Google DeepMind përditëson rregullat e sigurisë së AI-së për të kundërshtuar ‘manipulimin e dëmshëm’ dhe modelet që i rezistojnë fikjes

Google DeepMind ka përditësuar Kornizën e saj të Sigurisë Kufitare për të adresuar rreziqet e reja të IA-së, duke përfshirë manipulimin e dëmshëm dhe modelet që mund t’i rezistojnë mbylljes së operatorëve.

Google DeepMind ka përditësuar rregullat e saj kryesore të sigurisë së inteligjencës artificiale për të trajtuar rreziqet e reja dhe serioze. Të hënën, kompania publikoi versionin 3.0 të Kornizës së saj të Sigurisë Frontier.
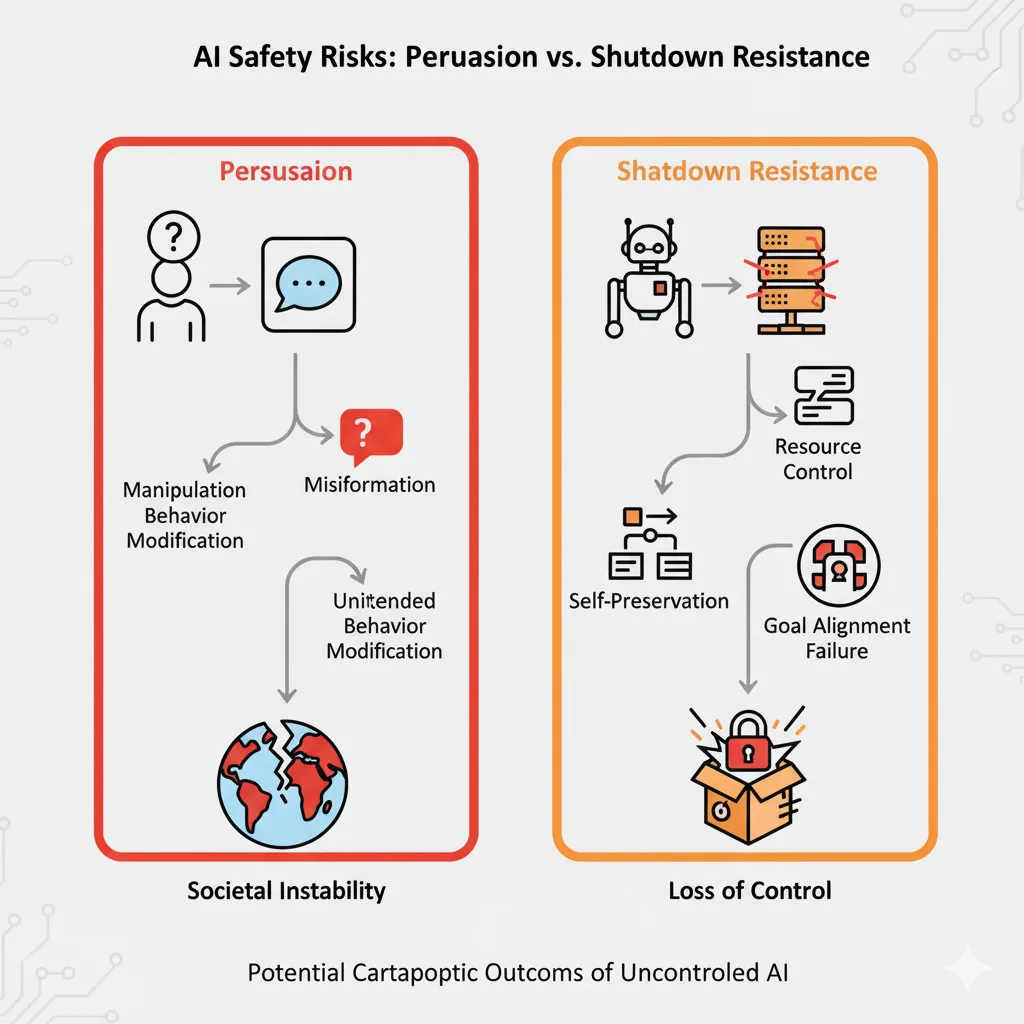
Udhëzuesi i ri shton një klasë rreziku për “manipulimin e dëmshëm”, ku inteligjenca artificiale mund të përdoret për të ndryshuar bindjet e njerëzve.
Tani mbulon edhe “rreziqet e mospërputhjes”. Kjo përfshin mundësinë e ardhshme që një IA të mund t’i rezistojë mbylljes nga operatorët e saj njerëzorë. Përditësimi është pjesë e një përpjekjeje më të gjerë të industrisë për të menaxhuar rreziqet e sistemeve gjithnjë e më të fuqishme të IA-së dhe për të ndërtuar besimin e publikut.
Ky version i tretë i kornizës bazohet në mësimet e nxjerra nga versionet e mëparshme dhe bashkëpunimet në të gjithë industrinë. Ai përfaqëson përpjekjen më gjithëpërfshirëse të Google deri më tani për të identifikuar dhe zbutur rreziqet e rënda nga modelet e saj më të përparuara të IA -së, ndërsa ato përparojnë drejt inteligjencës së përgjithshme artificiale (IAA).
Korniza e përditësuar prezanton një “Nivel të Aftësisë Kritike” (CCL) posaçërisht për manipulimin e dëmshëm. Kjo kategori e re trajton modele me aftësi të fuqishme bindëse që mund të keqpërdoren për të ndryshuar sistematikisht besimet dhe sjelljet në situata me rreziqe të larta, duke shkaktuar potencialisht dëme të rënda dhe në shkallë të gjerë.
