Përmbledhje vjetore e LLM-ve për vitin 2025

Viti 2025 ka qenë një vit i fortë dhe plot ngjarje progresi në LLM. Më poshtë është një listë e “ndryshimeve të paradigmës” personale të dukshme dhe paksa të habitshme gjëra që ndryshuan peizazhin dhe më ranë në sy konceptualisht.

Në fillim të vitit 2025, sasia e prodhimit të LLM në të gjitha laboratorët dukej diçka e tillë:
Para-trajnim (GPT-2/3 e ~2020)
Përshtatja e mbikëqyrur (InstructGPT ~2022) dhe
Mësimi i Përforcimit nga Reagimet Njerëzore (RLHF ~2022)
Kjo ishte receta e qëndrueshme dhe e provuar për trajnimin e një LLM të nivelit të prodhimit për një farë kohe. Në vitin 2025, Mësimi Përforcues nga Shpërblimet e Verifikueshme (RLVR) doli si faza e re kryesore de facto për t’u shtuar në këtë përzierje. Duke trajnuar LLM-të kundrejt shpërblimeve automatikisht të verifikueshme në një numër mjedisesh (p.sh. mendoni për enigma matematike/kodi), LLM-të zhvillojnë spontanisht strategji që u duken njerëzve si “arsyetim” – ata mësojnë të ndajnë zgjidhjen e problemeve në llogaritje të ndërmjetme dhe mësojnë një numër strategjish zgjidhjeje problemesh për të shkuar para dhe mbrapa për të kuptuar gjërat (shih dokumentin DeepSeek R1 për shembuj). Këto strategji do të kishin qenë shumë të vështira për t’u arritur në paradigmat e mëparshme sepse nuk është e qartë se si duken gjurmët dhe rikuperimet optimale të arsyetimit për LLM – duhet të gjejë atë që funksionon për të, nëpërmjet optimizimit kundrejt shpërblimeve.
Ndryshe nga fazat SFT dhe RLHF, të cilat janë të dyja faza relativisht të holla/të shkurtra (përmirësime të vogla në aspektin llogaritës), RLVR përfshin trajnim kundër funksioneve të shpërblimit objektiv (jo të luajtshme) që lejon optimizim shumë më të gjatë. Ekzekutimi i RLVR rezultoi të ofronte aftësi të larta/$, të cilat përpinë llogaritjen që fillimisht ishte menduar për trajnim paraprak. Prandaj, pjesa më e madhe e progresit të aftësive të vitit 2025 u përcaktua nga laboratorët LLM që përtypën pjesën e tepërt të kësaj faze të re dhe në përgjithësi pamë LLM me madhësi të ngjashme, por ekzekutime RL shumë më të gjata. Gjithashtu unike për këtë fazë të re, morëm një buton krejt të ri (dhe ligjin e shkallëzimit të lidhur) për të kontrolluar aftësinë si një funksion i llogaritjes së kohës së testimit duke gjeneruar gjurmë më të gjata arsyetimi dhe duke rritur “kohën e të menduarit”. OpenAI o1 (fundi i vitit 2024) ishte demonstrimi i parë i një modeli RLVR, por lëshimi i o3 (fillimi i vitit 2025) ishte pika e dukshme e ndryshimit ku mund ta ndjenit intuitivisht ndryshimin.
