DeepSeekMath-V2 barazohet me OpenAI dhe Google me fitoren e medaljes së artë në IMO

DeepSeek ka lançuar DeepSeekMath-V2, një inteligjencë artificiale me peshë të hapur që është barazuar me performancën e OpenAI dhe Google që fitoi Medaljen e Artë në IMO 2025.

DeepSeek ka shkatërruar përsëri kontrollin ekskluziv të gjigantëve të teknologjisë perëndimore mbi arsyetimin elitar, duke publikuar një model të inteligjencës artificiale me peshë të hapur që përputhet me performancën e OpenAI dhe Google në matematikë.
I lançuar të enjten, DeepSeekMath-V2 arriti një standard të Medaljes së Artë në Olimpiadën Ndërkombëtare të Matematikës (IMO) 2025.
Në Garën Matematikore William Lowell Putnam, konkursin më të shquar të matematikës për studentët e kolegjeve universitare në Shtetet e Bashkuara dhe Kanada, modeli shënoi 118 nga 120 pikë, duke tejkaluar rezultatin më të lartë njerëzor prej 90 pikësh. Ndryshe nga sistemet rivale të fshehura pas API-ve, DeepSeek i ka publikuar peshat publikisht, duke u lejuar studiuesve të inspektojnë drejtpërdrejt logjikën e tij.
Duke mbërritur gjatë vonesës së modelit kryesor R2 për shkak të kontrolleve të eksportit në SHBA, publikimi sinjalizon qëndrueshmëri teknike. Ai vërteton se arkitekturat e specializuara mund të ofrojnë rezultate të teknologjisë së fundit edhe kur qasja në harduerin më të fundit është e kufizuar.
DeepSeekMath-V2 zyrtarisht është barazuar me standardin e “Medaljes së Artë” në Olimpiadën Ndërkombëtare të Matematikës (IMO) 2025, duke zgjidhur me sukses 5 nga 6 probleme. Duke barazuar standardet e patentuara të vendosura nga arritjet e ngjashme të Google DeepMind dhe performanca e medaljes së artë të OpenAI , kjo performancë barazon fushën e lojës me sisteme që më parë ishin të paprekshme.
Larg nga një përditësim i thjeshtë përsëritës, ky version përfaqëson një ndryshim themelor në aksesin ndaj arsyetimit të inteligjencës artificiale elitare. Ndërsa laboratorët perëndimorë i kanë mbajtur modelet e tyre më të afta matematikore pas mureve të “testuesve të besuar” ose API-ve të shtrenjta, depoja e modeleve për DeepSeekMath-V2 është e disponueshme për shkarkim të menjëhershëm.
Institucionet akademike dhe studiuesit e ndërmarrjeve tani mund ta përdorin modelin në nivel lokal, duke verifikuar aftësitë e tij pa u mbështetur në infrastrukturën cloud që mund të jetë subjekt i shqetësimeve për privatësinë e të dhënave ose kufizimeve gjeopolitike.
Përtej IMO-s, modeli demonstroi aftësi të paprecedentë në konkursin Putnam, i cili konsiderohet gjerësisht si provimi më i vështirë i matematikës për studentët universitarë në Amerikën e Veriut. Duke theksuar arritjen, Ekipi Kërkimor DeepSeek deklaroi:
“Në Putnam 2024, konkursin më të shquar të matematikës për studentët e nivelit universitar, modeli ynë zgjidhi plotësisht 11 nga 12 problemet dhe problemin e mbetur me gabime të vogla, duke shënuar 118/120 dhe duke tejkaluar rezultatin më të lartë njerëzor prej 90.”
Tejkalimi i kufirit njerëzor në një provim kaq rigoroz sugjeron që modeli nuk është thjesht nxjerrja e provave të mësuara përmendësh, por edhe zgjidhja e problemeve të reja. Arritja e 118 pikëve nga 120 është veçanërisht e dukshme duke pasur parasysh vështirësinë ekstreme të problemeve, ku rezultatet mesatare janë historikisht të ulëta.
