OpenAI zbulon o1 një model që mund të kontrollojë vetë faktet

Prodhuesi i ChatGPT OpenAI ka njoftuar lëshimin e tij të ardhshëm të madh të produktit: Një model gjenerues i AI me emrin e koduar Strawberry, i quajtur zyrtarisht OpenAI o1.
Për të qenë më të saktë, o1 është në fakt një familje modelesh. Dy janë të disponueshme të enjten në ChatGPT dhe nëpërmjet API-së së OpenAI: o1-preview dhe o1-mini, një model më i vogël dhe më efikas që synon gjenerimin e kodit.
Do të duhet të abonoheni në ChatGPT Plus ose Team për të parë o1 në klientin ChatGPT. Përdoruesit e ndërmarrjeve dhe arsimit do të kenë akses në fillim të javës së ardhshme.
Vini re se përvoja e O1 chatbot është mjaft e thjeshtë për momentin. Ndryshe nga GPT-4o, paraardhësi i o1, o1 ende nuk mund të shfletojë ueb ose të analizojë skedarët. Modeli ka veçori të analizës së imazhit, por ato janë çaktivizuar në pritje të testimit shtesë. Dhe o1 është me normë të kufizuar; Kufijtë javor janë aktualisht 30 mesazhe për o1-preview dhe 50 për o1-mini.
Në një tjetër anë negative, o1 është i shtrenjtë. Shumë e shtrenjtë. Në API, o1-preview është 15 dollarë për 1 milion shenja hyrëse dhe 60 dollarë për 1 milion argumente dalëse. Kjo është 3 herë kostoja kundrejt GPT-4o për hyrjen dhe 4 herë kostoja për daljen. (“Tokens” janë copa të dhënash të papërpunuara; 1 milion është e barabartë me rreth 750,000 fjalë.)
OpenAI thotë se planifikon të sjellë akses o1-mini për të gjithë përdoruesit falas të ChatGPT, por nuk ka caktuar një datë lëshimi. Ne do ta mbajmë kompaninë në të.
OpenAI o1 shmang disa nga grackat e arsyetimit që zakonisht pengojnë modelet gjeneruese të AI, sepse mund të kontrollojë efektivisht vetveten duke shpenzuar më shumë kohë duke marrë parasysh të gjitha pjesët e një pyetjeje. Ajo që e bën o1 të “ndihet” cilësisht të ndryshëm nga modelet e tjera gjeneruese të AI është aftësia e tij për të “menduar” përpara se t’u përgjigjet pyetjeve, sipas OpenAI.
Kur i jepet kohë shtesë për të “menduar”, o1 mund të arsyetojë për një detyrë në mënyrë holistike – duke planifikuar përpara dhe duke kryer një sërë veprimesh për një periudhë të gjatë kohore që e ndihmojnë modelin të arrijë në një përgjigje. Kjo e bën o1 të përshtatshme për detyra që kërkojnë sintetizimin e rezultateve të nëndetyrave të shumta, si zbulimi i emaileve të privilegjuara në kutinë hyrëse të një avokati ose stuhia e ideve për një strategji marketingu produkti.
Në një seri postimesh në X të enjten, Noam Brown, një shkencëtar kërkimor në OpenAI, tha se “o1 është trajnuar me të mësuarit përforcues”. Kjo e mëson sistemin “të ‘mendojë’ përpara se të përgjigjet nëpërmjet një zinxhiri privat të mendimit” nëpërmjet shpërblimeve kur o1 merr përgjigjet e duhura dhe ndëshkon kur jo, tha ai.
Brown aludoi për faktin se OpenAI përdori një algoritëm të ri optimizimi dhe grup të dhënash trajnimi që përmban “të dhëna arsyetimi” dhe literaturë shkencore të përshtatura posaçërisht për detyrat e arsyetimit. “Sa më gjatë [o1] të mendojë, aq më mirë është,” tha ai.