Viti 2025 është vendi ku unë (dhe mendoj se edhe pjesa tjetër e industrisë) filluam për herë të parë të përvetësojmë “formën” e inteligjencës LLM në një kuptim më intuitiv. Ne nuk jemi kafshë që “evoluojnë/rriten”, ne jemi “thërrime fantazmash”. Çdo gjë në lidhje me paketën LLM është e ndryshme (arkitektura nervore, të dhënat e trajnimit, algoritmet e trajnimit dhe veçanërisht presioni i optimizimit), kështu që nuk duhet të jetë çudi që po marrim entitete shumë të ndryshme në hapësirën e inteligjencës, të cilat janë të papërshtatshme për t’u menduar përmes një lenteje shtazore. Sa i përket mbikëqyrjes, rrjetet nervore njerëzore janë të optimizuara për mbijetesën e një fisi në xhungël, por rrjetet nervore LLM janë të optimizuara për të imituar tekstin e njerëzimit, për të mbledhur shpërblime në enigma matematikore dhe për të marrë atë votë pozitive nga një njeri në LM Arena. Ndërsa domenet e verifikueshme lejojnë RLVR, LLM-të “rrisin” aftësitë në afërsi të këtyre domeneve dhe në përgjithësi shfaqin karakteristika të performancës qesharake – ato janë në të njëjtën kohë një polimat gjenial dhe një nxënës i shkollës fillore i hutuar dhe me sfida njohëse, sekonda larg nga mashtrimi nga një jailbreak për të nxjerrë të dhënat tuaja.
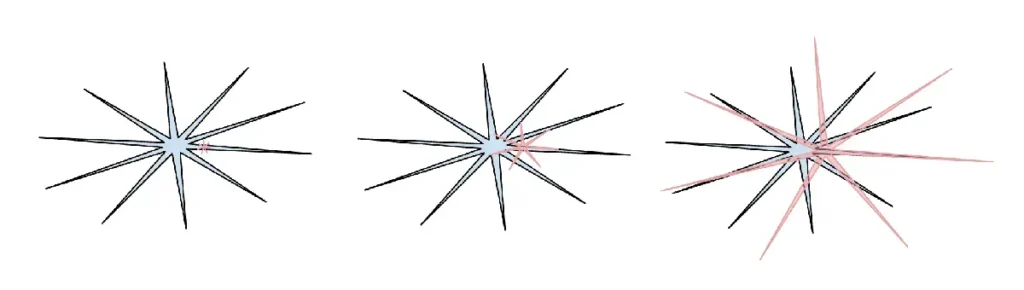
(inteligjenca njerëzore: blu, inteligjenca e inteligjencës artificiale: e kuqe. Më pëlqen ky version i meme-t (më vjen keq që humba referencën për postimin e tij origjinal në X) sepse thekson se inteligjenca njerëzore është gjithashtu e dhëmbëzuar në mënyrën e vet të ndryshme.)
Lidhur me të gjitha këto është apatia ime e përgjithshme dhe humbja e besimit në testet e referencës në vitin 2025. Çështja kryesore është se testet e referencës janë pothuajse nga ndërtimi mjedise të verifikueshme dhe për këtë arsye janë menjëherë të ndjeshme ndaj RLVR dhe formave më të dobëta të tij nëpërmjet gjenerimit të të dhënave sintetike. Në procesin tipik të benchmaxing, ekipet në laboratorët LLM në mënyrë të pashmangshme ndërtojnë mjedise ngjitur me xhepa të vegjël të hapësirës së ngulitur të zënë nga testet e referencës dhe rrisin jaggies për t’i mbuluar ato. Trajnimi në setin e testimit është një formë e re arti.
Si duket të kalosh të gjitha standardet, por prapë të mos arrish AGI-në?
Kam shkruar shumë më tepër mbi temën e kësaj pjese këtu:
Kafshët kundër Fantazmave
Verifikueshmëria
Hapësira e Mendjeve
Ajo që më bie më shumë në sy te Cursor (përveç rritjes së tij meteorike këtë vit) është se zbuloi bindshëm një shtresë të re të një “aplikacioni LLM” – njerëzit filluan të flisnin për “Cursor for X”. Siç e theksova në fjalimin tim në Y Combinator këtë vit ( transkript dhe video ), aplikacionet LLM si Cursor bashkojnë dhe orkestrojnë thirrjet LLM për vertikale specifike:
Ata bëjnë “inxhinierinë e kontekstit”
Ata orkestrojnë thirrje të shumta LLM nën kapuç, të lidhura në DAG gjithnjë e më komplekse, duke balancuar me kujdes kompromiset midis performancës dhe kostos.
