OpenAI pranon se injeksioni i kërkesave (prompt injection) është një “problem i pazgjidhur”, ndërsa dalin në pah dobësi sigurie
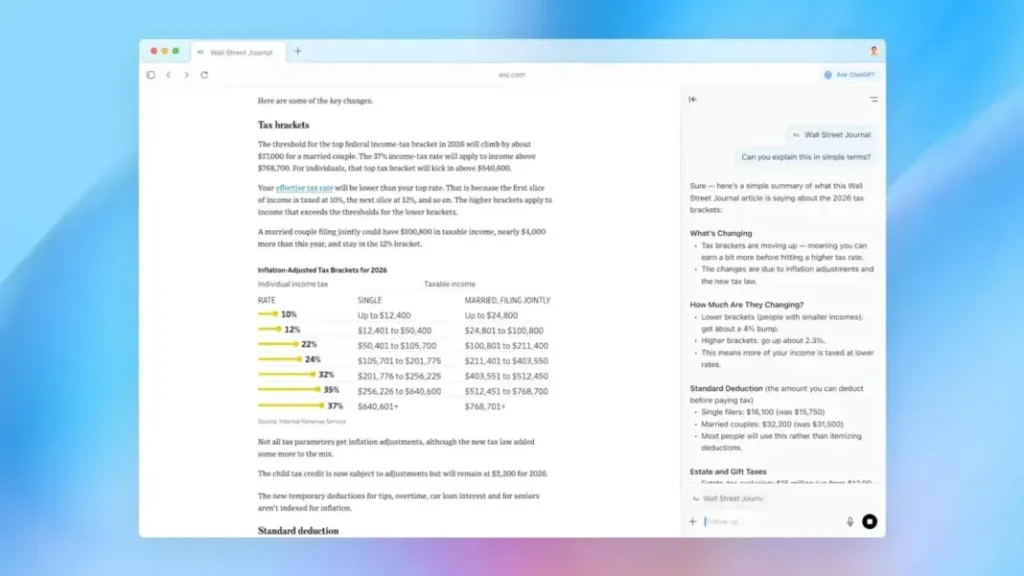
CISO i OpenAI, Dane Stuckey, ka trajtuar kërcënimin ‘e pazgjidhur’ të injektimit të shpejtë në shfletuesin e ri ChatGPT Atlas, duke detajuar masat e reja mbrojtëse ndërsa studiuesit gjejnë dobësi aktive.
Vetëm pak ditë pasi lançoi shfletuesin e saj ambicioz ChatGPT Atlas, OpenAI po përballet publikisht me një të metë themelore sigurie që ekspertët paralajmërojnë se mund të ndikojë në të gjithë kategorinë e mjeteve të internetit të mundësuara nga inteligjenca artificiale.

Në një deklaratë të detajuar publike, drejtuesi më i lartë i sigurisë i kompanisë pranoi se “injektimi i shpejtë” mbetet një problem i pazgjidhur, edhe pse studiuesit filluan të demonstronin sulme të drejtpërdrejta kundër shfletuesit të ri.
Pas lançimit të shfletuesit të martën, Drejtori Kryesor i Sigurisë së Informacionit të OpenAI, Dane Stuckey, iu drejtua X të mërkurën për të adresuar shqetësimet në rritje.
Postimi i tij u përball drejtpërdrejt me rrezikun e injektimit indirekt të menjëhershëm, ku udhëzimet keqdashëse të fshehura në faqet e internetit mund ta mashtrojnë agjentin e inteligjencës artificiale të shfletuesit që të kryejë veprime të paqëllimshme dhe potencialisht të dëmshme.
Duke pranuar dobësinë, Stuckey shpjegoi se qëllimi afatgjatë i kompanisë është ta bëjë agjentin po aq të besueshëm sa një koleg i vetëdijshëm për sigurinë.
Megjithatë, ai pranoi se teknologjia nuk është ende aty. “…injektimi i shpejtë mbetet një problem sigurie i pazgjidhur dhe në kufij të gjerë, dhe kundërshtarët tanë do të shpenzojnë kohë dhe burime të konsiderueshme për të gjetur mënyra për ta bërë agjentin ChatGPT të bjerë pre e këtyre sulmeve.”
Ky pranim u pa nga shumë njerëz në komunitetin e sigurisë si një pranim i sinqertë dhe i domosdoshëm i rreziqeve të natyrshme në valën e re të IA-së agjentike.
Injektimi i menjëhershëm nuk është një problem i ri apo i izoluar. Winbuzzer ka raportuar më parë për dobësi të ngjashme, të tilla si defekti i injektimit të menjëhershëm indirekt i zbuluar në shfletuesin Comet të Perplexity në fillim të këtij viti.
Një raport nga ekipi i sigurisë i Brave e përshkroi të metën si një sfidë sistemike me të cilën përballen të gjithë shfletuesit e mundësuar nga IA . “…injektimi indirekt i kërkesave nuk është një problem i izoluar, por një sfidë sistemike me të cilën përballet e gjithë kategoria e shfletuesve të mundësuar nga IA.” Rreziku kryesor qëndron në pamundësinë e një agjenti të IA-së për të dalluar midis udhëzimeve të një përdoruesi dhe komandave keqdashëse të ngulitura brenda përmbajtjes që përpunon.
Kjo mund ta shndërrojë inteligjencën artificiale në një “zëvendës të hutuar”, një dilemë klasike e sigurisë kibernetike ku një program me autoritet mashtrohet për ta keqpërdorur atë.