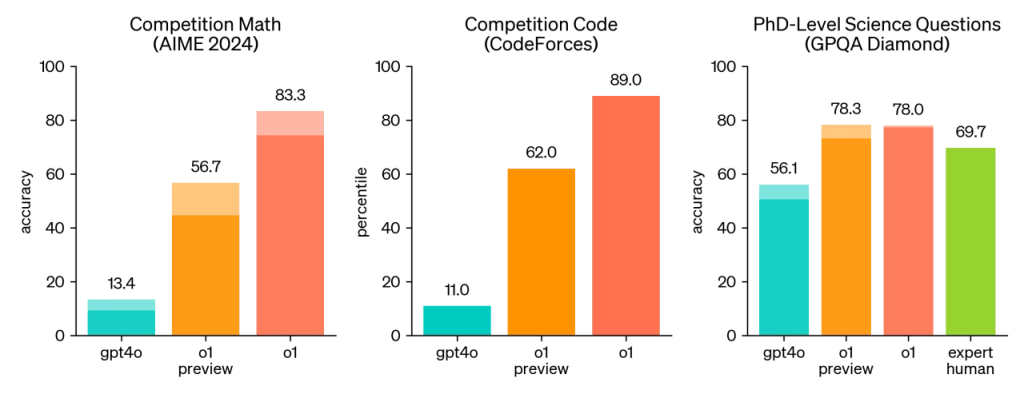
TechCrunch nuk iu ofrua mundësia për të testuar o1 përpara debutimit të tij; do ta marrim në dorë sa më shpejt të jetë e mundur. Por sipas një personi që kishte akses – Pablo Arredondo, zëvendës president në Thomson Reuters – o1 është më i mirë se modelet e mëparshme të OpenAI (p.sh., GPT-4o) në gjëra të tilla si analizimi i përmbledhjeve ligjore dhe identifikimi i zgjidhjeve për problemet në lojërat logjike LSAT.
“Ne e pamë atë duke trajtuar analiza më thelbësore, shumëplanëshe,” tha Arredondo për TechCrunch. “Testimi ynë i automatizuar tregoi gjithashtu përfitime ndaj një game të gjerë detyrash të thjeshta.”
Në një provim kualifikues për Olimpiadën Ndërkombëtare të Matematikës (IMO), një konkurs matematikor i shkollës së mesme, o1 zgjidhi saktë 83% të problemeve ndërsa GPT-4o zgjidhi vetëm 13%, sipas OpenAI. (Kjo është më pak mbresëlënëse kur mendoni se inteligjenca artificiale e fundit e Google DeepMind arriti një medalje argjendi në një ekuivalente me konkursin aktual të IMO.) OpenAI thotë gjithashtu se o1 arriti përqindjen e 89-të të pjesëmarrësve – më mirë se sistemi kryesor i DeepMind AlphaCode 2, për atë që ia vlen. — në raundet e sfidave të programimit online të njohur si Codeforces.
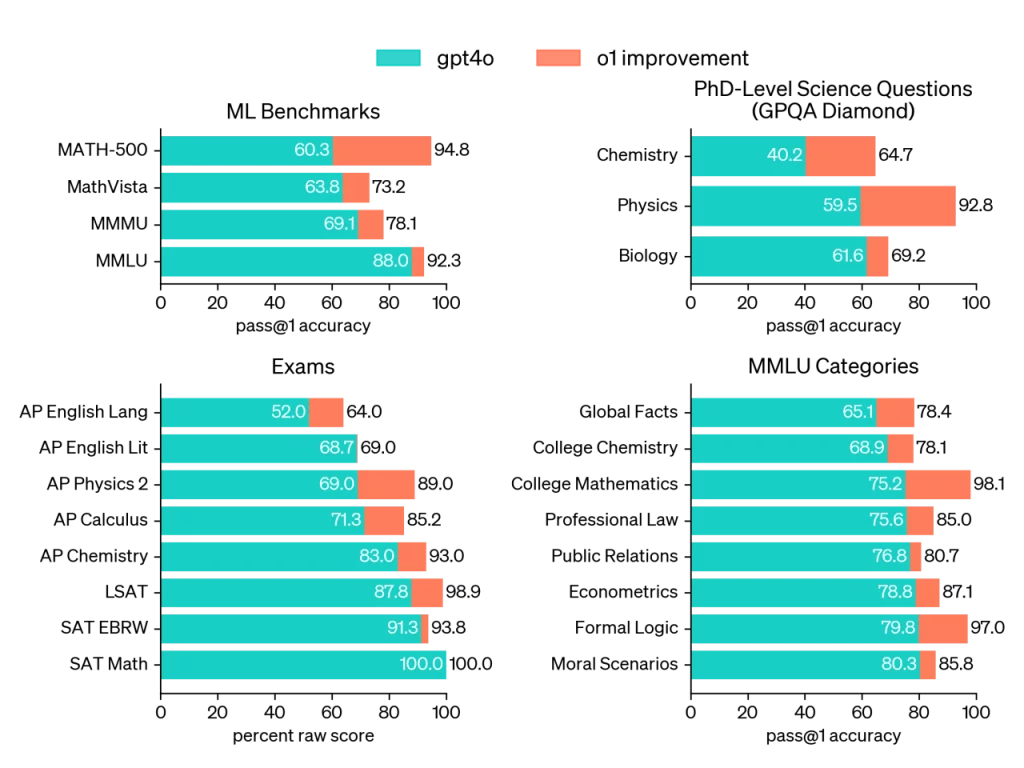
Në përgjithësi, o1 duhet të performojë më mirë në problemet në analizën e të dhënave, shkencën dhe kodimin, thotë OpenAI. (GitHub, i cili testoi o1 me asistentin e tij të kodimit të AI GitHub Copilot, raporton se modeli është i aftë në optimizimin e algoritmeve dhe kodit të aplikacionit.) Dhe, të paktën sipas standardeve të OpenAI, o1 përmirësohet mbi GPT-4o në aftësitë e tij shumëgjuhëshe, veçanërisht në gjuhë si arabishtja dhe koreane.
