Shumica e matjeve të LLM-ve janë të metura, duke vënë në dyshim treguesit e përparimit të inteligjencës artificiale

Një studim i ri ndërkombëtar nxjerr në pah problemet kryesore me standardet e modelit të gjuhës së madhe (LLM), duke treguar se shumica e metodave aktuale të vlerësimit kanë të meta serioze.
Pas shqyrtimit të 445 punimeve referuese nga konferencat kryesore të IA-së, studiuesit zbuluan se pothuajse çdo pikë referimi ka probleme themelore metodologjike.
“Pothuajse të gjithë artikujt kanë dobësi në të paktën një fushë”, shkruajnë autorët. Rishikimi i tyre mbuloi studime krahasuese nga konferencat kryesore të të mësuarit automatik dhe NLP (ICML, ICLR, NeurIPS, ACL, NAACL, EMNLP) nga viti 2018 deri në vitin 2024, me kontributin e 29 recensentëve ekspertë.
Vlefshmëria e pikës referuese ka të bëjë me faktin nëse një test mat vërtet atë që pretendon. Për LLM-të, një pikë referimi e vlefshme do të thotë që rezultatet e forta pasqyrojnë në të vërtetë aftësinë që testohet.
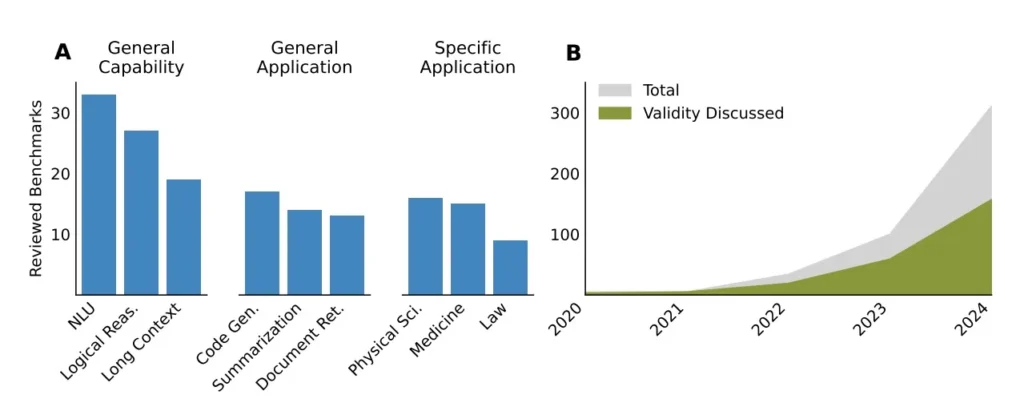
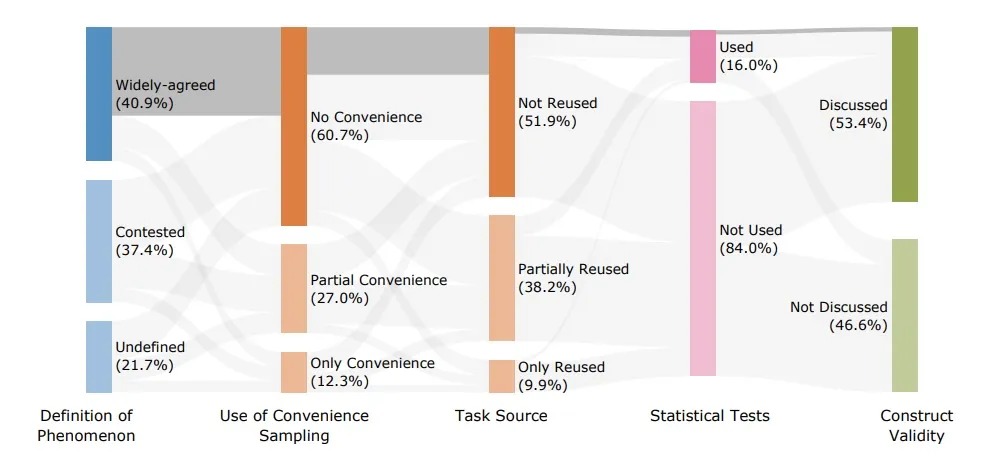
Studimi zbuloi se përkufizimet e standardeve shpesh janë të paqarta ose të diskutueshme. Ndërsa 78 përqind e standardeve përcaktojnë atë që matin, pothuajse gjysma e këtyre përkufizimeve janë të paqarta ose të diskutueshme. Termat kyç si “arsyetim”, “përputhje” dhe “siguri” shpesh lihen të padefinuara, duke i bërë përfundimet të pabesueshme.
Rreth 61 përqind e testeve të standardeve testojnë aftësi të përbëra si sjellja agjentike, e cila kombinon njohjen e qëllimit dhe gjenerimin e rezultateve të strukturuara. Këto nën-aftësi rrallë vlerësohen veçmas, duke i bërë rezultatet të vështira për t’u interpretuar.
Një problem tjetër: 41 përqind e testeve të referencës përdorin detyra artificiale dhe 29 përqind mbështeten vetëm në to. Vetëm rreth 10 përqind përdorin detyra të botës reale që pasqyrojnë në të vërtetë mënyrën se si përdoren këto modele në praktikë.
Marrja e mostrave është një tjetër dobësi e madhe në standardet aktuale të LLM-së. Rreth 39 përqind mbështeten në marrjen e mostrave të përshtatshme dhe 12 përqind e përdorin atë ekskluzivisht, që do të thotë se ata zgjedhin të dhënat që janë më të lehta në vend të të dhënave që pasqyrojnë vërtet përdorimin në botën reale.
Riciklimi i të dhënave është gjithashtu i përhapur. Rreth 38 përqind e testeve të referencës ripërdorin të dhëna nga testet njerëzore ose burime ekzistuese, dhe shumë prej tyre mbështeten edhe më shumë në grupe të dhënash nga teste të tjera të referencës.