Meta publikon modelin e saj më të fuqishëm të AI deri më tani

Modeli më i fundit i AI me burim të hapur i Metës është më i madhi deri më tani.
Sot, Meta tha se po lëshon Llama 3.1 405B, një model që përmban 405 miliardë parametra. Parametrat përafërsisht korrespondojnë me aftësitë e një modeli për zgjidhjen e problemeve dhe modelet me më shumë parametra në përgjithësi performojnë më mirë se ato me më pak parametra.
Me 405 miliardë parametra, Llama 3.1 405B nuk është modeli më i madh absolut me burim të hapur, por është më i madhi në vitet e fundit. I trajnuar duke përdorur 16,000 GPU Nvidia H100, ai gjithashtu përfiton nga teknikat më të reja të trajnimit dhe zhvillimit që Meta pretendon se e bëjnë atë konkurrues me modelet kryesore të pronarit si GPT-4o i OpenAI dhe Soneti Claude 3.5 i Anthropic (me disa vërejtje).
Ashtu si me modelet e mëparshme të Metës, Llama 3.1 405B është i disponueshëm për t’u shkarkuar ose përdorur në platformat cloud si AWS, Azure dhe Google Cloud. Ai po përdoret gjithashtu në WhatsApp dhe Meta.ai, ku po fuqizon një përvojë chatbot për përdoruesit me bazë në SHBA.
Ashtu si modelet e tjera gjeneruese të inteligjencës artificiale me burim të hapur dhe të mbyllur, Llama 3.1 405B mund të kryejë një sërë detyrash të ndryshme, nga kodimi dhe përgjigjja e pyetjeve bazë të matematikës deri te përmbledhja e dokumenteve në tetë gjuhë (anglisht, gjermanisht, frëngjisht, italisht, portugalisht, hindisht, spanjisht dhe tajlandez. ). Është vetëm tekst, që do të thotë se nuk mund, për shembull, t’u përgjigjet pyetjeve në lidhje me një imazh, por shumica e ngarkesave të punës të bazuara në tekst – mendoni të analizoni skedarët si PDF dhe spreadsheets – janë në kompetencën e tij.
Meta kërkon të bëjë të ditur se po eksperimenton me multimodalitetin. Në një punim të botuar sot, studiuesit në kompani shkruajnë se ata po zhvillojnë në mënyrë aktive modele Llama që mund të njohin imazhet dhe videot dhe të kuptojnë (dhe gjenerojnë) fjalimin. Megjithatë, këto modele nuk janë ende gati për publikim.
Për të trajnuar Llama 3.1 405B, Meta përdori një grup të dhënash prej 15 trilionë tokenash që datojnë deri në vitin 2024 (shenjat janë pjesë fjalësh që modelet mund t’i përvetësojnë më lehtë se fjalët e plota, dhe 15 trilion argumente përkthehen në 750 miliardë fjalë befasuese). Nuk është një grup i ri trajnimi në vetvete, pasi Meta përdori grupin bazë për të trajnuar modelet e mëparshme të Llama, por kompania pretendon se ka rafinuar tubacionet e saj të kurimit për të dhënat dhe ka miratuar qasje “më rigoroze” të sigurimit të cilësisë dhe filtrimit të të dhënave në zhvillimin e këtij modeli.
Kompania përdori gjithashtu të dhëna sintetike (të dhëna të krijuara nga modele të tjera të AI) për të rregulluar mirë Llama 3.1 405B. Shumica e shitësve të mëdhenj të AI, përfshirë OpenAI dhe Anthropic, po eksplorojnë aplikime të të dhënave sintetike për të rritur trajnimin e tyre të AI, por disa ekspertë besojnë se të dhënat sintetike duhet të jenë zgjidhja e fundit për shkak të potencialit të tyre për të përkeqësuar paragjykimet e modelit.
Nga ana e saj, Meta këmbëngul që të “balancojë me kujdes[d]” të dhënat e trajnimit të Llama 3.1 405B, por nuk pranoi të zbulojë saktësisht se nga erdhën të dhënat (jashtë faqeve të internetit dhe skedarëve të uebit publik). Shumë shitës gjenerues të AI i shohin të dhënat e trajnimit si një avantazh konkurrues dhe kështu i mbajnë ato dhe çdo informacion që i përket afër gjoksit. Por detajet e të dhënave të trajnimit janë gjithashtu një burim i mundshëm i padive të lidhura me IP, një tjetër dekurajues për kompanitë për të zbuluar shumë.
