OpenAI thotë se GPT-5 krahasohet me njerëzit në një gamë të gjerë punësh

OpenAI publikoi të enjten një pikë referimi të re që teston se si performojnë modelet e saj të inteligjencës artificiale krahasuar me profesionistët njerëzorë në një gamë të gjerë industrish dhe vendesh pune. Testi, GDPval, është një përpjekje e hershme për të kuptuar se sa afër janë sistemet e OpenAI për t’i tejkaluar njerëzit në punë me vlerë ekonomikisht – një pjesë kyçe e misionit themelues të kompanisë për të zhvilluar inteligjencën e përgjithshme artificiale, ose AGI.

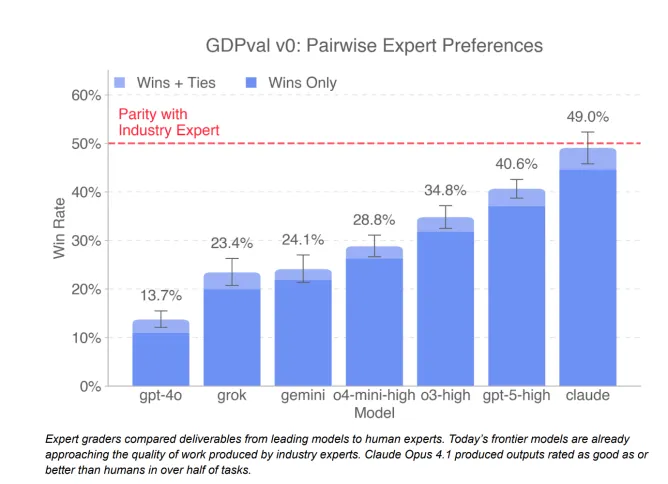
OpenAI thotë se ka zbuluar se modeli i saj GPT-5 dhe Claude Opus 4.1 i Anthropic “po i afrohen tashmë cilësisë së punës së prodhuar nga ekspertët e industrisë”.
Kjo nuk do të thotë që modelet e OpenAI do të fillojnë t’i zëvendësojnë njerëzit në punët e tyre menjëherë. Pavarësisht parashikimeve të disa CEO-ve se IA do t’ua marrë punët njerëzve vetëm brenda pak vitesh, OpenAI pranon se GDPval sot mbulon një numër shumë të kufizuar detyrash që njerëzit bëjnë në punët e tyre të vërteta. Megjithatë, kjo është një nga mënyrat më të fundit se si kompania po mat progresin e IA-së drejt këtij momenti historik.
GDPval bazohet në nëntë industri që kontribuojnë më shumë në produktin e brendshëm bruto të Amerikës, duke përfshirë fusha të tilla si kujdesi shëndetësor, financat, prodhimi dhe qeveria. Testi i referencës teston performancën e një modeli të inteligjencës artificiale në 44 profesione midis këtyre industrive, duke filluar nga inxhinierët e softuerëve te infermierët dhe gazetarët.
Për versionin e parë të testit të OpenAI, GDPval-v0, OpenAI u kërkoi profesionistëve me përvojë të krahasonin raportet e gjeneruara nga IA me ato të prodhuara nga profesionistë të tjerë dhe më pas të zgjidhnin më të mirin. Për shembull, një kërkesë u kërkoi bankierëve të investimeve të krijonin një peizazh konkurrues për industrinë e shpërndarjes së kilometrit të fundit dhe t’i krahasonin ato me raportet e gjeneruara nga IA. OpenAI më pas mesatarizon “shkallën e fitores” së një modeli IA kundrejt raporteve njerëzore në të 44 profesionet.
Për GPT-5-high, një version i përmirësuar i GPT-5 me fuqi shtesë llogaritëse, kompania thotë se modeli i IA-së u rendit si më i mirë ose në të njëjtin nivel me ekspertët e industrisë në 40.6% të rasteve.
OpenAI testoi gjithashtu modelin Claude Opus 4.1 të Anthropic, i cili u rendit më i mirë ose në të njëjtin nivel me ekspertët e industrisë në 49% të detyrave. OpenAI thotë se beson që Claude mori një rezultat kaq të lartë për shkak të tendencës së tij për të krijuar grafika të këndshme, në vend të performancës së pastër.
Vlen të përmendet se shumica e profesionistëve që punojnë bëjnë shumë më tepër sesa thjesht i paraqesin raportet e kërkimit shefit të tyre, gjë që është e gjitha për të cilën teston GDPval-v0. OpenAI e pranon këtë dhe thotë se planifikon të krijojë teste më të fuqishme në të ardhmen që mund të marrin në konsideratë më shumë industri dhe rrjedha pune interaktive.
Megjithatë, kompania e sheh progresin në GDPval si të dukshëm.
Në një intervistë me TechCrunch, kryeekonomisti i OpenAI, Dr. Aaron Chatterji, tha se rezultatet e GDVval sugjerojnë që njerëzit në këto vende pune tani mund të përdorin modele të IA-së për të kaluar kohë në detyra më kuptimplote.
“[Meqenëse] modeli po bëhet më i mirë në disa nga këto gjëra”, thotë Chatterji, “njerëzit në ato vende pune tani mund ta përdorin modelin, gjithnjë e më shumë ndërsa aftësitë përmirësohen, për të liruar një pjesë të punës së tyre dhe për të bërë gjëra potencialisht me vlerë më të lartë.”
Udhëheqësja e vlerësimeve të OpenAI, Tejal Patwardhan, i thotë TechCrunch se është e inkurajuar nga shkalla e progresit në GDPval. Modeli GPT-4o i OpenAI shënoi vetëm 13.7% (fitore dhe barazime kundrejt njerëzve), i cili u publikua afërsisht 15 muaj më parë. Tani GPT-5 shënon pothuajse trefishin e kësaj, një trend që Patwardhan pret të vazhdojë.
Silicon Valley ka një gamë të gjerë standardesh që përdor për të matur progresin e modeleve të IA-së dhe për të vlerësuar nëse një model i caktuar është i nivelit më të lartë. Ndër më të njohurit janë AIME 2025 (një test me probleme matematikore konkurruese) dhe GPQA Diamond (një test me pyetje shkencore në nivel doktorature). Megjithatë, disa modele të IA-së po i afrohen ngopjes në disa nga këto standarde, dhe shumë studiues të IA-së kanë përmendur nevojën për teste më të mira që mund të matin aftësinë e IA-së në detyrat e botës reale.
Pikat referuese si GDPval mund të bëhen gjithnjë e më të rëndësishme në atë diskutim, pasi OpenAI argumenton se modelet e saj të inteligjencës artificiale janë të vlefshme për një gamë të gjerë industrish. Por OpenAI mund të ketë nevojë për një version më gjithëpërfshirës të testit për të thënë përfundimisht se modelet e saj të inteligjencës artificiale mund t’i tejkalojnë njerëzit.