mirë për industrinë pasi eliminon potencialisht shanset që një lojtar i madh i AI të sundojë lojën. Ai gjithashtu u jep ndërmarrjeve opsione të shumta për të zgjedhur dhe për të punuar me të gjatë orkestrimit të grupeve të tyre.
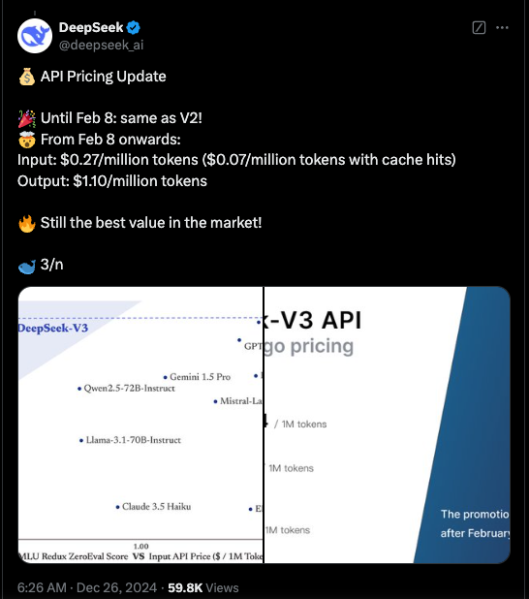
Aktualisht, kodi për DeepSeek-V3 është i disponueshëm përmes GitHub nën një licencë MIT, ndërsa modeli ofrohet nën licencën e modelit të kompanisë. Ndërmarrjet gjithashtu mund të testojnë modelin e ri përmes DeepSeek Chat, një platformë e ngjashme me ChatGPT dhe të hyjnë në API për përdorim komercial. DeepSeek po ofron API-në me të njëjtin çmim si DeepSeek-V2 deri më 8 shkurt. Pas kësaj, do të tarifojë 0,27 $/milion argumente hyrëse (0,07 $/milion argumente me goditje në cache) dhe 1,10 $/milion argumente dalëse.