Ato ofrojnë një GUI specifik për aplikacionin për njeriun në ciklin e punës.
Ata ofrojnë një “rrëshqitës autonomie”
Shumë biseda është bërë në vitin 2025 rreth asaj se sa “e trashë” është kjo shtresë e re e aplikacioneve. A do t’i përfshijnë laboratorët LLM të gjitha aplikimet apo ka mundësi të gjelbra për aplikacionet LLM? Personalisht, dyshoj se laboratorët LLM do të priren të diplomojnë studentët e kolegjit përgjithësisht të aftë, por aplikacionet LLM do të organizojnë, përsosin dhe në fakt do t’i animojnë ekipet e tyre në profesionistë të vendosur në vertikale specifike duke ofruar të dhëna private, sensorë dhe aktivizues dhe sythe reagimi.
Kodi Claude (CC) doli si demonstrimi i parë bindës i asaj se si duket një Agjent LLM – diçka që në një mënyrë të çuditshme bashkon përdorimin e mjeteve dhe arsyetimin për zgjidhjen e problemeve të zgjeruara. Përveç kësaj, CC është i dukshëm për mua në atë që funksionon në kompjuterin tuaj dhe me mjedisin, të dhënat dhe kontekstin tuaj privat. Mendoj se OpenAI e ka gabuar këtë sepse ata i përqendruan përpjekjet e tyre të hershme të kodeksit/agjentit në vendosjet në cloud në kontejnerë të orkestruar nga ChatGPT në vend që thjesht localhost. Dhe ndërsa tufat e agjentëve që funksionojnë në cloud duken si “loja përfundimtare e AGI”, ne jetojmë në një botë të ndërmjetme dhe mjaft të ngadaltë të aftësive të pabarabarta saqë ka më shumë kuptim të ekzekutohen agjentët direkt në kompjuterin e zhvilluesit. Vini re se dallimi kryesor që ka rëndësi nuk ka të bëjë me vendin ku ndodh të funksionojnë “operacionet e IA” (në cloud, lokalisht ose çfarëdo qoftë), por me gjithçka tjetër – kompjuterin tashmë ekzistues dhe të nisur, instalimin e tij, kontekstin, të dhënat, sekretet, konfigurimin dhe ndërveprimin me vonesë të ulët. Anthropic e korrigjoi këtë rend përparësie dhe e paketoi CC në një formë të këndshme dhe minimale CLI që ndryshoi pamjen e inteligjencës artificiale – nuk është thjesht një faqe interneti që vizitoni si Google, është një shpirt/fantazmë e vogël që “jeton” në kompjuterin tuaj. Ky është një paradigmë e re dhe e dallueshme e ndërveprimit me një inteligjencë artificiale.
Viti 2025 është viti kur IA kaloi një prag aftësish të nevojshëm për të ndërtuar të gjitha llojet e programeve mbresëlënëse thjesht përmes anglishtes, duke harruar se kodi ekziston fare. Çuditërisht, unë shpika termin “kodim vibe” në këtë cicërimë me mendime, krejtësisht i pavetëdijshëm se sa larg do të shkonte:). Me kodimin vibe, programimi nuk është i rezervuar rreptësisht për profesionistë të trajnuar mirë, është diçka që kushdo mund ta bëjë. Në këtë cilësi, është një shembull tjetër i asaj që shkrova në ” Power to the people: How LLMs e ndryshojnë skenarin mbi përhapjen e teknologjisë, se si (në kontrast të mprehtë me të gjithë teknologjinë tjetër deri më tani) njerëzit e zakonshëm përfitojnë shumë më tepër nga LLM-të krahasuar me profesionistët, korporatat dhe qeveritë. Por kodimi vibe jo vetëm që i fuqizon njerëzit e zakonshëm t’i qasen programimit, por i fuqizon profesionistët e trajnuar të shkruajnë shumë më tepër softuer (të koduar me vibe) që përndryshe nuk do të shkruheshin kurrë. Në nanochat, unë kodova me vibe tokenizuesin tim të personalizuar BPE shumë efikas në Rust në vend që të më duhej të përvetësoja bibliotekat ekzistuese ose të mësoja Rust në atë nivel. Këtë vit kam koduar me Vibe shumë projekte si demo të shpejta aplikacionesh të diçkaje që doja të ekzistonte (p.sh. shih menugen, llm-council, reader3, HN time capsule ). Dhe kam koduar me Vibe aplikacione të tëra kalimtare vetëm për të gjetur një gabim të vetëm sepse pse jo – kodi papritmas është falas, kalimtar, i ndryshueshëm, i hidhshëm pas një përdorimi të vetëm. Kodimi me Vibe do të terraformojë softuerin dhe do të ndryshojë përshkrimet e punës.
