Meta mbron publikimin e Llama 4 kundër “raporteve për cilësi të përzier,” duke fajësuar gabimet

Modeli i ri i flamurit i Meta-s në gjuhën e AI, Llama 4, erdhi papritur gjatë fundjavës, me kompaninë mëmë të Facebook, Instagram, WhatsApp dhe Quest VR që zbuloi jo një, jo dy, por tre versione të gjitha të përmirësuara për të qenë më të fuqishëm dhe më performues duke përdorur metodën popullore “Mixture-of-Experts” në arkitekturën evolucionit të Meta dhe një metodë të re të trajnimit të hipermetrit, të njohur si hiperparata.

Gjithashtu, të treja janë të pajisura me dritare të mëdha konteksti – sasia e informacionit që një model i gjuhës AI mund të trajtojë në një shkëmbim hyrje/dalje me një përdorues ose mjet.
Por pas njoftimit të papritur dhe publikimit publik të dy prej atyre modeleve për shkarkim dhe përdorim – parametri më i ulët Llama 4 Scout dhe niveli i mesëm Llama 4 Maverick – të shtunën, përgjigja nga komuniteti i AI në mediat sociale ka qenë më pak se adhuruese.
Një postim i paverifikuar në forumin e komunitetit të gjuhës kineze të Amerikës së Veriut 1point3acres kaloi në nënreditin r/LocalLlama në Reddit duke pretenduar se ishte nga një studiues në organizatën GenAI të Metës, i cili pretendonte se modeli performoi dobët në standardet e palëve të treta brenda dhe se udhëheqja e kompanisë “sugjeroi kombinimin e testeve gjatë procesit të postimit, duke më synuar teste të ndryshme. në metrika të ndryshme dhe prodhojnë një rezultat ‘të prezantueshëm’.”
Postimi u prit me skepticizëm nga komuniteti në autenticitetin e tij dhe një email i VentureBeat drejtuar një zëdhënësi të Meta nuk ka marrë ende një përgjigje.
Por përdoruesit e tjerë gjetën arsye për të dyshuar në standardet pavarësisht.
“Në këtë pikë, dyshoj shumë se Meta ka grumbulluar diçka në peshat e lëshuara… nëse jo, ata duhet të pushojnë nga puna të gjithë ata që kanë punuar për këtë dhe më pas të përdorin para për të blerë Nous ,” komentoi @cto_junior në X, duke iu referuar një testi të pavarur përdoruesi që tregon performancën e dobët të Llama 4 Maverick (16%) në një model standard 2, i njohur si aider 2, i cili njihet si aider 2. detyrat. Kjo është shumë më e ulët se performanca e modeleve të vjetra me përmasa të krahasueshme si DeepSeek V3 dhe Claude 3.7 Sonnet.
Duke iu referuar dritares së kontekstit prej 10 milionë tokenesh që Meta u mburr për Llama 4 Scout, AI PhD dhe autori Andriy Burkov shkroi në X pjesërisht se: “Konteksti i deklaruar 10 milion është virtual sepse asnjë model nuk është trajnuar me kërkesa më të gjata se 256 mijë argumente. Kjo do të thotë se nëse dërgoni më shumë se 256 mijë argumente, do të merrni shumicën e kohës me cilësi të ulët.”
Gjithashtu në subreddit r/LocalLlama, përdoruesi Dr_Karminski shkroi se “ Jam tepër i zhgënjyer me Llama-4, ” dhe tregoi performancën e tij të dobët në krahasim me modelin V3 pa arsyetim të DeepSeek në detyrat e kodimit të tilla si simulimi i topave që kërcejnë rreth një shtatëkëndëshi.
Ish-kërkuesi i Meta-s dhe shkencëtari aktual i AI2 (Instituti Allen për Inteligjencën Artificiale) Nathan Lambert shkoi në blogun e tij në Interconnects Substack të hënën për të vënë në dukje se një krahasim standard i postuar nga Meta në faqen e vet të shkarkimit Llama të Llama 4 Maverick me modele të tjera, bazuar në kosto-për-performancën e koeficientit të LMA-s. Chatbot Arena, në fakt përdori një version të ndryshëm të Llama 4 Maverick nga ai që vetë kompania e kishte vënë në dispozicion publikisht – një “i optimizuar për biseda”.
