Meta rindez planet për të trajnuar AI duke përdorur postimet publike të përdoruesve të Mbretërisë së Bashkuar në Facebook dhe Instagram

Meta ka konfirmuar se po rifillon përpjekjet për të trajnuar sistemet e saj të AI duke përdorur postimet publike në Facebook dhe Instagram nga baza e saj e përdoruesve në Mbretërinë e Bashkuar.

Kompania pretendon se ka “inkorporuar reagime rregullatore” në një qasje të rishikuar “opt-out” për të siguruar që ajo të jetë “edhe më transparente”, siç e rrotullon postimi i saj në blog. Ajo po kërkon gjithashtu ta përshkruajë këtë lëvizje si duke u mundësuar modeleve të saj gjeneruese të AI të “reflektojnë kulturën, historinë dhe idiomën britanike”. Por është më pak e qartë se çfarë është saktësisht e ndryshme në lidhje me marrjen e fundit të të dhënave.
Nga java e ardhshme, Meta tha se përdoruesit në Mbretërinë e Bashkuar do të fillojnë të shohin njoftime brenda aplikacionit që shpjegojnë se çfarë po bën. Kompania më pas planifikon të fillojë të përdorë përmbajtje publike për të trajnuar AI-n e saj në muajt e ardhshëm – ose të paktën të bëjë trajnime për të dhënat kur një përdorues nuk ka kundërshtuar në mënyrë aktive përmes procesit që ofron Meta.
Njoftimi vjen tre muaj pasi kompania mëmë e Facebook ndërpreu planet e saj për shkak të presionit rregullator në Mbretërinë e Bashkuar, me Zyrën e Komisionerit të Informacionit (ICO) duke ngritur shqetësime se si Meta mund të përdorë të dhënat e përdoruesve në Mbretërinë e Bashkuar për të trajnuar algoritmet e saj gjeneruese të AI – dhe si po shkonte. për marrjen e pëlqimit të njerëzve. Komisioni Irlandez i Mbrojtjes së të Dhënave, rregullatori kryesor i Meta-s në Bashkimin Evropian (BE), gjithashtu kundërshtoi planet e Metës pasi mori reagime nga disa autoritete të mbrojtjes së të dhënave në të gjithë bllokun – nuk ka ende asnjë fjalë se kur, ose nëse, Meta do të rifillojë Përpjekjet e trajnimit të AI në BE.
Për kontekstin, Meta ka nxitur AI-në e saj nga përmbajtjet e krijuara nga përdoruesit në tregje si SHBA për disa kohë, por rregulloret gjithëpërfshirëse të privatësisë së Evropës kanë krijuar sfida për të – dhe për kompanitë e tjera të teknologjisë – që kërkojnë të zgjerojnë grupet e të dhënave të tyre të trajnimit në këtë mënyrë.
Pavarësisht ekzistencës së ligjeve të BE-së për privatësinë, në maj Meta filloi të njoftonte përdoruesit në rajon për një ndryshim të ardhshëm të politikës së privatësisë, duke thënë se do të fillonte të përdorte përmbajtje nga komentet, ndërveprimet me kompanitë, përditësimet e statusit dhe fotot dhe titrat e tyre të lidhura për AI trajnimi. Arsyet për ta bërë këtë, argumentoi ai, ishte se duhej të pasqyronte “gjuhët, gjeografinë dhe referencat e ndryshme kulturore të njerëzve në Evropë”.
Ndryshimet do të hynin në fuqi më 26 qershor, por njoftimi i Metës nxiti të drejtat e privatësisë jofitimprurëse noyb (aka “asnjë punë jote”) për të paraqitur një duzinë ankesash me vendet përbërëse të BE-së, duke argumentuar se Meta po shkelte aspekte të ndryshme të të dhënave të përgjithshme të bllokut. Rregullorja e Mbrojtjes (GDPR) – kuadri ligjor që mbështet ligjet kombëtare të privatësisë së Shteteve Anëtare të BE-së (dhe gjithashtu, ende, Aktin e Mbrojtjes së të Dhënave të Mbretërisë së Bashkuar).
