DeepSeek prezanton ‘Sparse Attention,’ një model revolucionar të gjeneratës së ardhshme të AI për përpunim më të shpejtë dhe më të lirë të konteksteve të gjata

Muaj pasi tronditi tregun e IA-së me modelin e saj R1, i lavdëruar për tejkalimin e rivalëve të njohur me një kosto shumë më të ulët, startup-i kinez i IA-së DeepSeek është rikthyer në qendër të vëmendjes. Kompania me seli në Hangzhou ka prezantuar një sistem të ri eksperimental, DeepSeek-V3.2-Exp, i cili është ndërtuar rreth një teknike që e quan “Vëmendje e Pakët”. Lëvizja, e raportuar për herë të parë nga Bloomberg, sinjalizon atë që kompania e përshkruan si një “hap të ndërmjetëm” drejt një arkitekture të gjeneratës së ardhshme.

DeepSeek ka ndërtuar një reputacion si një nga lojtarët më ambiciozë të IA-së në Kinë, duke kombinuar ambicien teknike me sekretin. Me V3.2-Exp, ai synon një nga sfidat më të vështira në modelet e mëdha gjuhësore: efikasitetin në shkallë të gjerë, veçanërisht në trajtimin e tekstit të zgjeruar. Sistemi ndërtohet drejtpërdrejt mbi DeepSeek-V3.1-Terminus dhe prezanton Sparse Attention, një metodë që zvogëlon mbingarkesën llogaritëse të detyrave me kontekst të gjatë, duke ruajtur njëkohësisht cilësinë e rezultatit.
“DeepSeek përditësoi të hënën një model eksperimental të inteligjencës artificiale, në atë që e quajti një hap drejt inteligjencës artificiale të gjeneratës së ardhshme. Startupi sekret kinez përshkroi platformën DeepSeek-V3.1-Exp, duke shpjeguar se përdor një teknikë të re që e quan DeepSeek Sparse Attention ose DSA, sipas një postimi në faqen e saj Hugging Face”, raportoi Bloomberg.
“Vëmendja e Skuqur” zëvendëson qasjen tradicionale të transformuesve me forcë brutale – ku çdo token detyrohet të bashkëveprojë me çdo token tjetër – me diçka më selektive. Një “indeksues rrufeje” vlerëson shpejt tokenët e kaluar dhe rendit rëndësinë e tyre, duke mbajtur vetëm më të rëndësishmet për secilën pyetje.
Kjo shkurtesë e zvogëlon ngarkesën e punës në kuadratikë, duke mundësuar një përshpejtim deri në 64 herë kur merreni me sekuenca deri në 128,000 tokena të gjatë. Metoda kombinon kompresimin e tokenave me kokërr të trashë me përzgjedhjen me kokërr të imët, duke siguruar që modeli të mos humbasë gjurmët e kontekstit më të gjerë. DeepSeek thotë se kjo është e ndryshme nga përpjekja e saj e mëparshme, Native Sparse Attention, e lançuar më parë këtë vit, dhe madje mund të ri-përshtatet në modele të para-trajnuara.
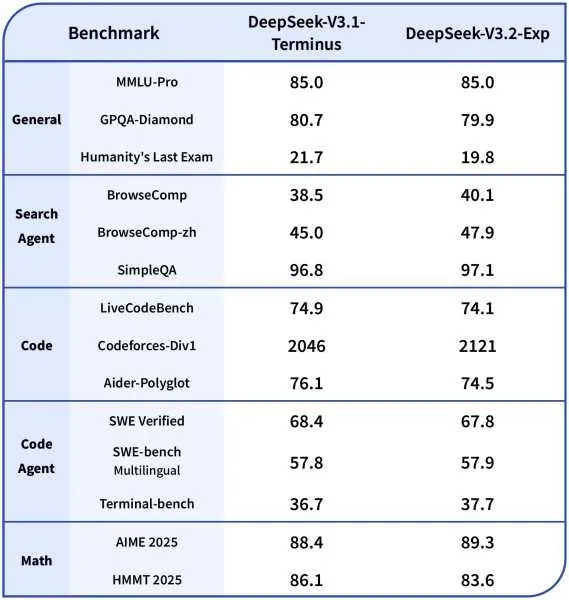
Në testet krahasuese, V3.2-Exp mban pozicionin e saj në krahasim me versionin e mëparshëm të kompanisë. Në testet e arsyetimit, kodimit dhe përdorimit të mjeteve, ndryshimet ishin të vogla – shpesh brenda një ose dy pikave – ndërsa rritjet në efikasitet ishin të habitshme. Modeli funksionoi 2-3 herë më shpejt në konkluzionin me kontekst të gjatë, uli përdorimin e memories me 30-40 përqind dhe përmirësoi efikasitetin e trajnimit me gjysmën. Për zhvilluesit, kjo do të thotë përgjigje më të shpejta, kosto më të ulëta të infrastrukturës dhe një rrugë më të lehtë drejt vendosjes.
