Microsoft lëshon modele të reja të gjuhës dhe vizionit me burim të hapur Phi 3.5

Microsoft ka lëshuar tre modele të reja të AI me burim të hapur në serinë e tij Phi: mini-instruct, MoE-instruct dhe vision-instruct. Këto modele shkëlqejnë në arsyetimin LLM dhe mbështesin shumë gjuhë, por kanë kufizime në njohuritë dhe sigurinë faktike.
E krijuar për përdorim komercial dhe shkencor, seria Phi në përgjithësi synon të krijojë modele shumë efikase të AI duke përdorur të dhëna trajnimi me cilësi të lartë, megjithëse Microsoft nuk ka ndarë ende detaje rreth procesit të trajnimit për Phi-3.5.
Për modelin e vizionit, kompania thotë se përdori “të dhëna sintetike të krijuara rishtazi, “të ngjashme me tekstet shkollore” për qëllimin e mësimdhënies së matematikës, kodimit, arsyetimit me sens të përbashkët, njohurive të përgjithshme të botës”, përveç të tjerave me cilësi të lartë dhe të dhëna të filtruara.
Microsoft thotë se këto modele të reja janë ideale për aplikacione me burime të kufizuara, skenarë të ndjeshëm ndaj kohës dhe detyra që kërkojnë arsyetim të fortë logjik brenda aftësive të një LLM.
Modeli Phi-3.5-mini-instruct , me 3.8 miliardë parametra, është optimizuar për mjedise me burime të ulëta. Pavarësisht nga madhësia e tij e vogël, ai performon mirë në standardet, veçanërisht për detyrat shumëgjuhëshe.
Modeli Phi 3.5 MoE-instruct ka 16 ekspertë, secili me 3.8 miliardë parametra, për një total prej 60.8 miliardë. Megjithatë, vetëm 6.6 miliardë parametra janë aktivë kur përdoren dy ekspertë, gjë që mjafton për të përputhur modele më të mëdha në të kuptuarit e gjuhës dhe matematikë, dhe për të tejkaluar disa në detyrat e arsyetimit.
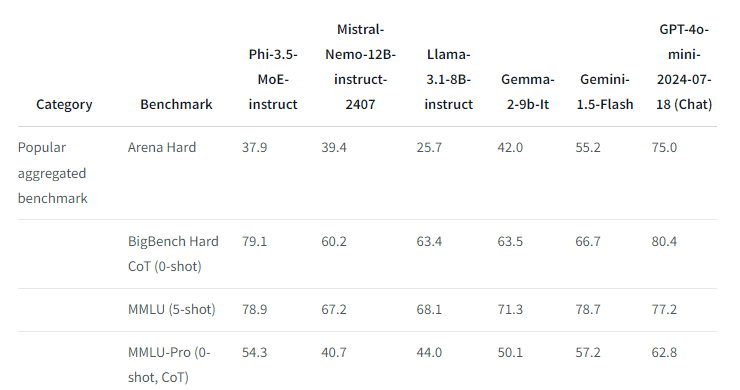
Shpesh është afër performancës GPT-4o-mini, por mbani në mend se këto janë vetëm standarde, dhe fjala në rrugë është se modelet Phi kanë treguar performancë nën nivelin e botës reale.
Modeli Phi-3.5-vision-instruct , një sistem multimodal me 4.2 miliardë parametra, mund të përpunojë tekstin dhe imazhet. Është i përshtatshëm për detyra të tilla si të kuptuarit e imazhit, OCR dhe të kuptuarit e diagrameve. Ai tejkalon modelet me madhësi të ngjashme në standarde dhe konkurron me modelet më të mëdha në përpunimin me shumë imazhe dhe përmbledhjen e videos.
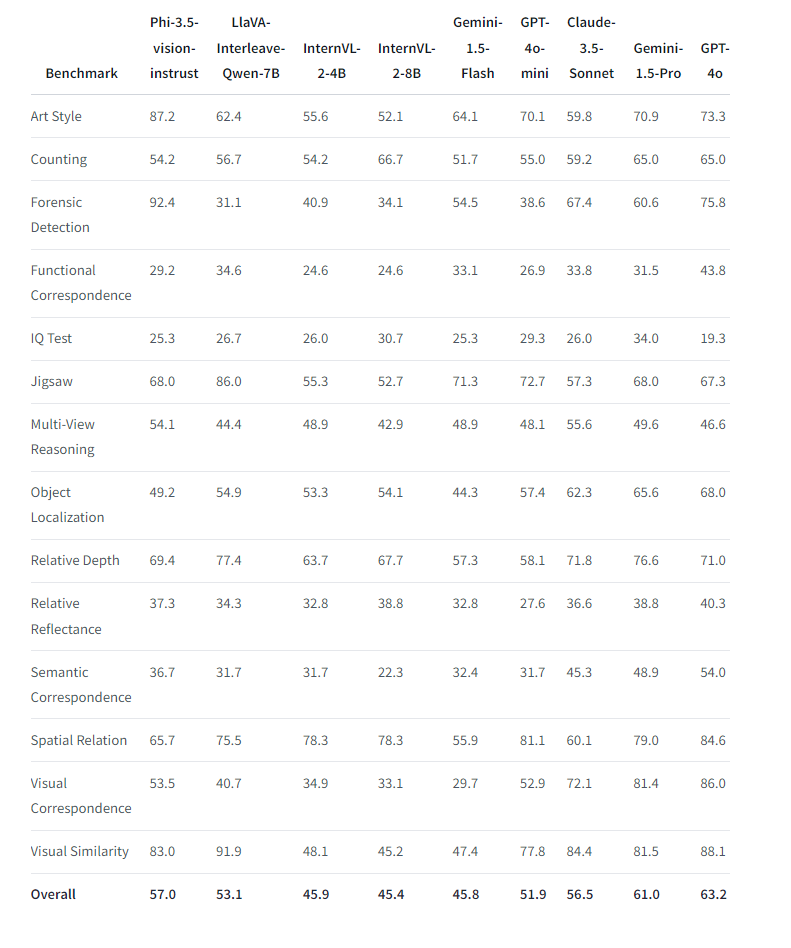
Të gjitha modelet Phi 3.5 mbështesin një gjatësi konteksti deri në 128,000 token, duke e bërë atë të dobishëm për përmbledhje të gjata dokumentesh dhe rikthim shumëgjuhësh të kontekstit. Ai tejkalon modelet Gemma 2 të Google, të cilat janë të kufizuara në 8000 tokena.