Google lëshon Gemma 3n, një model të ri inteligjence artificiale të ndërtuar për pajisje mobile

Google ka njoftuar Gemma 3n, gjeneratën e ardhshme të modeleve të saj të hapura të inteligjencës artificiale, dhe është një hap i rëndësishëm përpara nga ajo që pamë më parë. Pas një prezantimi paraprak muajin e kaluar në Google I/O, versioni i plotë tani është këtu dhe gati për t’u ekzekutuar direkt në harduerin tuaj.

Për ata prej jush që nuk janë në dijeni, Gemma është një familje modelesh të hapura të inteligjencës artificiale. Është e ndryshme nga Gemini në atë që është projektuar që zhvilluesit ta shkarkojnë dhe modifikojnë, ndërsa Gemini është fuqia e mbyllur dhe pronësore e Google.
Modeli tani mund të përpunojë në mënyrë native të dhëna si imazhe, audio dhe video për të gjeneruar tekst, një hap përpara nga të qenit thjesht një model i bazuar në tekst. Mund të funksionojë edhe në harduer me vetëm 2 GB memorie dhe supozohet se është më i mirë në detyra si kodimi dhe arsyetimi. Ja lista e plotë e përmirësimeve siç përshkruhet nga Google:
Multimodal nga dizajni: Gemma 3n mbështet në mënyrë native hyrjen dhe daljen e imazhit, audios, videos dhe tekstit.
I optimizuar për në pajisje: Të projektuara me fokus në efikasitet, modelet Gemma 3n janë të disponueshme në dy madhësi bazuar në parametrat efektivë: E2B dhe E4B. Ndërsa numri i parametrave të tyre të papërpunuar është përkatësisht 5B dhe 8B, inovacionet arkitekturore u lejojnë atyre të funksionojnë me një gjurmë memorieje të krahasueshme me modelet tradicionale 2B dhe 4B, duke operuar me vetëm 2GB (E2B) dhe 3GB (E4B) memorie.
Arkitekturë revolucionare: Në thelbin e saj, Gemma 3n përmban komponentë të rinj si arkitektura MatFormer për fleksibilitet në llogaritje, Për Shtresa Embeddings (PLE) për efikasitet të memories dhe enkoderë të rinj audio dhe vizualë të bazuar në MobileNet-v5 të optimizuar për rastet e përdorimit në pajisje.
Cilësi e përmirësuar: Gemma 3n ofron përmirësime cilësore në shumëgjuhësi (mbështet 140 gjuhë për tekst dhe kuptim multimodal të 35 gjuhëve), matematikë, kodim dhe arsyetim.
Thelbi i efikasitetit të saj është një arkitekturë e re që Google e quan MatFormer. Google përdor analogjinë e një kukulle ruse Matryoshka për ta përshkruar atë: një model më i madh përmban brenda një version më të vogël dhe plotësisht funksional.
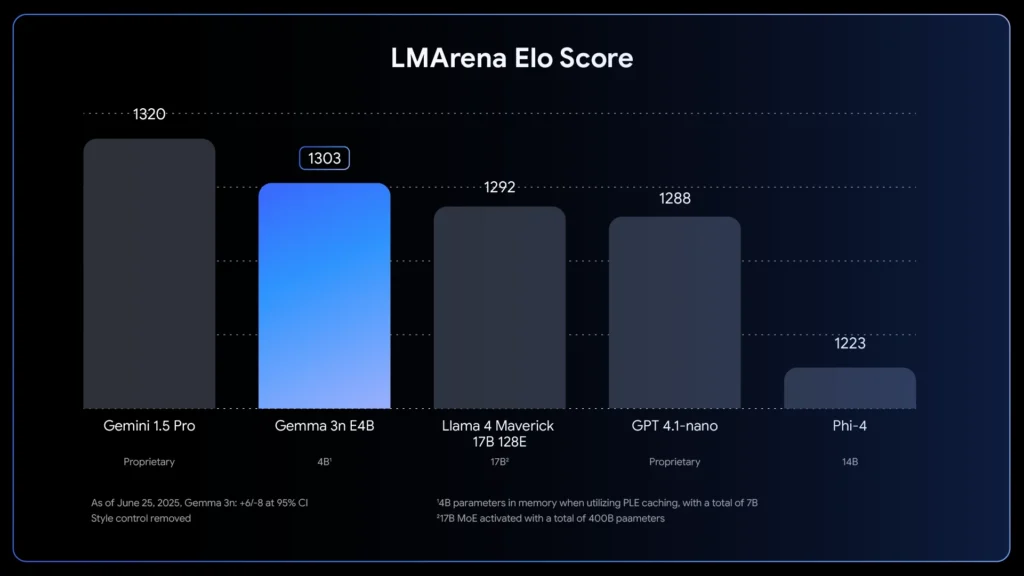
Kjo lejon që një model i vetëm të funksionojë në madhësi të ndryshme për detyra të ndryshme. Dhe sa i përket testeve, modeli më i madh E4B është modeli i parë nën parametrat 10B që theu një rezultat LMArena prej 1300.
Aftësitë audio të modelit tani mbështesin konvertimin e të folurit në tekst dhe përkthimin në pajisje, duke përdorur një enkoder që mund të përpunojë të folurit me detaje të imëta. Ana vizuale e gjërave mundësohet nga një enkoder i ri i quajtur MobileNet-V5, i cili është shumë më i shpejtë dhe më efikas se paraardhësi i tij. Mund të përpunojë video deri në 60FPS në një pajisje Google Pixel.
Nëse jeni të interesuar, mund të filloni të luani me të menjëherë pasi modelet janë të disponueshme përmes platformave të njohura si Hugging Face dhe Kaggle, dhe madje mund të eksperimentoni me to direkt në Google AI Studio.