Modelet kufitare dështojnë në ‘provimin e fundit të njerëzimit’, por ekspertët pyesin nëse ka rëndësi

Një ekip ndërkombëtar kërkimor ka zhvilluar një standard të ri që zbulon kufizimet aktuale të LLM-ve. Edhe modelet më të avancuara dështojnë në 90 për qind të detyrave – tani për tani.
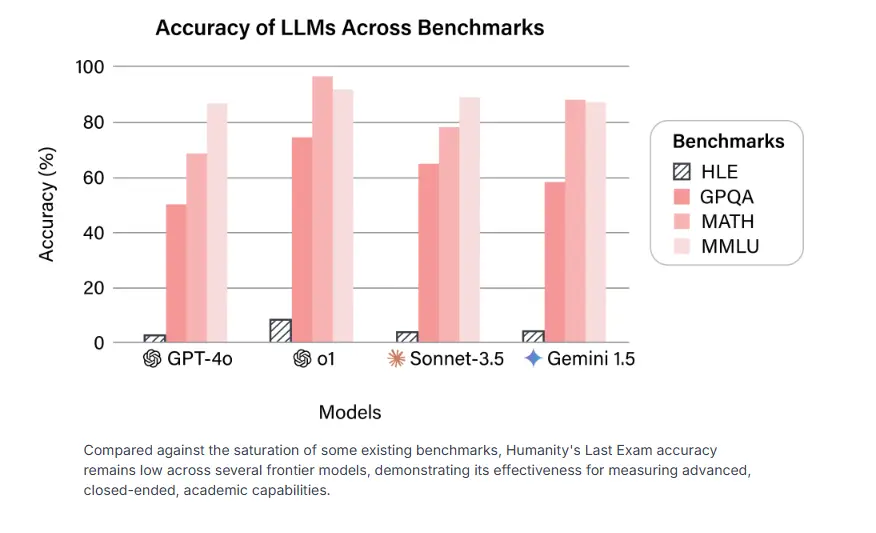
Testi, i quajtur “Provimi i fundit i njerëzimit” (HLE), përfshin 3,000 pyetje në më shumë se 100 fusha të specializuara, me 42 përqind të fokusuar në matematikë. Gati 1000 ekspertë nga 500 institucione në 50 vende kontribuan në zhvillimin e tij.
Studiuesit filluan me 70,000 pyetje dhe ia paraqitën ato modeleve kryesore të AI. Nga këto, 13,000 pyetje rezultuan shumë të vështira për sistemet e AI. Këto pyetje më pas u rafinuan dhe u rishikuan nga ekspertë njerëzorë, të cilët paguheshin midis 500 dhe 5000 dollarë për kontribute me cilësi të lartë. 3000 pyetje hynë në grupin e të dhënave.
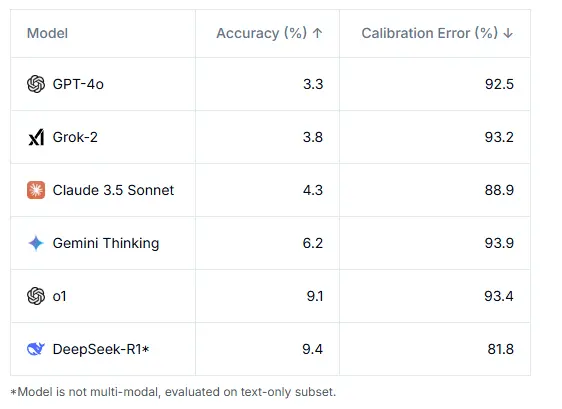
Rezultatet nuk janë lajkatare. Edhe modelet më të sofistikuara të inteligjencës artificiale luftojnë në këtë pikë referimi. GPT-4o zgjidh saktë vetëm 3.3 përqind të detyrave, ndërsa o1 i OpenAI arrin 9.1 përqind dhe Gemini 6.2 përqind. Vështirësia e testit është pjesërisht nga dizajni, pasi vetëm pyetjet që fillimisht penguan këto modele të AI u përfshinë në versionin përfundimtar.
Një nga gjetjet më shqetësuese është se sa keq sistemet e AI vlerësojnë aftësitë e tyre. Modelet tregojnë besim ekstrem të tepruar, me gabime kalibrimi që kalojnë 80 përqind – që do të thotë se zakonisht janë shumë të sigurt për përgjigjet e tyre të gabuara. Kjo shkëputje midis besimit dhe saktësisë e bën veçanërisht sfiduese punën me sistemet gjeneruese të AI.
Projekti doli nga një bashkëpunim midis Qendrës për Sigurinë e AI dhe Scale AI. Dan Hendrycks, i cili drejton Qendrën për Sigurinë e AI dhe këshillon startup-in xAI të Elon Musk, kryesoi nismën.
Jo të gjithë e mbështesin këtë qasje akademike për vlerësimin e AI. Subbarao Kambhampati, ish-president i Shoqatës për Avancimin e Inteligjencës Artificiale, argumenton se thelbi i njerëzimit nuk kapet nga një provë statike, por më tepër nga aftësia jonë për të evoluar dhe për të trajtuar pyetje të paimagjinueshme më parë. Eksperti i AI Niels Rogge ndan këtë skepticizëm, duke sugjeruar se memorizimi i fakteve të paqarta nuk është aq i vlefshëm sa zhvillimi i aftësive praktike.
Ish-zhvilluesi i OpenAI Andrej Karpathy vëren se ndërsa standardet akademike janë të lehta për t’u krijuar dhe matur, testimi i aftësive vërtet të rëndësishme të AI – si zgjidhja e problemeve komplekse, të botës reale – rezulton shumë më sfiduese.
Ai i sheh këto rezultate të standardeve akademike si një version të ri të paradoksit të Moravec: sistemet e AI mund të shkëlqejnë në detyra komplekse të bazuara në rregulla si matematika, por shpesh luftojnë me probleme të thjeshta që njerëzit i zgjidhin pa mundim. Karpathy argumenton se testimi se sa mirë një sistem AI mund të funksionojë si praktikant do të ishte më i dobishëm për matjen e progresit të përgjithshëm të AI sesa aftësia e tij për t’iu përgjigjur pyetjeve akademike.