Po sikur AI të mos përmirësohet përgjithmonë?
Digital human brain with connections.
Për vite me radhë, shumë vëzhgues të industrisë së AI kanë parë aftësitë në rritje të shpejtë të modeleve të reja të AI dhe kanë menduar për rritjet eksponenciale të performancës duke vazhduar edhe në të ardhmen. Megjithatë, kohët e fundit, një pjesë e optimizmit të “ligjit të shkallëzimit” të AI është zëvendësuar nga frika se ne mund të kemi arritur tashmë një pllajë në aftësitë e modeleve të mëdha gjuhësore të trajnuara me metoda standarde.

Një raport i fundjavës nga The Information përmblodhi në mënyrë efektive se si këto frika po manifestohen mes një numri të brendshëm në OpenAI. Studiuesit pa emër të OpenAI i thanë The Information se Orion, emri i koduar i kompanisë për lëshimin e modelit të saj të ardhshëm të plotë, po tregon një kërcim më të vogël të performancës se ai i parë midis GPT-3 dhe GPT-4 vitet e fundit. Për disa detyra, në fakt, modeli i ardhshëm “nuk është më i mirë se paraardhësi i tij”, sipas studiuesve të paidentifikuar të OpenAI të cituar në artikull.
Të hënën, bashkë-themeluesi i OpenAI, Ilya Sutskever, i cili u largua nga kompania në fillim të këtij viti, shtoi shqetësimet se LLM-të po goditnin një rrafshnaltë në atë që mund të përfitohej nga para-trajnimi tradicional. Sutskever i tha Reuters se “vitet 2010 ishin epoka e shkallëzimit”, ku hedhja e burimeve shtesë kompjuterike dhe të dhënave të trajnimit në të njëjtat metoda bazë të trajnimit mund të çonte në përmirësime mbresëlënëse në modelet e mëvonshme.
“Tani ne jemi kthyer në epokën e mrekullive dhe zbulimeve edhe një herë,” tha Sutskever për Reuters. “Të gjithë janë duke kërkuar për gjënë e radhës. Shkalla e gjësë së duhur ka më shumë rëndësi tani se kurrë.”
Një pjesë e madhe e problemit të trajnimit, sipas ekspertëve dhe të brendshëm të përmendur në këto dhe pjesë të tjera, është mungesa e të dhënave tekstuale të reja, cilësore për LLM-të e rinj për t’u trajnuar. Në këtë pikë, krijuesit e modeleve mund të kenë zgjedhur tashmë frutin më të ulët të varur nga vargjet e shumta të teksteve të disponueshme në internetin publik dhe librat e botuar.
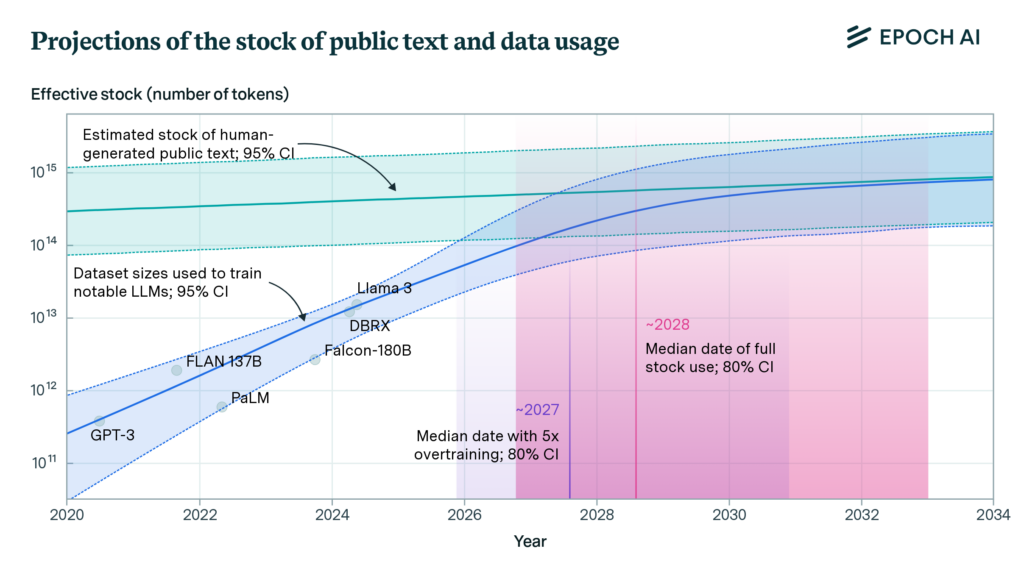
Shoqata kërkimore Epoch AI u përpoq të përcaktojë sasinë e këtij problemi në një punim në fillim të këtij viti , duke matur shkallën e rritjes së grupeve të të dhënave të trajnimit LLM kundrejt “stokut të vlerësuar të tekstit publik të krijuar nga njeriu”. Pas analizimit të këtyre tendencave, studiuesit vlerësojnë se “modelet e gjuhës do të përdorin plotësisht këtë stok [teksti publik të krijuar nga njeriu] midis 2026 dhe 2032”, duke lënë një pistë të vogël të çmuar për të hedhur më shumë të dhëna trajnimi për problemin.
OpenAI dhe kompanitë e tjera kanë filluar tashmë të orientohen drejt trajnimit mbi të dhënat sintetike (të krijuara nga modele të tjera) në një përpjekje për të kapërcyer këtë mur trajnimi që afrohet shpejt. Por ka një debat të rëndësishëm nëse këto lloj të dhënash artificiale mund të çojnë në një “kolaps modeli” kontekstual pas disa cikleve të trajnimit rekurziv.
Të tjerët janë duke i varur shpresat e tyre tek modelet e ardhshme të AI, duke u bazuar në përmirësime në aftësitë e arsyetimit dhe jo në njohuri të reja trajnimi. Por hulumtimet e fundit tregojnë se modelet aktuale të arsyetimit të “gjendjes së artit” mashtrohen lehtësisht nga harengat e kuqe. Studiues të tjerë po kërkojnë gjithashtu nëse një proces distilimi i njohurive mund të ndihmojë rrjetet e mëdha “mësues” të trajnojnë rrjetet “student” me një grup më të rafinuar informacioni cilësor.
Por nëse metodat aktuale të trajnimit LLM kanë filluar të përparojnë, zbulimi tjetër i madh mund të vijë përmes specializimit. Microsoft, për një, ka treguar tashmë njëfarë suksesi me të ashtuquajturat modele të gjuhëve të vogla që fokusohen në lloje specifike detyrash dhe problemesh. Ndryshe nga LLM-të e përgjithshme me të cilat jemi mësuar sot, ne mund të shohim AI të së ardhmes së afërt që fokusohen në specializime gjithnjë e më të ngushta, njëlloj si studentët e doktoraturës që krijojnë shtigje më të reja, më ezoterike për njohuritë njerëzore.