Nvidia lëshon LLM falas që përputhen me GPT-4 në disa standarde

Nvidia ka lëshuar Nemotron-4 340B, një tubacion me burim të hapur për gjenerimin e të dhënave sintetike. Modeli i gjuhës është krijuar për të ndihmuar zhvilluesit të krijojnë grupe të dhënash me cilësi të lartë për trajnimin dhe rregullimin e modeleve të mëdha gjuhësore (LLM) për aplikacione komerciale.
Familja Nemotron-4 340B përbëhet nga një model bazë, një model instruksioni dhe një model shpërblimi, të cilat së bashku formojnë një tubacion për gjenerimin e të dhënave sintetike që mund të përdoren për të trajnuar dhe rafinuar LLM-të. Modeli bazë i Nemotron u trajnua me 9 trilion argumente.
Të dhënat sintetike imitojnë vetitë e të dhënave reale dhe mund të përmirësojnë cilësinë dhe sasinë e të dhënave, gjë që është veçanërisht e rëndësishme kur qasja në grupe të dhënash të mëdha, të ndryshme dhe me shënime është e kufizuar.
Sipas Nvidia, modeli Nemotron-4 340B Instruct gjeneron të dhëna të ndryshme sintetike që mund të përmirësojnë performancën dhe qëndrueshmërinë e LLM-ve të personalizuara në fusha të ndryshme aplikimi si kujdesi shëndetësor, financa, prodhimi dhe shitja me pakicë.
Modeli Nemotron-4 340B Reward mund të përmirësojë më tej cilësinë e të dhënave të gjeneruara nga AI duke filtruar përgjigjet me cilësi të lartë.
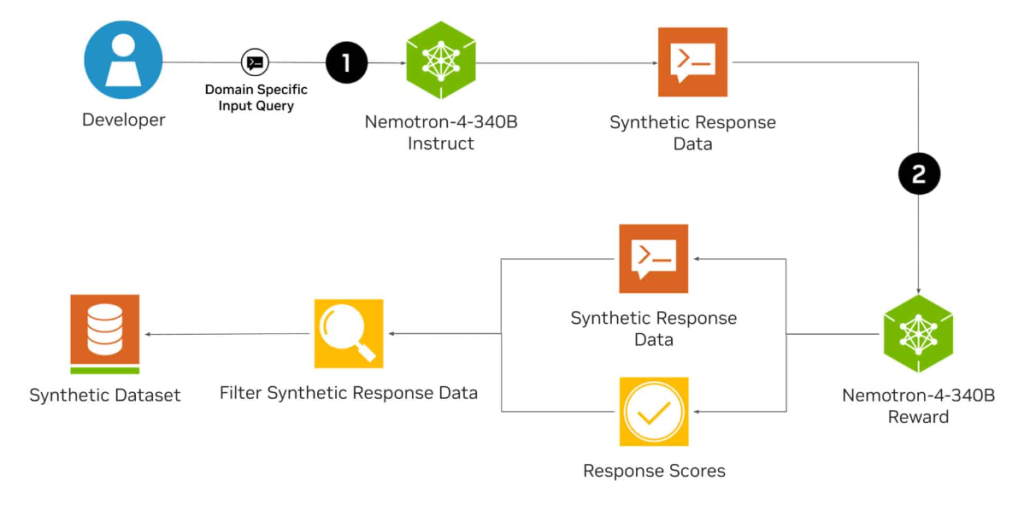
98 për qind e të dhënave të trajnimit të përdorura për të rregulluar modelin Instruct janë sintetike dhe janë krijuar duke përdorur tubacionin e Nvidia.
Në standardet si MT-Bench, MMLU, GSM8K, HumanEval dhe IFEval, modeli Instruct në përgjithësi performon më mirë se modelet e tjera me burim të hapur si Llama-3-70B-Instruct, Mixtral -8x22B-Instruct-v0.1 dhe Qwen-2-72B-Instruct, dhe në disa teste, madje tejkalon GPT-4o.