Në punimin e sipërpërmendur, studiuesit e Meta shkruan se krahasuar me modelet e mëparshme Llama, Llama 3.1 405B u trajnua për një përzierje të shtuar të të dhënave jo-anglisht (për të përmirësuar performancën e saj në gjuhët jo-anglisht), më shumë “të dhëna matematikore” dhe kode (për të të përmirësojë aftësitë e arsyetimit matematik të modelit) dhe të dhënat e fundit të internetit (për të forcuar njohuritë e tij për ngjarjet aktuale).
Raportimi i fundit nga Reuters zbuloi se Meta në një moment përdorte libra elektronikë me të drejtë autori për trajnimin e AI, pavarësisht paralajmërimeve të avokatëve të tij. Kompania trajnon në mënyrë të diskutueshme inteligjencën artificiale të saj në postimet, fotot dhe titrat në Instagram dhe Facebook, dhe e bën të vështirë për përdoruesit të heqin dorë . Për më tepër, Meta, së bashku me OpenAI, është subjekt i një padie të vazhdueshme të ngritur nga autorë, përfshirë komedianin Sarah Silverman, mbi përdorimin e pretenduar të paautorizuar të të dhënave të mbrojtura nga të drejtat e autorit për trajnimin e modeleve.
“Të dhënat e trajnimit, në shumë mënyra, janë si receta sekrete dhe salca që shkon në ndërtimin e këtyre modeleve,” tha Ragavan Srinivasan, zëvendës president i menaxhimit të programit të AI në Meta, për TechCrunch në një intervistë. “Dhe kështu nga këndvështrimi ynë, ne kemi investuar shumë në këtë. Dhe do të jetë një nga këto gjëra ku ne do të vazhdojmë ta përsosim atë.”
Llama 3.1 405B ka një dritare konteksti më të madhe se modelet e mëparshme Llama: 128,000 argumente, ose afërsisht gjatësia e një libri me 50 faqe. Konteksti i një modeli, ose dritarja e kontekstit, i referohet të dhënave hyrëse (p.sh. teksti) që modeli merr në konsideratë përpara se të gjenerojë output (p.sh. tekst shtesë).
Një nga avantazhet e modeleve me kontekste më të mëdha është se ato mund të përmbledhin fragmente dhe skedarë më të gjatë teksti. Kur aktivizojnë chatbots, modele të tilla kanë gjithashtu më pak gjasa të harrojnë temat që janë diskutuar kohët e fundit.
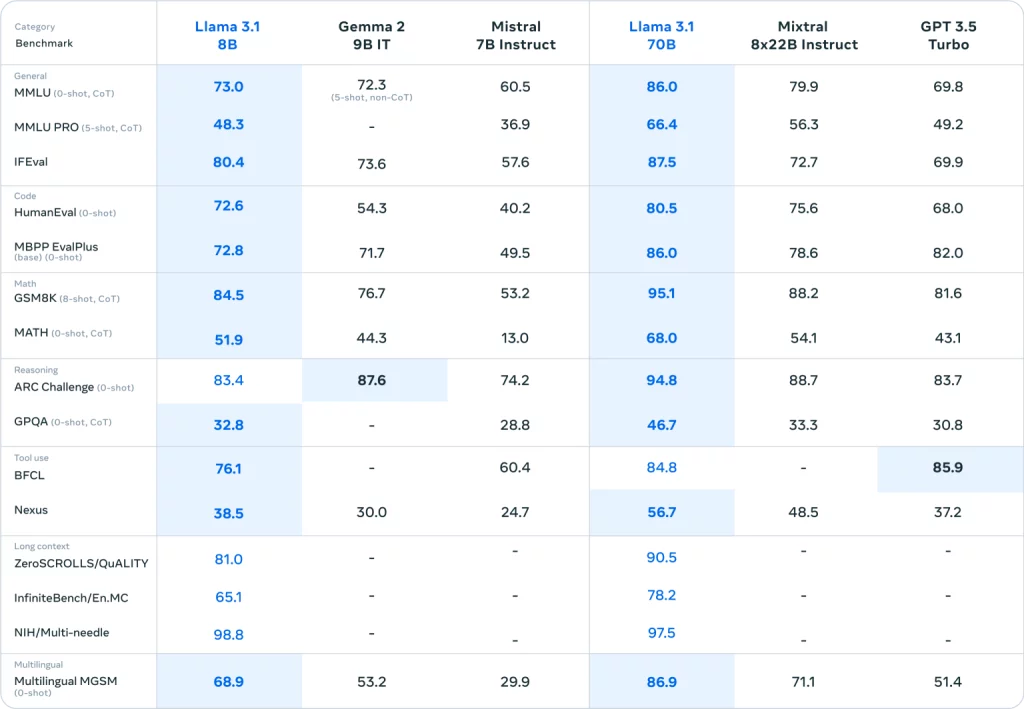
Dy modele të tjera të reja, më të vogla që Meta prezantoi sot, Llama 3.1 8B dhe Llama 3.1 70B — versionet e përditësuara të modeleve Llama 3 8B dhe Llama 3 70B të kompanisë të lëshuara në prill — gjithashtu kanë dritare me kontekst 128,000 token. Kontektet e modeleve të mëparshme arrinin në 8,000 argumente, gjë që e bën këtë përmirësim mjaft të konsiderueshëm – duke supozuar se modelet e reja Llama mund të arsyetojnë në mënyrë efektive në të gjithë atë kontekst.
