Modele të reja gjuhësore të parashikimit me shumë shenja meta me burime të hapura

Meta Platforms Inc. ka katër modele gjuhësore me burim të hapur që zbatojnë një qasje në zhvillim të mësimit të makinerive të njohur si parashikim me shumë shenja.
VentureBeat raportoi publikimin e modeleve sot. Meta e vuri kodin e tyre të disponueshëm në HuggingFace, një platformë popullore për pritjen e projekteve të inteligjencës artificiale.

Modelet e mëdha gjuhësore gjenerojnë tekstin ose kodin që nxjerrin një shenjë në të njëjtën kohë. Një shenjë është një njësi e të dhënave që korrespondon me disa shkronja. Modelet e reja me burim të hapur të Metës, në të kundërt, gjenerojnë katër shenja në të njëjtën kohë. Ata e bëjnë këtë duke përdorur një teknikë përpunimi të njohur si parashikim me shumë shenja që kompania beson se mund t’i bëjë LLM-të më të shpejta dhe më të sakta.
Katër modelet e reja të Meta janë të orientuara drejt detyrave të gjenerimit të kodit dhe kanë 7 miliardë parametra secili. Dy u trajnuan në mostrat e kodit me vlerë 200 miliardë argumente, ndërsa çifti tjetër mori 1 trilion argumente secila. Në një punim që shoqëron modelet, Meta detajoi se ka zhvilluar gjithashtu një LLM të pestë ende të papublikuar me 13 miliardë parametra.
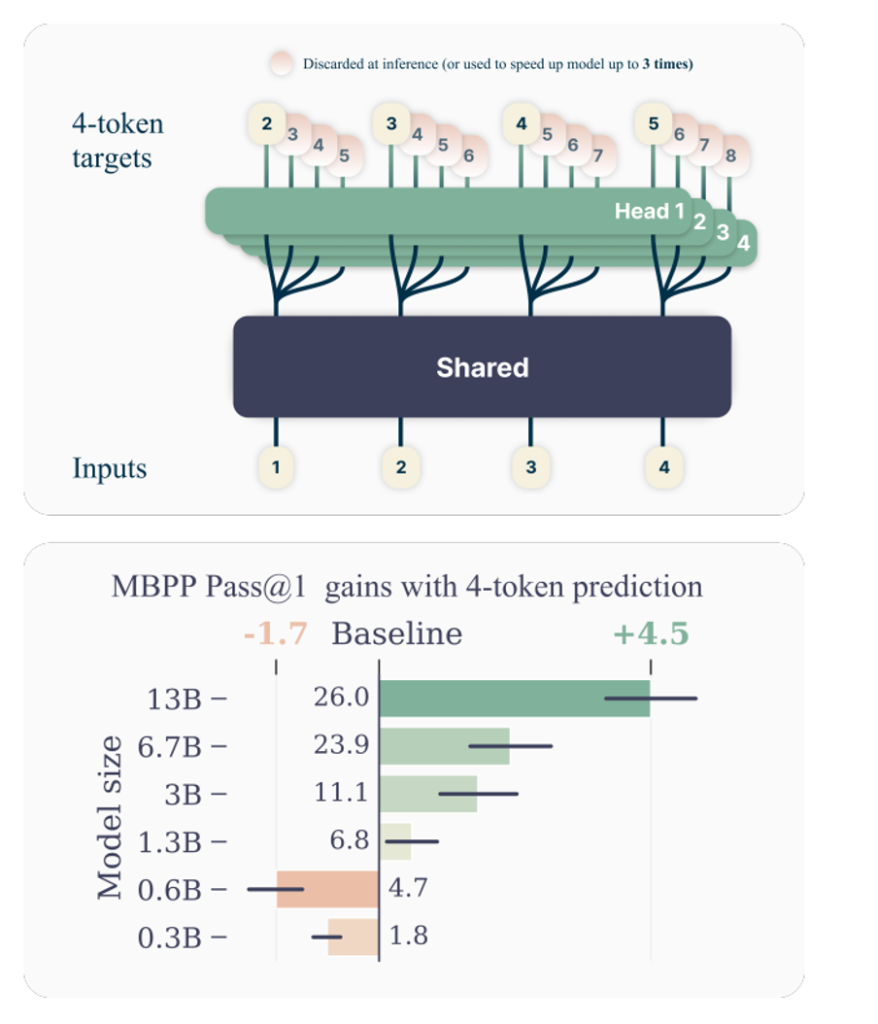
Nën kapuç, secili prej modeleve përbëhet nga dy komponentë kryesorë. E para është një i ashtuquajtur trunk i përbashkët që kryen llogaritjet fillestare të përfshira në gjenerimin e një fragmenti kodi. Sipas Metës, hapat e mëpasshëm të rrjedhës së punës së gjenerimit të kodit kryhen nga një grup i të ashtuquajturave koka dalëse. Ka katër koka dalëse që secila gjeneron një shenjë në të njëjtën kohë, gjë që u mundëson modeleve të Meta të prodhojnë katër token në të njëjtën kohë.
Aktualisht është e paqartë pse kjo qasje prodhon kod me cilësi më të lartë sesa modelet tradicionale LLM. Në punimin e tyre, studiuesit e Metës argumentojnë se arsyeja mund të ketë të bëjë me mënyrën se si janë ndërtuar modelet gjuhësore.
Zhvilluesit zakonisht trajnojnë LLM-të duke përdorur një teknikë të njohur si detyrimi i mësuesve. Metoda përfshin caktimin e një detyre për një model, si p.sh. gjenerimin e një pjese kodi, dhe më pas dhënien e përgjigjes së saktë nëse bën një gabim. Kjo qasje ndihmon në thjeshtimin e rrjedhës së punës së zhvillimit, por mund të kufizojë saktësinë e LLM që trajnohet.
Sipas studiuesve të Metës, është e mundur që gjenerimi i katër shenjave të prodhimit në të njëjtën kohë zbut kufizimet e qasjes së detyruar nga mësuesi. “Detyrimi i mësuesit, argumentojmë ne, inkurajon modelet që të fokusohen në parashikimin e mirë në një afat shumë të shkurtër, në kurriz të mundshëm të injorimit të varësive afatgjata në strukturën e përgjithshme të sekuencës së krijuar,” shpjeguan studiuesit.
Meta testoi saktësinë e modeleve të saj të parashikimit me shumë shenja duke përdorur testet e standardeve MBPP dhe HumanEval. MBPP përmban rreth 1000 detyra kodimi Python. HumanEval, nga ana tjetër, ofron një grup më kompleks detyrash kodimi që përfshijnë shumë gjuhë programimi.
Meta thotë se modelet e saj performuan 17% dhe 12% më mirë në MPP dhe HumanEval, respektivisht, sesa LLM-të e krahasueshme që gjenerojnë token një nga një. Për më tepër, modelet gjeneruan rezultate tre herë më shpejt.