Modeli i ri Gemma 4 12B i Google është projektuar të funksionojë në çdo laptop me 16 GB RAM

Bumi i inteligjencës artificiale gjeneruese e ka çuar koston e memories në stratosferë, dhe Google është një pjesë kyçe e këtij trendi. Pra, është e përshtatshme që Google të ofrojë disa modele lokale të inteligjencës artificiale që kërkojnë më pak RAM. Kompania ka njoftuar lançimin e një modeli të ri Gemma 4 që mbush një boshllëk në linjën që u lançua më parë këtë vit. Modeli i ri është mjaftueshëm efikas sa mund ta përdorni në një laptop mjaft mesatar për konsumatorët.

Në prill, Google lançoi katër modele në familjen Gemma 4, të cilat shënuan gjithashtu kalimin në një licencë më të hapur Apache 2.0. Modelet fillestare përfshinin dy opsione të optimizuara për celularë (E2B dhe E4B) së bashku me një palë modele për punë më serioze (26B Mixture of Experts dhe 31B Dense). Kjo la një hapësirë mjaft të madhe të pashërbyer në mes, e cila është pikërisht aty ku bie modeli i ri.
Gemma 4 12B është dukshëm më i aftë se versionet mobile, por nuk do të kërkojë një përshpejtues të inteligjencës artificiale prej 20,000 dollarësh për t’u ekzekutuar lokalisht. Google thotë se Gemma 4 12B është unik në atë që mund të funksionojë në shumë laptopë konsumatorësh pa sakrifikuar cilësinë. Për sa kohë që keni një kompjuter me 16 GB RAM sistemi ose VRAM, modeli me 12 miliardë parametra do të funksionojë. Kjo është rreth gjysma e gjurmës totale të memories së Gemma 4 26B MoE, dhe Google pretendon se modeli i ri është pothuajse po aq i aftë, të paktën për sa i përket testeve të performancës.
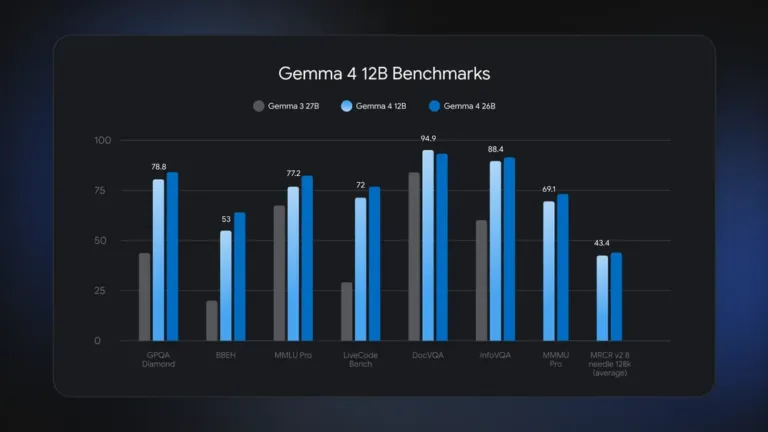
Google thotë se modeli i ri është i aftë të përdorë arsyetim kompleks shumëhapësh dhe rrjedha pune agjentike që më parë kërkonin variantet më të mëdha të Gemma-s. Pavarësisht numrit më të vogël të parametrave, Gemma 4 12B vjen me hartuesit e rinj të Parashikimit të Shumë-Shenjave (MTP), të cilët shfrytëzojnë ciklet e përpunimit të papërdorura për të llogaritur tokenët e mundshëm në të ardhmen. Rezultati është shpejtësi dhe efikasitet më i madh. Google ka publikuar versione opsionale MTP të modeleve të tjera Gemma 4, por ky është i pari që e ka MTP-në të instaluar menjëherë.
Gemma 4 12B është gjithashtu më efikas falë një qasjeje të re ndaj multimodalitetit. Familja Gemma 4 është multimodale në vetvete, duke pranuar tekst, audio ose imazhe si të dhëna hyrëse. Shumica e modeleve të inteligjencës artificiale të gjeneratës – duke përfshirë variantet e tjera të Gemma 4 – përdorin enkoderë të dedikuar për të përpunuar të dhëna jo-tekstuale dhe për t’ia kaluar ato të dhëna LLM-së. Kjo funksionon mjaft mirë, por rrit vonesën dhe përdorimin e memories.
Me modelin e ri me peshë mesatare, Google ka zbatuar një modul të përmirësuar të ngulitur për shikimin, që përmban shumëzimin me një matricë të vetme dhe ngulitur pozicionalisht, i cili lejon që të dhënat të kalojnë te LLM me ndërgjegjësimin e duhur hapësinor. Kjo eliminon nevojën për një enkoder të rëndë ndërmjetës. Për audion, nuk ka fare kodim. Zhvilluesit kanë përpunuar një metodë për projektimin e sinjalit audio të papërpunuar në të njëjtat vektorë të përdorur për tokenët e tekstit.
Nëse doni ta shikoni modelin e ri Gemma 4, ai është i arritshëm pa shkarkim nëpërmjet mjeteve si LM Studio, Google AI Edge Gallery dhe të tjera. Por e gjithë ideja me Gemma 4 12B është që mund ta përdorni lokalisht dhe sipas kushteve tuaja. Nëse keni RAM, peshat e modelit janë të disponueshme për shkarkim menjëherë në Kaggle dhe Hugging Face . Është vetëm pak më shumë se 18 GB.