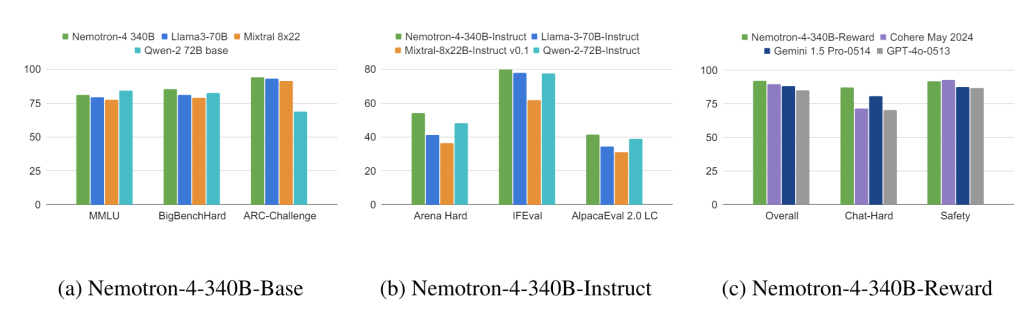
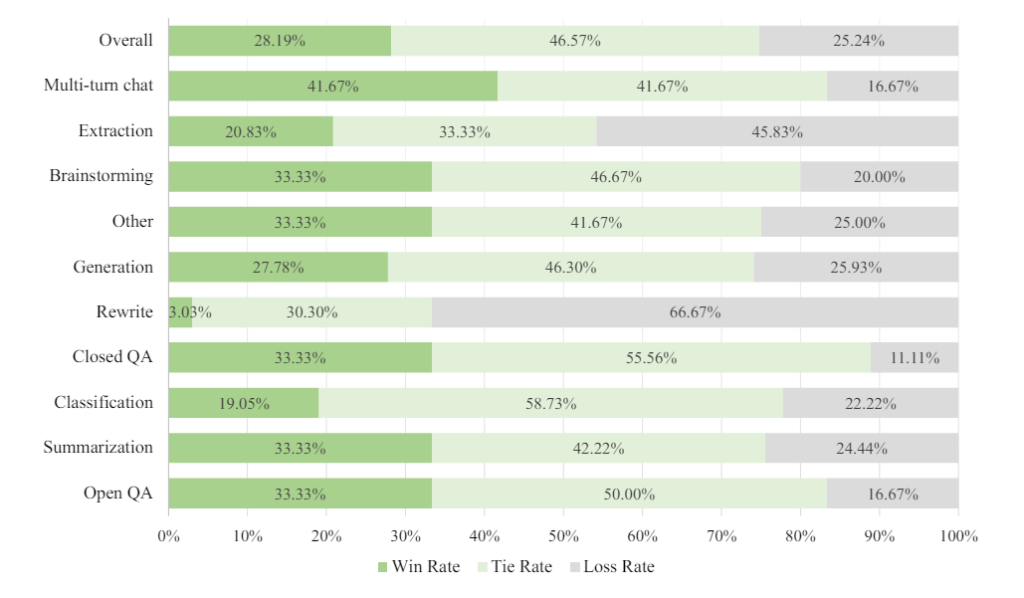
Ai gjithashtu funksionon i krahasueshëm ose më i mirë se GPT-4 -1106 i OpenAI në vlerësimin njerëzor për detyra të ndryshme teksti, si përmbledhjet dhe stuhi mendimesh. Standardet e detajuara janë të disponueshme në raportin teknik. Sipas Nvidia, modelet funksionojnë në sistemet DGX H100 me tetë GPU me saktësi FP8.
Modelet janë optimizuar për konkluzion me kornizën me burim të hapur Nvidia NeMo dhe bibliotekën Nvidia TensorRT-LLM. Nvidia i bën ato të disponueshme nën licencën e saj të modelit të hapur, e cila gjithashtu lejon përdorimin komercial. Të gjitha të dhënat janë të disponueshme në Huggingface.