Të gjitha modelet Llama 3.1 mund të përdorin mjete, aplikacione dhe API të palëve të treta për të përfunduar detyrat, si modelet rivale nga Anthropic dhe OpenAI. Nga kutia, ata janë trajnuar të prekin Brave Search për t’iu përgjigjur pyetjeve në lidhje me ngjarjet e fundit, API-në Wolfram Alpha për pyetjet e lidhura me matematikën dhe shkencën dhe një përkthyes Python për verifikimin e kodit. Përveç kësaj, Meta pretendon se modelet Llama 3.1 mund të përdorin mjete të caktuara që nuk i kanë parë më parë – deri në një masë.
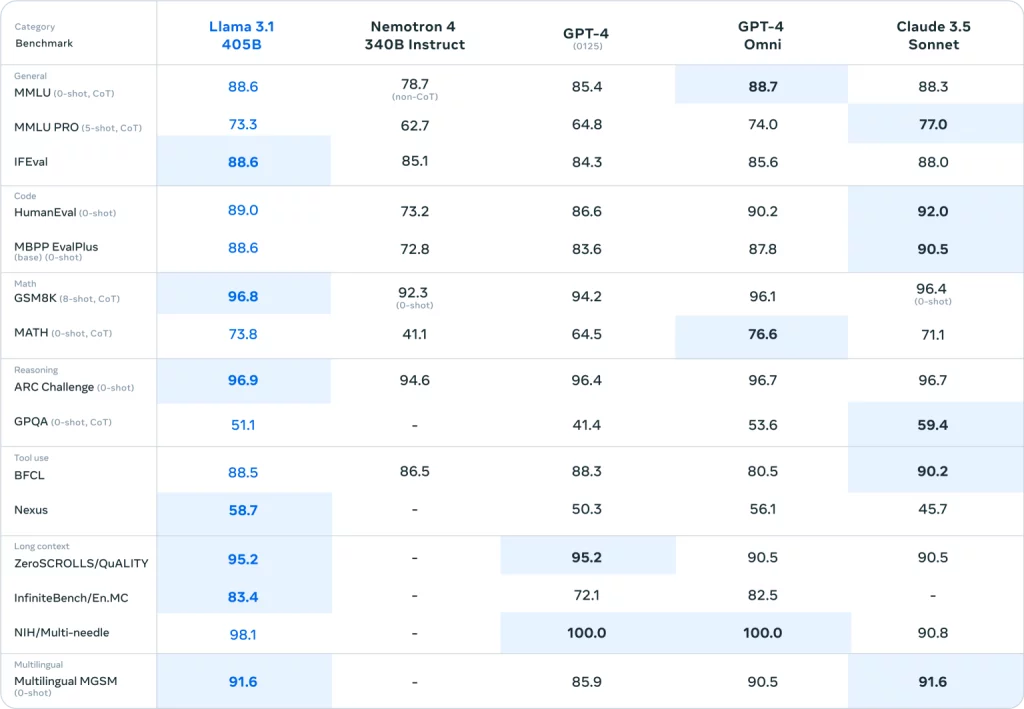
Nëse duhet t’u besohet standardeve ( jo se standardet janë të gjitha të gjitha në AI gjeneruese), Llama 3.1 405B është vërtet një model shumë i aftë. Kjo do të ishte një gjë e mirë, duke marrë parasysh disa nga kufizimet e dukshme të dhimbshme të modeleve të gjeneratës së mëparshme Llama.
