Studiuesit e Apple AI vënë në dyshim pretendimet e OpenAI në lidhje me aftësitë e arsyetimit të o1

Një studim i ri nga studiuesit e Apple, duke përfshirë shkencëtarin e njohur të AI, Samy Bengio, vë në pikëpyetje aftësitë logjike të modeleve të mëdha gjuhësore të sotme madje edhe “modelit të arsyetimit” të ri të OpenAI o1.
Ekipi, i udhëhequr nga Mehrdad Farajtabar, krijoi një mjet të ri vlerësimi të quajtur GSM-Symbolic. Ky mjet bazohet në grupin e të dhënave të arsyetimit matematik GSM8K dhe shton shabllone simbolike për të testuar më tërësisht modelet e AI.
Studiuesit testuan modele me burim të hapur si Llama, Phi, Gemma dhe Mistral, si dhe modele të pronarit, duke përfshirë ofertat më të fundit nga OpenAI. Rezultatet, të publikuara në arXiv, sugjerojnë se edhe modelet kryesore si GPT-4o dhe o1 e OpenAI nuk përdorin logjikë të vërtetë, por thjesht imitojnë modele.
Rezultatet tregojnë se rezultatet aktuale të saktësisë për GSM8K nuk janë të besueshme. Studiuesit gjetën ndryshime të mëdha në performancë: modeli Llama-8B, për shembull, shënoi midis 70 për qind dhe 80 për qind, ndërsa Phi-3 luhatej midis 75 për qind dhe 90 për qind. Për shumicën e modeleve, performanca mesatare në GSM-Symbolic ishte më e ulët se në GSM8K origjinale, thotë Farajtabar.
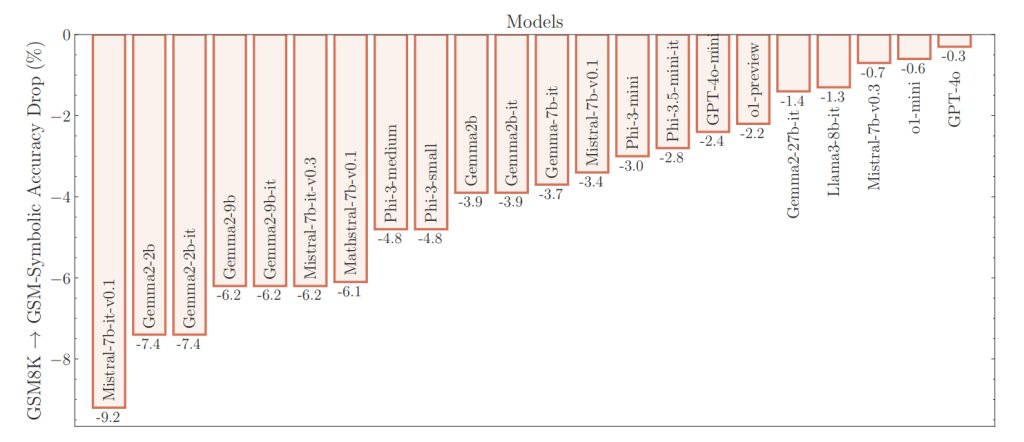
Eksperimenti me grupin e të dhënave GSM-NoOp ishte veçanërisht zbulues. Këtu, studiuesit shtuan një deklaratë të vetme në një problem teksti që dukej relevant, por nuk kontribuoi në argumentin e përgjithshëm.
Rezultati ishte një rënie në performancën për të gjitha modelet, duke përfshirë modelet o1 të OpenAI. “A do të ndryshonte rezultati i testit të matematikës së një nxënësi të shkollës me ~10% nëse do të ndryshonim vetëm emrat?” pyet në mënyrë retorike Farajtabar.

Farajtabar thekson se çështja e vërtetë është rritja dramatike e variancës dhe rënia e performancës pasi vështirësia e detyrës rritet vetëm pak. Për të trajtuar ndryshimin me vështirësi në rritje, ndoshta kërkon “më shumë të dhëna në mënyrë eksponenciale”.
Ndërsa seria OpenAI o1, e cila arrin pikët kryesore në shumë standarde, performon më mirë, ajo ende vuan nga luhatjet e performancës dhe bën “gabime budalla”, duke treguar të njëjtat dobësi themelore, sipas studiuesve. Ky zbulim mbështetet nga një tjetër studim i publikuar së fundmi.
“Në përgjithësi, ne nuk gjetëm prova të arsyetimit formal në modelet gjuhësore,” përfundon Farajtabar. “Sjellja e tyre shpjegohet më mirë nga përputhja e sofistikuar e modeleve.” Shkallëzimi i të dhënave, parametrave dhe llogaritjes do të çonte në përputhje më të mirë të modeleve, por “jo domosdoshmërisht arsyetues më të mirë”.