Apple mësoi një LLM të parashikojë tokenët deri në 5 herë më shpejt në detyra matematike dhe programimi

Një punim i ri kërkimor nga Apple detajon një teknikë që përshpejton përgjigjet e modelit të gjuhës së madhe, duke ruajtur njëkohësisht cilësinë e rezultatit.
Tradicionalisht, LLM-të gjenerojnë tekst një token në të njëjtën kohë. Kjo është e ngadaltë sepse çdo hap varet nga të gjithë hapat e mëparshëm për ta mbajtur rezultatin koherent dhe të saktë.
Nëse modeli po shkruan një fjali si ” The cat is black”, ai parashikon çdo shenjë në sekuencë. Pasi shkruan ” The cat is”, ai shqyrton gjithçka deri më tani (plus kërkesën e përdoruesit dhe modelet që ka mësuar gjatë trajnimit) për të llogaritur probabilitetin e çdo shenjëje të mundshme tjetër në fjalorin e tij. Kjo quhet autoregresion.
Në këtë skenar, mund të rendisë opsione si black, tall, sleeping, grumpy, fluffy, skinny, purring, white, tired, playing, missing, meowing, cold, e kështu me radhë, dhe pastaj të zgjedhë atë që i përshtatet më mirë kontekstit.
Në studimin Your LLM Knows the Future: Zbulimi i Potencialit të saj për Parashikimin e Shumë-Tokenëve, ekipi i Apple zbuloi se edhe pse këto modele zakonisht trajnohen për të parashikuar vetëm tokenin tjetër, ato prapëseprapë mbajnë informacione të dobishme në lidhje me disa tokenë të ardhshëm.
Duke u bazuar në këtë, ata zhvilluan një kornizë “parashikimi me shumë tokena” (MTP) që i lejon modelit të prodhojë shumë tokena njëkohësisht.
Nëse kjo tingëllon pak si studimi i modelit të difuzionit që trajtuam disa javë më parë, nuk jeni shumë larg. Ndërsa procesi i trajnimit dhe teknologjitë themelore ndryshojnë, të dyja qasjet synojnë përshpejtimin e nxjerrjes së përfundimeve dhe arritjen e rezultatit më shpejt sesa me qasjen “një shenjë në të njëjtën kohë”.
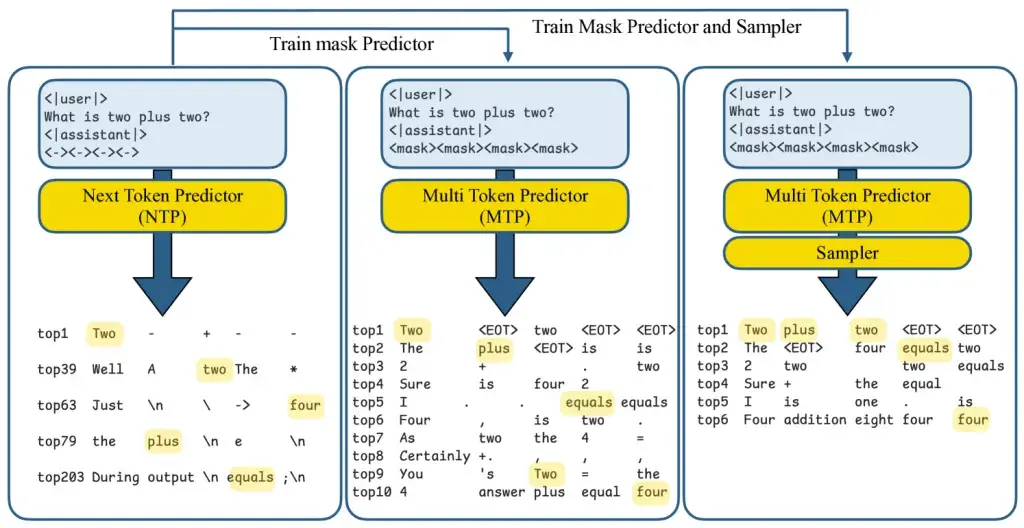
Në këtë studim të veçantë, studiuesit futën shenja të veçanta “maske” në pyetje, të cilat në thelb janë vendzgjatës për fjalët e ardhshme.
Për shembull, “Macja është ” mund të plotësohet si ” very fluffy” në një hap të vetëm. Ndërsa shkruan, modeli spekulon mbi disa fjalë të ardhshme njëherësh, me secilën fjalë që verifikohet menjëherë kundrejt asaj që do të kishte prodhuar dekodimi standard autoregresiv. Nëse një hamendje nuk e kalon kontrollin, ajo kthehet në procesin e rregullt një-nga-një. Në përgjithësi, kjo siguron shpejtësi shtesë, pa sakrifikuar saktësinë.
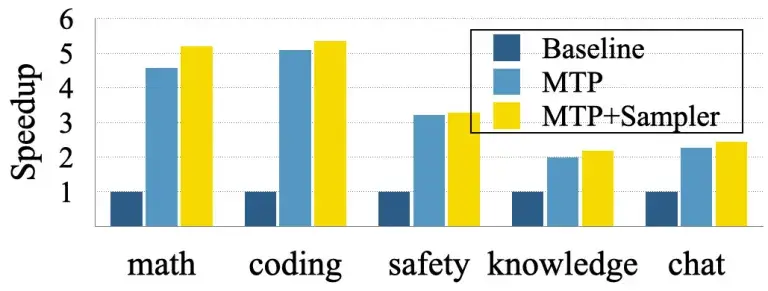
Gjatë testimit me modelin Tulu3-8B me burim të hapur, Apple e trajnoi modelin për të parashikuar në mënyrë spekulative 8 tokena shtesë dhe raportoi shpejtësi mesatare prej 2-3 herë në detyra të përgjithshme si pyetje-përgjigje dhe biseda, dhe deri në 5 herë për fusha më të parashikueshme si kodimi dhe matematika. Fitimet erdhën me “asnjë përkeqësim në cilësinë e gjenerimit, falë një teknike të thjeshtë por efektive që ne e quajmë adaptim i LoRA-së i kontrolluar”.