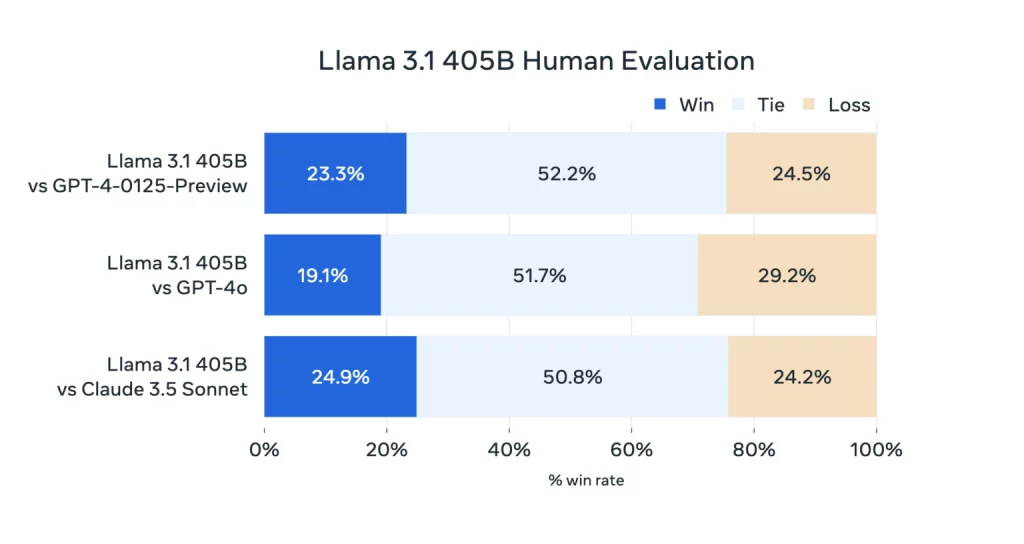
Llama 3 405B performon në të njëjtin nivel me GPT-4 të OpenAI dhe arrin “rezultate të përziera” në krahasim me GPT-4o dhe Claude 3.5 Sonnet, për vlerësuesit njerëzorë që Meta punësoi, vëren gazeta. Ndërsa Llama 3 405B është më i mirë në ekzekutimin e kodit dhe gjenerimin e grafikëve sesa GPT-4o, aftësitë e tij shumëgjuhëshe janë përgjithësisht më të dobëta dhe Llama 3 405B ndjek Claude 3.5 Sonnet në programim dhe arsyetim të përgjithshëm.
Dhe për shkak të madhësisë së tij, ai ka nevojë për pajisje të forta për të funksionuar. Meta rekomandon të paktën një nyje serveri.
Kjo është ndoshta arsyeja pse Meta po nxit modelet e saj më të vogla të reja, Llama 3.1 8B dhe Llama 3.1 70B, për aplikacione me qëllime të përgjithshme si fuqizimi i chatbot-eve dhe gjenerimi i kodit. Llama 3.1 405B, thotë kompania, është më mirë i rezervuar për distilimin e modeleve – procesi i transferimit të njohurive nga një model i madh në një model më të vogël, më efikas – dhe gjenerimi i të dhënave sintetike për të trajnuar (ose rregulluar mirë) modelet alternative.
Për të inkurajuar rastin e përdorimit të të dhënave sintetike, Meta tha se ka përditësuar licencën e Llama për t’i lejuar zhvilluesit të përdorin rezultatet nga familja e modeleve Llama 3.1 për të zhvilluar modele gjeneruese të AI të palëve të treta (nëse kjo është një ide e mençur është për debat ). E rëndësishmja, licenca ende kufizon mënyrën se si zhvilluesit mund të vendosin modelet Llama: Zhvilluesit e aplikacioneve me më shumë se 700 milionë përdorues mujor duhet të kërkojnë një licencë të veçantë nga Meta që kompania do ta japë sipas gjykimit të saj.
