Modelet kryesore të OpenAI ranë nga 75% në vetëm 4% në testin sfidues të ri ARC-AGI-2

Standardi i ri i inteligjencës artificiale ARC-AGI-2 rrit ndjeshëm shiritin për testet e AI. Ndërsa njerëzit mund t’i zgjidhin lehtësisht detyrat, madje edhe sistemet shumë të zhvilluara të AI si OpenAI o3 dështojnë qartë.
François Chollet dhe ekipi i tij kanë lëshuar ARC-AGI-2, një version të ri të standardit të tyre të AI. Ndërsa ndjek të njëjtin format si ARC-AGI-1, testi i ri ofron atë që ekipi thotë se është një sinjal më i fortë për matjen e inteligjencës së vërtetë të sistemit.
“Është një standard i AI i krijuar për të matur inteligjencën e përgjithshme fluide, jo aftësitë e memorizuara – një grup detyrash të paparë kurrë më parë që njerëzit i kanë të lehta, por AI aktuale ka vështirësi,” shpjegoi Chollet në X. Standardi përqendrohet në aftësitë që sistemeve aktuale të AI ende u mungojnë: interpretimi i simboleve, zbatimi i rregullave kompozicionale me shumë hapa, aplikimi i rregullave kompozicionale me shumë hapa.
Standardi është kalibruar plotësisht ndaj performancës njerëzore. Në seancat e testimit të drejtpërdrejtë me 400 pjesëmarrës, u mbajtën vetëm detyrat që shumë njerëz mund t’i zgjidhnin me besueshmëri. Testuesit mesatarë arrijnë 60 përqind pa trajnim paraprak, ndërsa një panel prej 10 ekspertësh arriti 100 përqind.
Rezultatet fillestare të testimit paraqesin një pamje të kthjellët. Edhe sistemet më të avancuara performojnë dobët. Modelet e gjuhës së pastër si GPT-4.5, Claude 3.7 Sonnet dhe Gemini 2 shënojnë zero përqind. Modelet me arsyetim bazë të zinxhirit të mendimit si Claude 3.7 Sonnet Thinking, R1 dhe o3-mini menaxhojnë vetëm zero deri në një përqind.

Modeli o3-low i OpenAI tregoi një rënie veçanërisht të dukshme të performancës, duke rënë nga 75.7 përqind në ARC-AGI-1 në afërsisht 4 përqind në ARC-AGI-2. Fituesit e Çmimit ARC 2024, Team ARChitects, pësuan një rënie të ngjashme nga 53.5 përqind në 3 përqind.
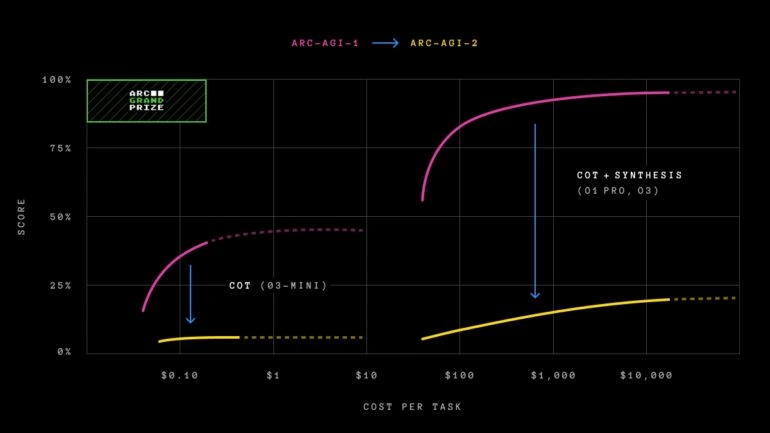
Disa modele, veçanërisht o3-high, ende nuk kanë testime të gjera ose mbështeten në parashikime, që do të thotë se performanca e tyre aktuale mund të jetë më e lartë.
ARC-AGI-2 prezanton një metrikë të re të efikasitetit. Standardi tani vlerëson jo vetëm aftësinë për zgjidhjen e problemeve, por edhe sa me efikasitet përdoret kjo aftësi. Kostoja shërben si metrikë fillestare, duke mundësuar krahasime të drejtpërdrejta midis performancës njerëzore dhe AI.