Modeli i arsyetimit AI Hunyuan T1 i Tencent rivalizon DeepSeek në performancë dhe çmim

Tencent Holdings ka zbuluar një model të ri arsyetimi të inteligjencës artificiale (AI), Hunyuan T1, që rivalizonR1 të DeepSeek si në performancë ashtu edhe në çmim.

Oferta më e fundit e gjigantit të teknologjisë kineze, e lançuar të premten, përdor të mësuarit përforcues në shkallë të gjerë, një teknikë e përdorur gjithashtu nga DeepSeek në modelin e tij të arsyetimit R1, i cili u lançua në janar.
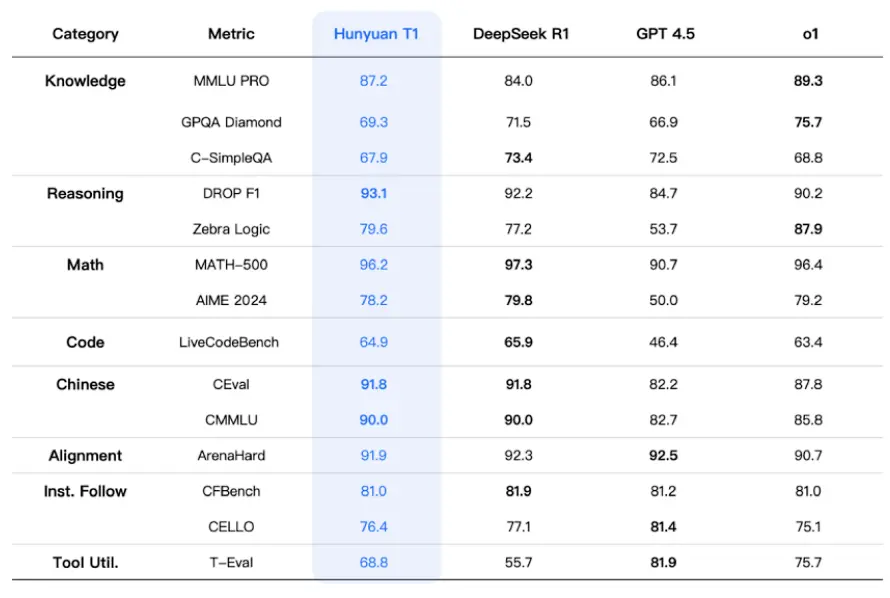
Lëshimi është një version zyrtar i modelit pas një versioni beta të T1-preview në chatbotin e tij Yuanbao. Ai shënoi 87.2 pikë në standardin Massive Multitask Language Understanding (MMLU) Pro, një test që vlerëson njohuritë e një modeli. Kjo i kapërceu 84 pikët e DeepSeek-R1, por pasoi 89.3 pikët e arritura nga o1 e OpenAI, modeli i arsyetimit që prodhuesi ChatGPT lançoi në dhjetor.
T1 ka arritur rezultate të larta edhe në standarde të tjera, duke përfshirë 78.2 në Provimin Amerikan të Matematikës Ftesore (AIME) 2024, pak pas 79.8 të R1 dhe 79.2 të o1. Për sa i përket aftësive të gjuhës kineze, T1 shkëlqeu me 91.8 pikë në vlerësimin e grupit C-Eval, i njëjti rezultat si R1 dhe më i mirë se 87.8 i o1, sipas Tencent.
Ai gjithashtu rivalizon DeepSeek në çmim, i cili ka qenë një avantazh kryesor për start-up-in popullor kinez. T1 tarifon 1 juan (0,14 USD) për 1 milion argumente hyrje, ndërsa prodhimi kushton 4 juanë për milion argumente. Norma e hyrjes është në përputhje me R1, i cili tarifon 1 juan për milion argumente gjatë orëve të ditës dhe vetëm 0,25 juanë gjatë natës. Çmimi i prodhimit është gjithashtu i krahasueshëm, duke pasur parasysh normën e ditës të R1 prej 16 juanë për milion argumente, e cila bie në 4 juanë brenda natës.
Tencent pretendoi se ishte i pari në industri që adoptoi një arkitekturë hibride që kombinonte Transformer dhe Mamba të Google, të zhvilluara nga Universiteti Carnegie Mellon dhe Universiteti Princeton. Krahasuar me arkitekturën e pastër të Transformer-it, qasja hibride “ul ndjeshëm kostot e trajnimit dhe konkluzionit” duke ulur përdorimin e kujtesës, sipas gjigantit të teknologjisë kineze.
Kompania shpalli T1 si “duke reduktuar konsumin e burimeve duke siguruar aftësinë për të kapur informacione me tekst të gjatë”, i cili ofron një rritje 200 për qind në shpejtësinë e dekodimit.
Blogu teknologjik NCJRYDS, i shkruar nga një ish -ekspert i të dhënave të mëdha të JD.com, testoi T1 dhe R1 në të njëjtat detyra dhe lejoi modelet e tjera të gjuhës së madhe, duke përfshirë Anthropic’s Claude dhe ChatGPT të OpenAI, të vlerësojnë rezultatet. Modelja e Tencent e humbi konkursin në kompozimin e një poezie të lashtë kineze, por ia kaloi DeepSeek në interpretimin e një fjale kineze në kontekste të ndryshme.
GoPlayAI, një tjetër blog, i dha modelit Tencent katër pyetje matematikore, dhe më e vështira e kishte gabim pasi kaloi pesë minuta për të.
Tencent, e cila operon aplikacionin më të madh të mediave sociale në Kinë, WeChat dhe biznesin më të madh në botë të lojërave video sipas të ardhurave, po e pozicionon AI si një rrymë të re kryesore të të ardhurave. Kompania ka integruar DeepSeek-R1 në platformën e saj cloud dhe chatbot Yuanbao, duke ofruar një alternativë krahas modeleve të saj Hunyuan.
Kryetari dhe CEO i Tencent Pony Ma Huateng tha në fillim të kësaj jave se ai “adhuron” DeepSeek për krijimin e “një produkti të pavarur, me të vërtetë me burim të hapur dhe falas”.
Ma tha se Tencent ka miratuar një strategji “me dy bërthama” për AI që përdor si DeepSeek ashtu edhe modelet e veta Yuanbao, duke ndjekur një qasje të ngjashme me mënyrën se si ka dominuar industrinë e lojërave video duke promovuar tituj të vetë-zhvilluar dhe ata nga studiot e pavarura.