Ankesat synonin përdorimin nga Meta të një mekanizmi të zgjedhjes për të autorizuar përpunimin kundrejt një përjashtimi – duke argumentuar se përdoruesve duhet t’u kërkohet leja e tyre në fillim, në vend që të ndërmarrin veprime për të refuzuar një përdorim të ri të informacionit të tyre. Meta ka thënë se po mbështetet në një bazë ligjore të përcaktuar në GDPR që quhet “ interesi legjitim ” (LI). Prandaj, ai pretendon se veprimet e tij janë në përputhje me rregullat, pavarësisht dyshimeve të ekspertëve të privatësisë se LI është një bazë e përshtatshme për një përdorim të tillë të të dhënave të njerëzve.
Meta ka kërkuar të mbështetet në këtë bazë ligjore edhe më parë për të justifikuar përpunimin e informacionit të përdoruesve evropianë për reklamat me mikro-target. Megjithatë, vitin e kaluar Gjykata e Drejtësisë së Bashkimit Evropian vendosi se nuk mund të përdoret në atë skenar, gjë që ngre dyshime në lidhje me përpjekjen e Metës për të shtyrë trajnimin e AI përmes vrimës së çelësit LI.
Fakti që Meta ka zgjedhur të nisë planet e tij në Britaninë e Madhe, në vend të BE-së, është diçka që tregon, duke qenë se Britania e Madhe nuk është më pjesë e Bashkimit Evropian. Ndërsa ligji i mbrojtjes së të dhënave në Mbretërinë e Bashkuar mbetet i bazuar në GDPR, vetë ICO nuk është më pjesë e të njëjtit klub të zbatimit rregullator dhe shpesh i bën goditjet e veta për zbatimin . Kohët e fundit , ligjvënësit e Mbretërisë së Bashkuar gjithashtu kanë luajtur me çrregullimin e regjimit të privatësisë së brendshme.
Një nga shtyllat e shumta të mosmarrëveshjes për qasjen e Metës herën e parë ishte procesi që u ofroi përdoruesve të Facebook dhe Instagram që të “përzgjidhnin” informacionin e tyre që përdorej për të trajnuar AI-të e tij.
Në vend që t’u jepte njerëzve një kuti kontrolli të drejtpërdrejtë “opt-in/out”, kompania i detyroi përdoruesit të hidheshin nëpër rrathë për të gjetur një formular kundërshtimi të fshehur pas klikimeve ose prekjeve të shumta, në të cilin moment ata u detyruan të deklaronin pse nuk dëshironin. të dhënat e tyre të përpunohen. Ata u informuan gjithashtu se është tërësisht në diskrecionin e Metës nëse kjo kërkesë do të respektohet. Edhe pse kompania pretendoi publikisht se do të respektonte çdo kërkesë.