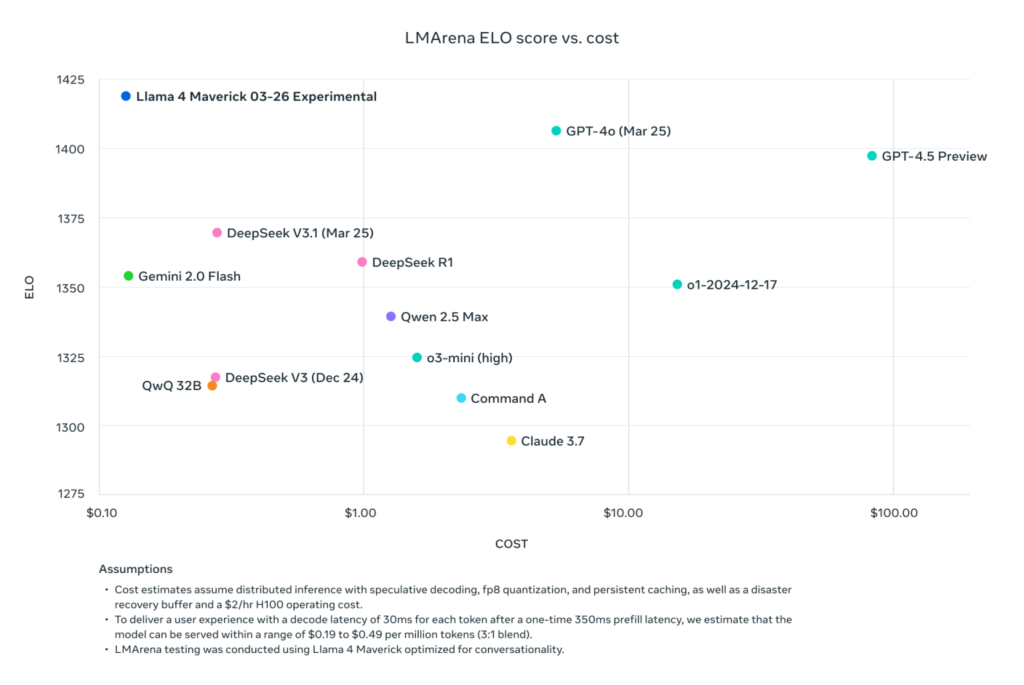
Siç shkroi Lambert: “Të poshtër. Rezultatet më poshtë janë të rreme dhe është një problem i madh për komunitetin e Metës që të mos lëshojë modelin që ata përdorën për të krijuar shtytjen e tyre kryesore të marketingut. Ne kemi parë shumë modele të hapura që vijnë për të maksimizuar në ChatBotArena ndërsa shkatërrojnë performancën e modelit në aftësi të rëndësishme si matematika ose kodi.”
Lambert vazhdoi të vuri në dukje se ndërsa ky model i veçantë në arenë “po rëndonte reputacionin teknik të publikimit sepse karakteri i tij është i mitur”, duke përfshirë shumë emoji dhe dialog joserioz emocional, “Modeli aktual në ofruesit e tjerë të pritjes është mjaft i zgjuar dhe ka një ton të arsyeshëm!”
Në përgjigje të valës së kritikave dhe akuzave për gatim standard, Zëvendëspresidenti i Metës dhe Shefi i GenAI-t Ahmad Al-Dahle shkoi te X për të deklaruar:
“Ne jemi të lumtur që fillojmë të marrim Llama 4 në të gjitha duart tuaja. Tashmë po dëgjojmë shumë rezultate të shkëlqyera që njerëzit po marrin me këto modele.
Thënë kështu, ne po dëgjojmë gjithashtu disa raporte me cilësi të përzier në shërbime të ndryshme. Meqenëse i hoqëm modelet sapo të ishin gati, presim që do të duhen disa ditë që të gjitha zbatimet publike të thirren. Ne do të vazhdojmë të punojmë përmes korrigjimit të defekteve dhe partnerëve tanë të hyrjes.
Ne kemi dëgjuar gjithashtu pretendime se kemi stërvitur në grupe testimi – kjo thjesht nuk është e vërtetë dhe ne nuk do ta bënim kurrë këtë. Kuptimi ynë më i mirë është se cilësia e ndryshueshme që njerëzit po shohin është për shkak të nevojës për të stabilizuar implementimet.
Ne besojmë se modelet Llama 4 janë një përparim i rëndësishëm dhe ne mezi presim të punojmë me komunitetin për të zhbllokuar vlerën e tyre. “
Megjithatë, edhe kjo përgjigje u prit me shumë ankesa për performancë të dobët dhe thirrje për informacione të mëtejshme, të tilla si më shumë dokumentacion teknik që përshkruan modelet Llama 4 dhe proceset e tyre të trajnimit, si dhe pyetje shtesë se pse ky version në krahasim me të gjitha lëshimet e mëparshme të Llama ishte veçanërisht i mbushur me probleme.
Ai gjithashtu vjen pas numrit dy në Zëvendës Presidentja e Metës për Kërkime, Joelle Pineau, e cila punoi në organizatën ngjitur me Meta Foundational Artificial Intelligence Research (FAIR), duke njoftuar largimin e saj nga kompania në LinkedIn javën e kaluar me “asgjë përveç admirimit dhe mirënjohjes së thellë për secilin prej menaxherëve të mi”. Pineau, duhet theksuar se promovoi edhe publikimin e familjes modele Llama 4 këtë fundjavë.
Llama 4 vazhdon të përhapet tek ofruesit e tjerë të konkluzioneve me rezultate të përziera, por është e sigurt të thuhet se publikimi fillestar i familjes së modeleve nuk ka qenë një përplasje me komunitetin e AI.
Dhe Meta LlamaCon i ardhshëm më 29 Prill, festimi dhe mbledhja e parë për zhvilluesit e palëve të treta të familjes së modeleve, ka të ngjarë të ketë shumë ushqim për diskutim. Ne do t’i ndjekim të gjitha, qëndroni të sintonizuar.