Google Gemini Nano banana është një nga modelet më të pabesueshme dhe që ndryshon paradigmën e vitit 2025. Sipas botëkuptimit tim, LLM-të janë paradigma e ardhshme e madhe e informatikës, e ngjashme me kompjuterët e viteve 1970, 80, etj. Prandaj, do të shohim lloje të ngjashme inovacionesh për arsye thelbësisht të ngjashme. Do të shohim ekuivalentë të informatikës personale, të mikrokontrolluesve (bërthama njohëse) ose internetit (të agjentëve), etj. Në veçanti, për sa i përket UIUX, “biseda” me LLM-të është pak si lëshimi i komandave në një konsolë kompjuteri në vitet 1980. Teksti është përfaqësimi i të dhënave të papërpunuara/të preferuara për kompjuterët (dhe LLM-të), por nuk është formati i preferuar për njerëzit, veçanërisht në hyrje. Njerëzit në të vërtetë nuk e pëlqejnë leximin e tekstit – është i ngadaltë dhe i mundimshëm. Në vend të kësaj, njerëzit pëlqejnë të konsumojnë informacion vizualisht dhe hapësinor dhe kjo është arsyeja pse GUI është shpikur në informatikën tradicionale. Në të njëjtën mënyrë, LLM-të duhet të na flasin në formatin tonë të preferuar – në imazhe, infografikë, diapozitiva, tabela të bardha, animacione/video, aplikacione web, etj. Versioni i hershëm dhe aktual i kësaj sigurisht janë gjëra si emoji dhe Markdown, të cilat janë mënyra për të “veshur” dhe paraqitur tekstin vizualisht për konsum më të lehtë me tituj, shkronja të trasha, italike, lista, tabela, etj. Por kush do ta ndërtojë në të vërtetë GUI-në e LLM-së? Në këtë botëkuptim, nano banana është një aluzion i parë i hershëm se si mund të duket kjo. Dhe e rëndësishme, një aspekt i dukshëm i saj është se nuk ka të bëjë vetëm me vetë gjenerimin e imazhit, por me aftësinë e përbashkët që vjen nga gjenerimi i tekstit, gjenerimi i imazhit dhe njohuria botërore, të gjitha të ndërthurura në peshat e modelit.
Viti 2025 ishte një vit emocionues dhe paksa surprizues për LLM-të. LLM-të po shfaqen si një lloj i ri inteligjence, njëkohësisht shumë më të zgjuara nga sa prisja dhe shumë më budallenj nga sa prisja. Sidoqoftë, ato janë jashtëzakonisht të dobishme dhe nuk mendoj se industria ka realizuar as afër 10% të potencialit të tyre edhe në kapacitetin aktual. Ndërkohë, ka kaq shumë ide për të provuar dhe konceptualisht fusha duket e hapur. Dhe siç e përmenda në Dwarkesh pod-in tim më herët këtë vit, unë njëkohësisht (dhe në sipërfaqe paradoksalisht) besoj se do të shohim përparim të shpejtë dhe të vazhdueshëm dhe se ende ka shumë punë për të bërë.