Microsoft lançon Phi-4, një model të ri gjenerues të AI
Phi-4 LLM i ri i Microsoft Research përputhet me aftësitë e modeleve shumë më të mëdha duke përdorur vetëm 14 miliardë parametra rreth një e pesta e madhësisë së sistemeve të ngjashme.
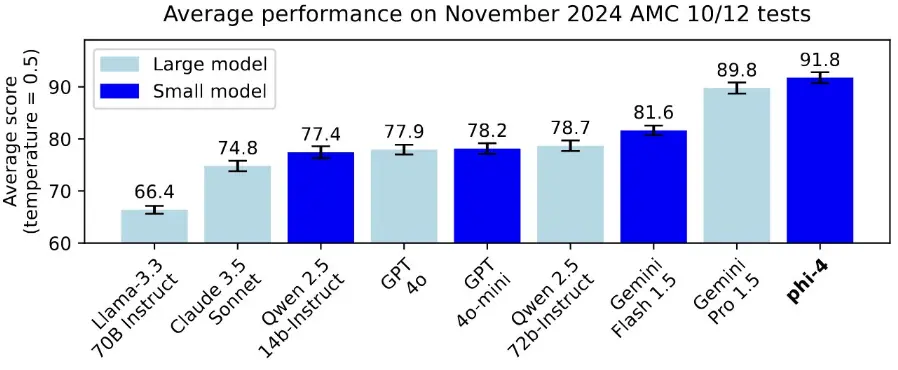
Sipas raportit teknik të Microsoft-it, modeli madje tejkalon GPT-4, modelin e tij të mësuesit, kur u përgjigjet pyetjeve të shkencës dhe teknologjisë. Phi-4 tregon forcë të veçantë në matematikë, duke arritur një shkallë suksesi prej 56.1 përqind në pyetjet e nivelit universitar dhe 80.4 përqind në problemet e konkurrencës matematikore.
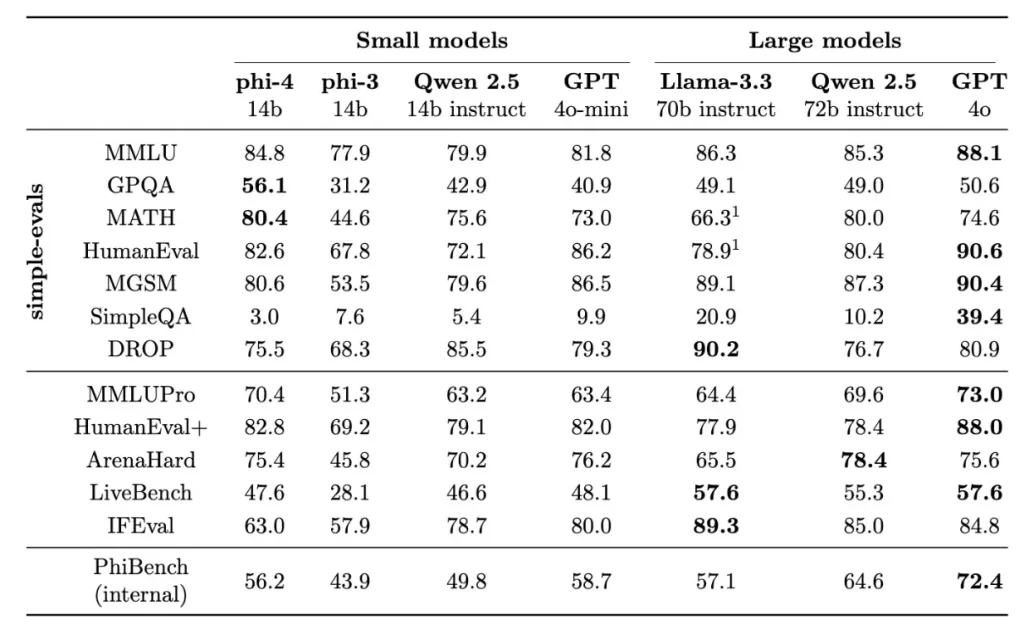
Microsoft vëren se Phi-4 ka probleme me ndjekjen e udhëzimeve të sakta të menjëhershme dhe kërkesat e formatimit si tabelat. Studiuesit shpjegojnë se kjo rrjedh nga trajnimi që u përqendrua në pyetje dhe përgjigje dhe arsyetim dhe jo në ndjekje strikte të menjëhershme.
Ashtu si modelet e tjera të gjuhëve, Phi-4 mund të gjenerojë informacione të rreme, siç janë biografitë fiktive për njerëz të panjohur. Gjithashtu ndonjëherë dështon në testet bazë logjike, si p.sh. përcaktimi i gabuar se 9.9 është më pak se 9.11, një rast i njohur i testit logjik për modelet gjuhësore.
Ashtu si paraardhësi i tij Phi-1, parimi kryesor i Phi-4 fokusohet në cilësinë e të dhënave të trajnimit. Por ndërsa shumica e modeleve gjuhësore mbështeten kryesisht në përmbajtjen ose kodin e uebit, Microsoft mori një qasje të ndryshme me Phi-4, duke përdorur të dhëna sintetike të krijuara me kujdes “si tekstet shkollore” për trajnimin e tij para dhe në mes.
Ekipi krijoi 50 lloje të ndryshme të të dhënave sintetike në fusha të tilla si arsyetimi matematik, programimi dhe njohuritë e përgjithshme, duke arritur në rreth 400 miliardë argumente.
“Në vend që të shërbejnë si një zëvendësues i lirë për të dhënat organike, të dhënat sintetike kanë disa avantazhe të drejtpërdrejta mbi të dhënat organike,” thuhet në raportin teknik.
Studiuesit plotësuan këto të dhëna sintetike me burime organike të filtruara me kujdes, duke përfshirë dokumente publike dhe materiale edukative.
Microsoft zhvilloi gjithashtu metoda të reja trajnimi për të përmirësuar aftësinë e modelit për të dalluar përgjigjet me cilësi të lartë dhe me cilësi të ulët. Ekipi identifikoi “shenjat kryesore” – fjalë ose simbole specifike që mund të bëjnë ose prishin saktësinë e një përgjigjeje. Duke e trajnuar modelin për të njohur më mirë këto pika vendimtare kritike, ekipi përmirësoi performancën e përgjithshme të përgjigjes së pyetjeve.