Ethan Mollick, një profesor i menaxhimit në Wharton, shkroi përshtypjet e tij për o1 pasi e përdori atë për një muaj në një postim në blogun e tij personal. Në një fjalëkryq sfidues, o1 ia doli mirë, tha ai – duke marrë të gjitha përgjigjet e sakta (pavarësisht nga halucinacionet e një të dhënë të re).
Tani, ka të meta.
OpenAI o1 mund të jetë më i ngadalshëm se modelet e tjera, në varësi të pyetjes. Arredondo thotë se o1 mund të marrë më shumë se 10 sekonda për t’iu përgjigjur disa pyetjeve; ai tregon progresin e tij duke shfaqur një etiketë për nëndetyrën aktuale që po kryen.
Duke pasur parasysh natyrën e paparashikueshme të modeleve gjeneruese të AI, o1 ka të ngjarë të ketë të meta dhe kufizime të tjera. Brown pranoi se o1 shkon në lojëra tik-tac-toe herë pas here, për shembull. Dhe në një dokument teknik, OpenAI tha se është dëgjuar reagime anekdotike nga testuesit se o1 ka tendencë të halucinojë (dmth., të krijojë gjëra të sigurta) më shumë se GPT-4o – dhe më rrallë e pranon kur nuk ka përgjigjen për një pyetje.
“Gabimet dhe halucinacionet ende ndodhin [me o1]”, shkruan Mollick në postimin e tij. “Ajo ende nuk është e përsosur.”
Ne pa dyshim do të mësojmë më shumë për çështjet e ndryshme me kalimin e kohës, dhe pasi të kemi një shans për të kaluar o1 përmes shtrydhësit vetë.
Do të ishim të harruar nëse nuk do të theksonim se OpenAI është larg nga shitësi i vetëm i AI që heton këto lloj metodash arsyetimi për të përmirësuar faktin e modelit.
Studiuesit e Google DeepMind publikuan kohët e fundit një studim që tregon se duke u dhënë në thelb modeleve më shumë kohë llogaritëse dhe udhëzime për të përmbushur kërkesat ndërsa ato bëhen, performanca e atyre modeleve mund të përmirësohet ndjeshëm pa ndonjë ndryshim shtesë.
Duke ilustruar ashpërsinë e konkurrencës, OpenAI tha se vendosi të mos shfaqte “zinxhirët e mendimeve” të papërpunuara të o1 në ChatGPT pjesërisht për shkak të “përparësisë konkurruese”. (Në vend të kësaj, kompania zgjodhi të shfaqte “përmbledhje të krijuara nga modeli” të zinxhirëve.)
OpenAI mund të dalë i pari nga porta me o1. Por duke supozuar se rivalët së shpejti do të ndjekin shembullin me modele të ngjashme, testi i vërtetë i kompanisë do të jetë që o1 të jetë gjerësisht i disponueshëm – dhe më i lirë.
Nga atje, ne do të shohim se sa shpejt OpenAI mund të japë versione të përmirësuara të o1. Kompania thotë se synon të eksperimentojë me modelet o1 që arsyetojnë për orë, ditë apo edhe javë për të rritur më tej aftësitë e tyre të arsyetimit.