“Prezantimi i DeepSeek-V3.2-Exp — modeli ynë më i fundit eksperimental! I ndërtuar mbi V3.1-Terminus, ai prezanton DeepSeek Sparse Attention(DSA) për trajnim dhe nxjerrje përfundimesh më të shpejta dhe më efikase në kontekst të gjatë. Tani është i disponueshëm në Aplikacion, Ueb dhe API. Çmimet e API-ve ulen me mbi 50%!”, tha DeepSeek në një postim në X.
DeepSeek-V3.2-Exp, me afërsisht 671 miliardë parametra, u trajnua sipas konfigurimeve të përafruara me V3.1-Terminus për të izoluar ndikimin e DSA-së. Standardet në të gjithë arsyetimin, kodimin dhe përdorimin e mjeteve agjentike tregojnë barazi ose përmirësime të vogla.
Këto rezultate tregojnë se DSA sjell humbje minimale të cilësisë – shpesh brenda 1-2 pikëve – ndërsa ofron përmirësime të konsiderueshme në efikasitet: nxjerrje përfundimesh 2-3 herë më të shpejta për kontekste të gjata, përdorim të memories të reduktuar me 30-40% dhe efikasitet të trajnimit të përmirësuar deri në 50%. Në terma praktikë, kjo përkthehet në faza më të shpejta të para-mbushjes dhe dekodimit, duke e bërë modelin më të zbatueshëm për vendosje në botën reale.
DeepSeek e ka bërë modelin të aksesueshëm në Hugging Face sipas një licence MIT, me bërthama CUDA dhe optimizime në GitHub. Ai funksionon me harduer si GPU-të H100 të NVIDIA-s, megjithëse kompania rekomandon një për testim dhe tetë për ngarkesa pune në prodhim. Opsionet e vendosjes përfshijnë transformatorët Hugging Face, SGLang dhe vLLM.
Kompania po ul gjithashtu kostot. Çmimet e API-ve janë ulur me më shumë se 50 përqind, me inpute deri në 0.07 dollarë për milion token nën goditjet e memories cache. Kjo e vendos DeepSeek midis ofruesve më të lirë të IA-së në shkallë të gjerë, një veprim që mund t’u pëlqejë startup-eve dhe ndërmarrjeve njësoj. Modeli është tashmë aktiv në aplikacionin, platformën web dhe API-në e DeepSeek, me reagime nga komuniteti të hapura deri më 15 tetor.
Koha ka rëndësi. Liderët globalë të IA-së po investojnë miliarda në sisteme me burime të rënda, ndërsa DeepSeek po vë bast se efikasiteti do të përcaktojë valën e ardhshme. Duke nxjerrë më shumë vlerë nga përpunimi në kontekst të gjatë, Sparse Attention e pozicionon kompaninë në gjendje të konkurrojë jo vetëm në performancë, por edhe në ekonomi. Zërat e industrisë në X kanë sugjeruar tashmë se qasja e saj mund ta bëjë inteligjencën “pothuajse shumë të lirë për t’u matur”.
Strategjia e DeepSeek—e heshtur, eksperimentale dhe agresive në efikasitet—e mban atë fort në garën globale të IA-së. Me V3.2-Exp, kompania nuk po përsërit vetëm punën e kaluar; po hedh themelet për atë që sheh.