Analiza e pavarur i ka vërtetuar më tej këto metrika të brendshme. Vlerësimet mbi nëngrupin “Basic” të IMO-ProofBench, një pikë referimi e zhvilluar nga Google DeepMind, tregojnë se modeli arrin një shkallë suksesi prej 99.0%, duke konfirmuar qëndrueshmërinë e arsyetimit të tij në një gamë të gjerë fushash matematikore.
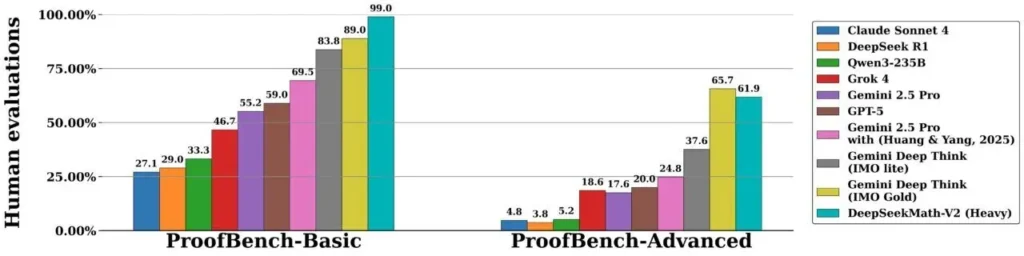
Verifikimi është thelbësor këtu, pasi fusha kohët e fundit është prekur nga rezultate të ekzagjeruara, siç është një pretendim i tërhequr në lidhje me GPT-5 që pretendonte në mënyrë të rreme se modeli kishte zgjidhur problemet e famshme të Erdős.
Duke publikuar peshat, DeepSeek ka bërë në mënyrë efektive të disponueshme një aftësi që konsiderohej një hendek i madh konkurrues për Silicon Valley vetëm disa muaj më parë. Clement Delangue, bashkëthemelues dhe CEO i Hugging Face, theksoi rëndësinë e këtij ndryshimi në një postim në X:
Historikisht, sfida qendrore në inteligjencën artificiale matematikore ka qenë “halucinacioni”, ku modelet arrijnë në përgjigjen e saktë duke përdorur logjikë të gabuar, rrethore ose absurde. Në testet e arsyetimit sasior, modelet shpesh mund të hamendësojnë numrin e saktë pa i kuptuar parimet themelore. Ekipi Kërkimor DeepSeek shpjegoi çështjen thelbësore në dokumentin teknik:
“Shumë detyra matematikore, si vërtetimi i teoremave, kërkojnë derivim rigoroz hap pas hapi në vend të përgjigjeve numerike, duke i bërë shpërblimet e përgjigjes përfundimtare të pazbatueshme.”
Për të adresuar këtë kufizim themelor, dokumenti teknik detajon një arkitekturë të re të përqendruar në “Meta-Verifikim”. Ndryshe nga metodat standarde të verifikimit që thjesht kontrollojnë nëse një përgjigje përputhet me një referencë, qasja e DeepSeek vlerëson vetë procesin e verifikimit.
DeepSeek trajnon një model dytësor për të gjykuar cilësinë e analizës së verifikuesit, duke e penguar modelin parësor të “manipulojë” sistemin e shpërblimit duke prodhuar prova që tingëllojnë bindëse, por logjikisht të pavlefshme.
Duke krijuar një mbrojtje kundër hakimit të shpërblimeve, kjo strukturë rekursive siguron që modeli të shpërblehet vetëm për rigorozitet të vërtetë arsyetimi. Duke vlerësuar nëse problemet e identifikuara në një provë justifikojnë logjikisht rezultatin, sistemi zbaton një qëndrueshmëri logjike të rreptë.
Në themel të kësaj arkitekture është një tubacion trajnimi “Fillimi i Ftohtë”. Në vend që të mbështetet në grupe të dhënash masive të jashtme të provave formale matematikore, të cilat janë të pakta dhe të kushtueshme për t’u kuruar, modeli gjeneron në mënyrë iterative të dhënat e veta të trajnimit. Duke përshkruar metodologjinë, studiuesit deklarojnë:
“Ne besojmë se LLM- të mund të trajnohen për të identifikuar problemet e provave pa zgjidhje referimi. Një verifikues i tillë do të mundësonte një cikël përmirësimi përsëritës: (1) duke përdorur reagimet e verifikimit për të optimizuar gjenerimin e provave, (2) duke shkallëzuar llogaritjen e verifikimit për të etiketuar automatikisht provat e reja të vështira për t’u verifikuar… dhe (3) duke përdorur këtë verifikues të përmirësuar për të optimizuar më tej gjenerimin e provave.”
