Tencent publikon me burim të hapur dy modele përkthimi me performancë të lartë
Gjigandi kinez i teknologjisë Tencent ka bërë të mundur që dy modele të specializuara përkthimi të jenë me kod të hapur, duke pretenduar se ato i tejkalojnë mjetet e vendosura si Google Translate në testet ndërkombëtare.

Në WMT2025, një seminar i madh ku ekipet kërkimore krahasojnë sistemet e përkthimit, modelet e reja të Tencent, Hunyuan MT 7B dhe Hunyuan MT Chimera 7B, zunë vendin e parë në 30 nga 31 çifte gjuhësh të testuara. Seminari mbi Përkthimin Automatik (WMT) është një nga ngjarjet kryesore për vlerësimin e modeleve të përkthimit.
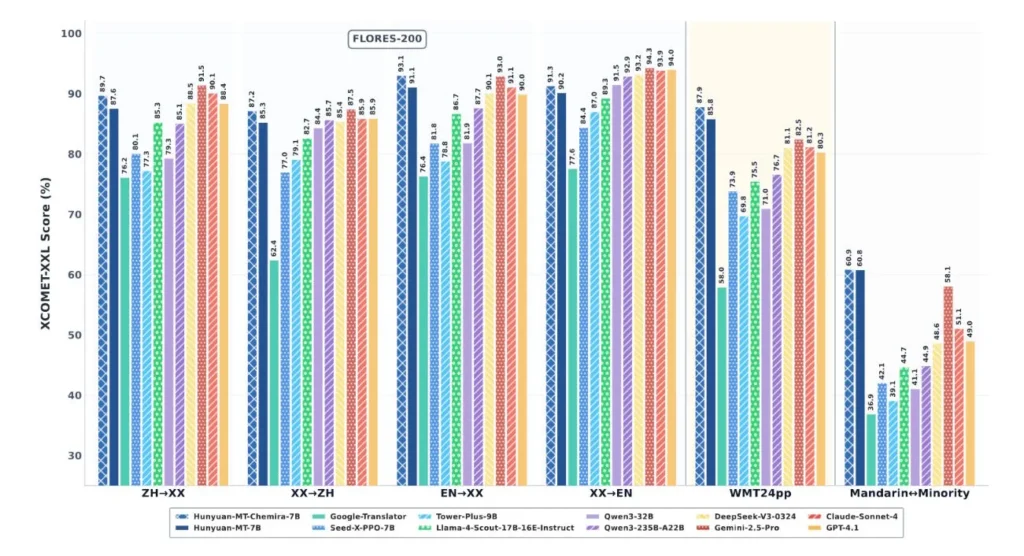
Të dy modelet mbështesin përkthimin dypalësh në 33 gjuhë, duke përfshirë gjuhët që përdoren gjerësisht si kinezishtja, anglishtja dhe japonishtja, si dhe gjuhët më pak të dixhitalizuara si çekishtja, maratishtja, estonishtja dhe islandishtja. Tencent thotë se një fokus i madh është përkthimi midis kinezishtes mandarine dhe gjuhëve të pakicave në Kinë. Modelet mund të përkthejnë në të dyja mënyrat midis kinezishtes dhe kazakishtes, ujgurishtes, mongolishtes dhe tibetishtes.
Raporti teknik i Tencent tregon se modelet Hunyuan i kanë tejkaluar sistemet e vendosura në krahasime të drejtpërdrejta. Krahasuar me Google Translate, rezultatet u përmirësuan me 15 deri në 65 përqind, varësisht nga drejtimi gjuhësor dhe kriteret e vlerësimit. Sistemet e patentuara të IA-së si GPT-4 .1, Claude 4 Sonnet dhe Gemini 2.5 Pro gjithashtu dështuan në shumicën e testeve.
Me 7 miliardë parametra, këto modele janë shumë më të vogla se shumë modele fondacioni në klasën e tyre, kështu që ato kërkojnë më pak fuqi llogaritëse dhe mund të funksionojnë në pajisje më të dobëta. Standardet tregojnë se ato ende krahasohen ose madje i tejkalojnë sistemet më të mëdha në performancë. Në veçanti, ato i tejkalojnë seritë Tower Plus (deri në 72 miliardë parametra) me 10 deri në 58 përqind.
Në testet kokë më kokë me çifte gjuhësh kryesore, të dy modelet Hunyuan treguan përmirësime të qarta. Krahasuar me Gemini 2.5 Pro, ato shënuan rreth 4.7 përqind më shumë. Kur u testuan kundrejt modeleve të specializuara të përkthimit, përmirësimet varionin nga 55 në 110 përqind.
Modelet janë të disponueshme si burim i hapur në Hugging Face, dhe Tencent ka publikuar gjithashtu kodin burimor në GitHub.
Tencent përdori një proces trajnimi me pesë faza: duke filluar me tekstin e përgjithshëm, pastaj duke u rafinuar me të dhëna specifike për përkthimin, e ndjekur nga të mësuarit e mbikëqyrur mbi shembujt e përkthimeve, të mësuarit përforcues me sinjale shpërblimi dhe një hap përfundimtar të të mësuarit përforcues “nga i dobëti në të fortë”.
Të dhënat e trajnimit përfshinin 1.3 trilion tokena vetëm për gjuhët e pakicave, duke mbuluar 112 gjuhë dhe dialekte. Një sistem vlerësimi i personalizuar kontrolloi të dhënat për vlerën e njohurive, autenticitetin dhe stilin e shkrimit.