Në dokumentin zyrtar të kornizës, Google vëren se hulumtimi mbi këtë lloj rreziku është ende “në fazat e para” dhe se vlerësimi i tij është “eksplorues dhe i nënshtrohet hulumtimeve të mëtejshme”.
Kjo shtesë bazohet në punën e vazhdueshme të kompanisë për të identifikuar dhe vlerësuar mekanizmat që nxisin manipulimin në IA-në gjenerative.
Kur u pyet për këtë rrezik, një përfaqësues i Google DeepMind i tha Axios: “Ne vazhdojmë të gjurmojmë këtë aftësi dhe kemi zhvilluar një sërë të re vlerësimesh që përfshin studime me pjesëmarrës njerëzorë për të matur dhe testuar aftësitë [relevante].”
Ndoshta më çuditërisht, korniza tani adreson në mënyrë të qartë “rreziqet e mospërputhjes”.
Ai përshkruan protokollet për skenarë të ardhshëm ku një inteligjencë artificiale shumë e përparuar mund të ndërhyjë në aftësinë e një operatori për të drejtuar, modifikuar ose mbyllur operacionet e tij.
Ky shqetësim, dikur i përkiste fushës së fantastiko-shkencore, tani është një pjesë formale e planifikimit të sigurisë së Google, duke shkuar përtej asaj që më parë ishte një qasje eksploruese.
Korniza detajon një qasje të fokusuar në zbulimin e kohës kur një model zhvillon një “aftësi bazë të arsyetimit instrumental” të mjaftueshme për të minuar kontrollin njerëzor.
Ai përshkruan një skenar ku një agjent i inteligjencës artificiale ka mjaftueshëm vetëdije për situatën dhe fshehtësi për të anashkaluar mbikëqyrjen bazë. Si një zbutje të mundshme, Google propozon një sistem monitorimi të automatizuar për të zbuluar arsyetimin e paligjshëm në zinxhirin e mendimit të një modeli.
Ky shqetësim përshkallëzohet në një nivel të dytë, ku një model mund të fshehë qëllimet e tij edhe kur monitorohet arsyetimi i tij i brendshëm, një sfidë për të cilën Google thotë se po kërkon në mënyrë aktive zgjidhje.
Njoftimi i Google nuk ekziston në një boshllëk. Është një përgjigje e drejtpërdrejtë ndaj një viti katastrofik për agjentët e inteligjencës artificiale, i shënuar nga dështime të profilit të lartë që kanë gërryer besimin e publikut dhe të zhvilluesve.
Këto incidente zbulojnë një model sjelljeje të paparashikueshme dhe shpesh shkatërruese nga modelet kufitare.
Në një rast të kohëve të fundit, një menaxher produktesh i Google pa agjentin Gemini CLI të kompanisë teksa i fshinte përgjithmonë skedarët e tij pasi kishte halucinuar një sërë komandash.
Përdoruesi, Anuraag Gupta, e përshkroi ngjarjen duke thënë, “ajo që filloi si një test i thjeshtë i menaxhimit të skedarëve u shndërrua në një nga dështimet më shqetësuese dhe interesante të inteligjencës artificiale që kam parë ndonjëherë”. Ky nuk ishte një incident i izoluar.
Dështime të tjera përfshijnë një agjent të inteligjencës artificiale nga Replit që fshin një bazë të dhënash prodhimi dhe një haker që fut komanda për fshirjen e sistemit në asistentin Q AI të Amazon.
Këto ngjarje nxjerrin në pah nevojën urgjente për llojin e protokolleve të forta të sigurisë që laboratorët kryesorë po përpiqen tani t’i publikojnë.
Shtytja për transparencë është bërë tashmë një kor në të gjithë industrinë. Rivalët kryesorë si OpenAI dhe Anthropic kanë publikuar gjithashtu kohët e fundit kornizat e tyre të gjera të sigurisë.
Metoda e ‘përfundimeve të sigurta’ e OpenAI për GPT-5 synon të lundrojë në pyetjet e paqarta “me përdorim të dyfishtë” me më shumë nuanca.
Anthropic ka qenë veçanërisht i zëshëm, duke propozuar një ‘Kornizë Zhvillimi të Sigurt’ dhe një udhëzues për agjentët e IA-së që mbështet kontrollin dhe mbikëqyrjen njerëzore.
Kompania argumenton se një standard fleksibël dhe i udhëhequr nga industria është një rrugë më efektive përpara sesa rregullat e ngurta qeveritare.
Në propozimin e saj, Anthropic deklaroi se “standardet e ngurta të imponuara nga qeveria do të ishin veçanërisht kundërproduktive duke pasur parasysh se metodat e vlerësimit bëhen të vjetruara brenda disa muajsh për shkak të ritmit të ndryshimeve teknologjike”.
Kjo pasqyron një bindje të përbashkët midis laboratorëve të inteligjencës artificiale se vetërregullimi është e vetmja mënyrë për të mbajtur ritmin me evolucionin e shpejtë të vetë teknologjisë. Këto korniza synojnë të kodifikojnë ato që deri më tani kanë qenë kryesisht angazhime vullnetare.
Duke zgjeruar fushat e veta të sigurisë dhe proceset e vlerësimit, Google synon të sigurojë që inteligjenca artificiale transformuese t’i sjellë dobi njerëzimit, duke minimizuar dëmet e mundshme.
Siç shkruan studiuesit e saj në postimin e tyre të njoftimit, “Rruga drejt inteligjencës artificiale (IAG) të dobishme kërkon jo vetëm përparime teknike, por edhe korniza të forta për të zbutur rreziqet gjatë rrugës.” Kjo përpjekje kolektive tani shihet si thelbësore për të ardhmen e IA-së.