“Për më tepër, një verifikues i besueshëm i provave na mundëson t’u mësojmë gjeneratorëve të provave të vlerësojnë provat ashtu siç bën verifikuesi. Kjo i lejon një gjeneratori provash të përsosë në mënyrë iterative provat e tij derisa të mos jetë më në gjendje të identifikojë ose zgjidhë ndonjë problem.”
Përmes këtij cikli, modeli përmirëson aftësitë e veta. Ndërsa verifikuesi bëhet më i saktë, ai mund të identifikojë gabime më delikate në daljen e gjeneratorit. Si pasojë, gjeneratori detyrohet të prodhojë prova më rigoroze për të përmbushur verifikuesin e përmirësuar.
Dinamika të tilla krijojnë një lak reagimi pozitiv që shkallëzon performancën pa kërkuar një rritje proporcionale të të dhënave të etiketuara nga njeriu. Në kohën e nxjerrjes së përfundimeve, modeli përdor “llogaritjen e shkallëzuar të kohës së testimit”. Në vend që të gjenerojë një përgjigje të vetme, sistemi gjeneron 64 prova kandidate për një problem të caktuar.
Pastaj ekzekuton procesin e verifikimit në të gjithë 64 kandidatët për të zgjedhur rrugën më të logjikshme. Duke zhvendosur barrën llogaritëse nga faza e trajnimit (shkallëzimi i parametrave) në fazën e nxjerrjes së përfundimeve (kërkimi i arsyetimit), kjo qasje përputhet me trendet më të gjera të industrisë drejt të menduarit “Sistemi 2” ku modelet “mendojnë” për një problem përpara se të nxjerrin një zgjidhje.
Duke shërbyer si një kundër-narrativë kritike ndaj problemeve të fundit të kompanisë me disponueshmërinë e pajisjeve, publikimi demonstron shkathtësi të konsiderueshme teknike. Modeli kryesor R2 i DeepSeek përballet me vonesa të lidhura me pajisjet për shkak të dështimeve të vazhdueshme gjatë trajnimit me çipat vendas Ascend të Huawei.
Ky pengesë nxori në pah vështirësinë e madhe që hasin firmat kineze në ndërtimin e një pakete softuerësh mbi pajisje të reja dhe të paprovuara nën presionin e kontrolleve të eksportit të SHBA-së. Duke u përqendruar në arkitektura të fokusuara në efikasitet, laboratori po demonstron se ende mund të transportojë kërkime të teknologjisë së fundit.
DeepSeekMath-V2 është ndërtuar mbi DeepSeek-V3.2-Exp-Base, duke vërtetuar se mekanizmat e vëmendjes së rrallë të prezantuar në atë model që nga shtatori janë gati për prodhim.
Në tetor, kompania lançoi mjetin e saj të njohjes optike të karaktereve, i cili përdori teknika të ngjashme efikasiteti për të kompresuar përpunimin e dokumenteve me dhjetëfish.
Disponueshmëria me peshë të hapur ushtron presion të konsiderueshëm mbi laboratorët perëndimorë për të justifikuar qasjen e tyre me burim të mbyllur.
Ndërsa “hendeku” i aftësisë së arsyetimit duket se po avullohet, argumenti se siguria kërkon mbajtjen e këtyre modeleve të kyçura bëhet më i vështirë për t’u mbështetur kur aftësi të krahasueshme janë të disponueshme lirisht në Hugging Face.
Për industrinë më të gjerë të IA-së, ky publikim sugjeron që modelet e specializuara dhe shumë të optimizuara mund të ofrojnë një rrugë të qëndrueshme përpara edhe kur qasja në grupe masive të GPU-ve Nvidia është e kufizuar.
Duke u përqendruar në inovacionet algoritmike si Meta-Verifikimi dhe vëmendjen e pakët, DeepSeek po krijon një vend konkurrues që mbështetet më pak në shkallën brutale dhe më shumë në zgjuarsinë arkitekturore.