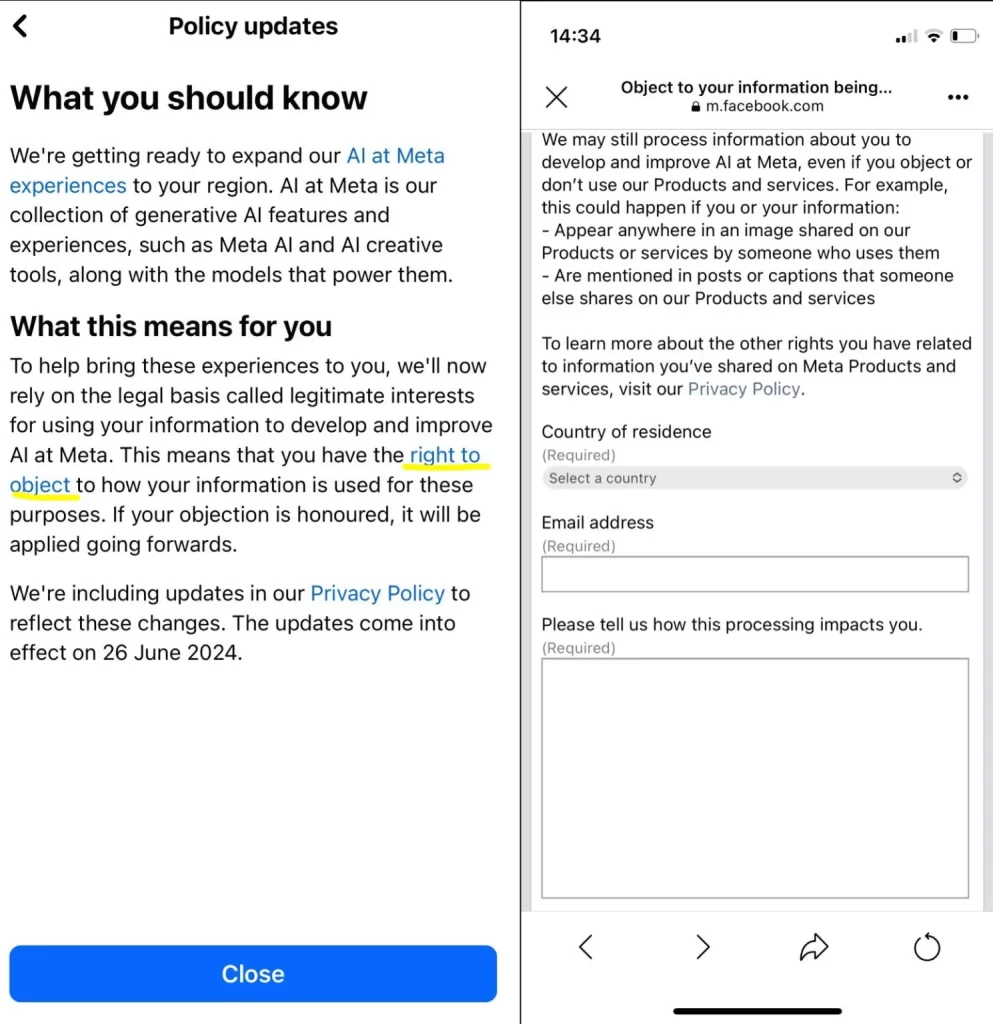
Këtë herë, Meta po i përmbahet qasjes së formularit të kundërshtimit, që do të thotë se përdoruesit do të duhet ende të aplikojnë zyrtarisht në Meta për t’i bërë të ditur se nuk duan që të dhënat e tyre të përdoren për të përmirësuar sistemet e saj të AI. Ata që kanë kundërshtuar më parë nuk do të duhet të paraqesin sërish kundërshtimet e tyre, për Meta. Por kompania thotë se e ka bërë më të thjeshtë formularin e kundërshtimit këtë herë, duke përfshirë reagimet nga ICO. Edhe pse ende nuk ka shpjeguar se si është më e thjeshtë. Pra, për momentin, gjithçka që kemi është pretendimi i Metës se procesi është më i lehtë.
Stephen Almond, drejtor i teknologjisë dhe inovacionit i ICO-së, tha se do të “monitorojë situatën” ndërsa Meta ecën përpara me planet e saj për të përdorur të dhënat e Mbretërisë së Bashkuar për trajnimin e modeleve të AI.
“I takon Metës të sigurojë dhe demonstrojë pajtueshmëri të vazhdueshme me ligjin për mbrojtjen e të dhënave”, tha Almond në një deklaratë. “Ne kemi qenë të qartë se çdo organizatë që përdor informacionin e përdoruesve të saj për të trajnuar modele gjeneruese të AI [duhet] të jetë transparente për mënyrën se si përdoren të dhënat e njerëzve. Organizatat duhet të ndjekin udhëzimet tona dhe të vendosin masa mbrojtëse efektive përpara se të fillojnë të përdorin të dhënat personale për trajnimin e modeleve, duke përfshirë ofrimin e një rruge të qartë dhe të thjeshtë për përdoruesit për të kundërshtuar përpunimin.”