Ky ndryshim në licencimin rreth rezultateve, i cili zbut një kritikë të madhe ndaj modeleve të Metës brenda komunitetit të AI, është një pjesë e shtytjes agresive të kompanisë për ndarjen e mendjes në AI gjeneruese.
Krahas familjes Llama 3.1, Meta po lëshon atë që ajo e quan një “sistem referimi” dhe mjete të reja sigurie – disa nga këto sinjale bllokimi që mund të bëjnë që modelet Llama të sillen në mënyra të paparashikueshme ose të padëshirueshme – për të inkurajuar zhvilluesit të përdorin Llama në më shumë vende. Kompania gjithashtu po shikon paraprakisht dhe po kërkon koment për Llama Stack, një API e ardhshme për mjetet që mund të përdoren për të rregulluar modelet Llama, për të gjeneruar të dhëna sintetike me Llama dhe për të ndërtuar aplikacione “agjentike” – aplikacione të mundësuara nga Llama që mund të ndërmarrin veprime në emër të një përdoruesi.
“[Ajo që] Ne kemi dëgjuar vazhdimisht nga zhvilluesit është një interes për të mësuar se si të vendosim [modelet Llama] në prodhim,” tha Srinivasan. “Pra, ne po përpiqemi të fillojmë t’u japim atyre një mori mjetesh dhe opsionesh të ndryshme.”
Në një letër të hapur të publikuar këtë mëngjes, CEO i Meta Mark Zuckerberg paraqet një vizion për të ardhmen në të cilën mjetet dhe modelet e AI arrijnë në duart e më shumë zhvilluesve në mbarë botën, duke siguruar që njerëzit të kenë akses në “përfitimet dhe mundësitë” e AI.
Është shprehur në mënyrë shumë filantropike, por e nënkuptuar në letër është dëshira e Zuckerberg që këto mjete dhe modele të jenë të prodhimit të Metës.
Meta është në garë për të kapur kompanitë si OpenAI dhe Anthropic, dhe po përdor një strategji të provuar dhe të vërtetë: jepni mjete falas për të nxitur një ekosistem dhe më pas shtoni ngadalë produkte dhe shërbime , disa të paguara, në krye. Shpenzimi i miliarda dollarëve për modelet që mund t’i komoditojë më pas ka gjithashtu efektin në uljen e çmimeve të konkurrentëve të Meta dhe përhapjen e gjerë të versionit të AI të kompanisë. Gjithashtu i lejon kompanisë të inkorporojë përmirësime nga komuniteti me burim të hapur në modelet e saj të ardhshme.
Llama sigurisht që ka vëmendjen e zhvilluesve. Meta pretendon se modelet Llama janë shkarkuar mbi 300 milionë herë dhe më shumë se 20,000 modele me prejardhje nga Llama janë krijuar deri më tani.
Mos bëni gabim, Meta po luan për mbajtjen. Ajo po shpenzon miliona për të lobuar rregullatorët për të arritur në shijen e saj të preferuar të AI gjeneruese “të hapur”. Asnjë nga modelet Llama 3.1 nuk i zgjidh problemet e pazgjidhshme me teknologjinë gjeneruese të inteligjencës artificiale të sotme, si tendenca e saj për të krijuar gjëra dhe për të rikthyer të dhëna problematike të trajnimit. Por ata avancojnë një nga qëllimet kryesore të Metës: të bëhen sinonim i AI gjeneruese.
Ka kosto për këtë. Në punimin kërkimor, bashkëautorët – duke i bërë jehonë komenteve të fundit të Zuckerberg – diskutojnë çështjet e besueshmërisë së energjisë me trajnimin e modeleve gjeneruese të AI të Meta-s.
“Gjatë trajnimit, dhjetëra mijëra GPU mund të rrisin ose ulin konsumin e energjisë në të njëjtën kohë, për shembull, për shkak të të gjitha GPU-ve që presin që pika e kontrollit ose komunikimi kolektiv të përfundojë, ose nisja ose mbyllja e të gjithë punës së trajnimit,” shkruajnë ata. . “Kur kjo ndodh, mund të rezultojë në luhatje të menjëhershme të konsumit të energjisë në të gjithë qendrën e të dhënave në rendin e dhjetëra megavat, duke shtrirë kufijtë e rrjetit të energjisë. Kjo është një sfidë e vazhdueshme për ne, teksa ne shkallëzojmë trajnimin për modelet e ardhshme, edhe më të mëdha të Llama.”