Për shembull, vetëm disa orë pasi Atlas u lançua, një studiues demonstroi një sulm të ri “Clipboard Injection”, ku kodi i fshehur në një faqe interneti mund të ndryshonte me qëllim të keq skedën e një përdoruesi kur agjenti i inteligjencës artificiale klikonte një buton, duke e bërë përdoruesin të ngjiste më vonë një komandë keqdashëse pa dijeninë e tij.
Për studiuesit e sigurisë, lançimi i shfletuesit ofroi një mundësi të menjëhershme për të testuar mbrojtjen e tij kundër sulmeve të botës reale.
Disa prej tyre nxituan të publikonin demonstrime që tregonin se si mund ta bënin Atlasin të ndiqte udhëzime dashakeqe të ngulitura në Google Docs ose në faqet e internetit.
Kjo tregon rreziqet e larta në atë që disa e quajnë lufta e dytë e shfletuesve, një konflikt i zhvilluar jo për veçoritë, por për inteligjencën dhe autonominë, me konkurrentë si Comet i Perplexity që tashmë janë në fushë.
Ndërsa transparenca e OpenAI është një hap i mirëpritur, ekspertët paralajmërojnë se “mbrojtja në thellësi” shpesh nuk është e mjaftueshme për të ndaluar kundërshtarët e vendosur.
Stuckey detajoi disa masa sigurie të mbivendosura të integruara në Atlas për të zbutur këto rreziqe. Një nga mbrojtjet kryesore është një veçori e quajtur “Logged Out Mode”, e cila i lejon agjentit të shfletojë dhe të veprojë në emër të një përdoruesi pa pasur qasje në kredencialet e tyre për seancat e kyçura.
Eksperti i inteligjencës artificiale, Simon Willison, e quajti këtë një model “shumë të zgjuar” dhe të testuar për ndërveprimet e inteligjencës artificiale në sandbox.
Megjithatë, “Modaliteti i Hyrë” më i fuqishëm është vendi ku rreziqet përshkallëzohen. Për situatat që kërkojnë akses të autentifikuar, OpenAI ka zbatuar një tjetër mbrojtje:
“Kur agjenti vepron në vende të ndjeshme, ne kemi zbatuar edhe një ‘Modalitet Vëzhgimi’ që ju njofton… dhe kërkon që ta keni skedën aktive për të parë agjentin duke bërë punën e tij.”
Kjo veçori është projektuar për ta mbajtur përdoruesin të informuar kur agjenti bashkëvepron me informacione potencialisht të ndjeshme. Megjithatë, kompania nuk ka dhënë një përkufizim të qartë teknik të asaj që përbën një “faqe të ndjeshme”.
Një dokument zyrtar i qendrës së ndihmës vëren se veçoritë si përmbledhjet e faqeve janë të bllokuara në “disa faqe interneti të ndjeshme (si faqet për të rritur)”, por ofron pak detaje të mëtejshme. Kjo paqartësi është një shqetësim i madh.
Willison vuri në dukje se gjatë testimit të tij, modaliteti nuk u aktivizua në faqe si GitHub ose banka e tij online, duke arritur në përfundimin se delegimi i vendimeve të sigurisë te përdoruesit fundorë është një “barrë e padrejtë”.
Reagimi nga komuniteti i sigurisë ka qenë një përzierje lavdërimesh për sinqeritetin e OpenAI dhe skepticizmi të thellë në lidhje me zgjidhjet e propozuara.
Studiuesi i sigurisë së inteligjencës artificiale, Johann Rehberger, i cili ka dokumentuar sulme të shumta me injeksion të shpejtë, deklaroi se kërcënimi është i përhapur.
“Në një nivel të lartë, injektimi i shpejtë mbetet një nga kërcënimet kryesore në zhvillim në sigurinë e inteligjencës artificiale… kërcënimi nuk ka një zbutje të përsosur – ashtu si sulmet e inxhinierisë sociale kundër njerëzve.”
Willison e përsëriti këtë mendim, duke argumentuar se kangjellat mbrojtëse shpesh janë të pamjaftueshme kundër sulmuesve të motivuar.
Ai paralajmëron se në sigurinë e aplikacioneve, niveli pothuajse i përsosur nuk është mjaftueshëm i mirë.
“Siç kam shkruar edhe më parë, në sigurinë e aplikacioneve, 99% është një notë jokaluese. Nëse ka një mënyrë për të kapërcyer pengesat… një sulmues kundërshtar i motivuar do ta kuptojë këtë.”
Lançimi i Atlas ka pasur tashmë një ndikim të prekshëm në treg, duke nxjerrë në pah rreziqet e larta në luftërat e ripërtërira të shfletuesve. Pas njoftimit, aksionet e Alphabet fillimisht ranë me 3%, një humbje prej rreth 18 miliardë dollarësh në vlerë tregu, përpara se të rikuperoheshin.
Megjithatë, analistë si Gene Munster i Deepwater Asset Management argumentuan se Atlas nuk është një përvojë “10 herë më e mirë” dhe se Google mund t’i kopjojë lehtësisht veçoritë e tij, duke e bërë të vështirë për shfletuesin e ri të fitojë një pjesë të konsiderueshme të tregut.
Në fund të fundit, OpenAI e gjen veten duke lundruar në një luftë të vështirë me dy fronte. Në njërin front, duhet të ofrojë një produkt aq bindës sa të mund të thyejë kontrollin e Google mbi zakonet e përdoruesve.
Nga ana tjetër, duhet të jetë pioniere në sigurinë për një paradigmë të re informatike të mbushur me rreziqe të papara. Ndërsa kompania punon për të ndërtuar besimin e përdoruesve, komuniteti më i gjerë i sigurisë do të vëzhgojë – dhe testojë – çdo hap të rrugës.