Modelet e AI për video kanë arritur një kufi në arsyetim që vetëm më shumë të dhëna trajnimi nuk mund ta zgjidhin

Një ekip ndërkombëtar kërkimor ka publikuar të dhënat më të mëdha për arsyetimin me video deri më sot, afërsisht një mijë herë më të mëdha se alternativat e mëparshme. Rezultatet tregojnë se edhe Sora 2 dhe Veo 3.1 mbeten shumë prapa njerëzve kur bëhet fjalë për detyrat e arsyetimit.
Nëse një model video mund të zgjidhë një enigmë, të parashikojë një trajektore fizike ose të rendisë objektet sipas rregullave, mezi është studiuar në ndonjë mënyrë sistematike. Fushës thjesht i mungonin grupe të dhënash mjaftueshëm të mëdha, dhe testet e mëparshme të referencës përfshinin kryesisht të dhëna testimi, por asgjë për t’u trajnuar në të vërtetë.
Një konsorcium prej më shumë se 50 studiuesish nga 32 institucione – përfshirë UC Berkeley, Stanford, Harvard dhe Universitetin e Oksfordit – dëshiron ta ndryshojë këtë. Paketa e tyre Very Big Video Reasoning (VBVR) përfshin mbi dy milionë imazhe dhe rreth një milion klipe video të shpërndara në 200 detyra të kuruara. Nëntë teste ekzistuese kontribuojnë me afërsisht 12,800 mostra. Përveç të dhënave të testimit, VBVR ofron gjithashtu një milion shembuj trajnimi për herë të parë.
Detyrat ndjekin një taksonomi të bazuar në teoritë e njohjes njerëzore, që shtrihen nga aftësitë njohëse të Aristotelit deri te kategoritë e mendjes të Kantit. Studiuesit i ndajnë ato në pesë grupe: abstraksion, njohuri, perceptim, hapësirë dhe transformim. Çdo kategori funksionon në një gjenerator detyrash të parametrizuara që mund të prodhojë mijëra raste të ndryshme. Çdo detyrë duhet të ketë një zgjidhje unike dhe nuk mund të zgjidhet nga një imazh i vetëm statik.

Rezultatet e VBVR-Bench nuk janë të mira. Njerëzit marrin një rezultat të përgjithshëm prej 0.974. Sora 2 i OpenAI, modeli më i mirë në studim, arrin vetëm 0.546. Veo 3.1 i Google Deepmind vjen më pas me 0.480, Runway Gen-4 Turbo me 0.403 dhe Kling 2.6 i Kuaishou me 0.369. Modelet me burim të hapur Wan2.2, CogVideoX, HunyuanVideo dhe LTX-2 variojnë midis 0.273 dhe 0.371.
VBVR-Bench qëllimisht anashkalon përdorimin e një modeli gjuhësor si gjyqtar. Meqenëse shumica e detyrave kanë një përgjigje të vetme të saktë, rezultatet e bazuara në rregulla matin drejtpërdrejt saktësinë hapësinore, saktësinë e shtegut dhe vlefshmërinë logjike. Studiuesit verifikuan se këto rezultate automatike pasqyrojnë në mënyrë të besueshme cilësinë aktuale duke i kontrolluar ato kundrejt gjykimeve njerëzore, të cilat treguan një përputhje shumë të lartë statistikore.
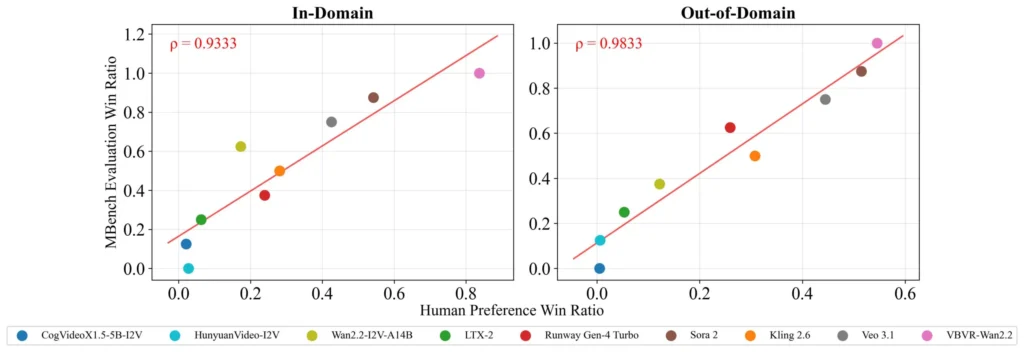
Zbulimi më i habitshëm vjen nga VBVR-Wan2.2, një version i përmirësuar i Wan2.2 . Rezultati i tij i përgjithshëm rritet në 0.685, një përmirësim prej 84.6 përqind krahasuar me modelin bazë, duke tejkaluar çdo sistem të patentuar në linjë.
Studimi i shkallëzimit tregon një histori më të ndërlikuar. Performanca në llojet e njohura të detyrave rritet në 0.771 me rreth 400,000 shembuj trajnimi dhe më pas arrin në pikën më të ulët. Në llojet krejtësisht të reja të detyrave, ajo arrin në 0.610, ende 15 pikë përqindjeje prapa. Studiuesit e shohin këtë si një pengesë themelore në arkitekturat aktuale të gjenerimit të videove, duke sugjeruar që hedhja e më shumë të dhënave për problemin nuk do ta zgjidhë atë.

Një analizë cilësore që krahason VBVR-Wan2.2 drejtpërdrejt me Sora 2 çon në një përfundim kyç: nëse një model rishkruan lirisht një skenë gjatë gjenerimit – duke ndërruar sfondet, paraqitjet ose identitetet e objekteve – gjendjet e ndërmjetme bëhen të pabesueshme dhe çdo arsyetim i ndërtuar mbi to bie poshtë.
Në një detyrë fshirjeje, për shembull, Sora 2 bën rirregullime të panevojshme pas heqjes së objektit të synuar, ndërsa VBVR-Wan2.2 ekzekuton vetëm atë që është kërkuar. Në një detyrë rrotullimi, Sora 2 nuk mund të dallojë ndryshimin midis rajonit të synuar dhe objektit që supozohet të manipulojë. VBVR-Wan2.2 madje mbledh aftësi emergjente përtej trajnimit të tij, si strategjitë e përfundimit të qëndrueshëm për detyrat e simetrisë. Megjithatë, dridhja dhe dublikimi shfaqen në sekuenca më të gjata.
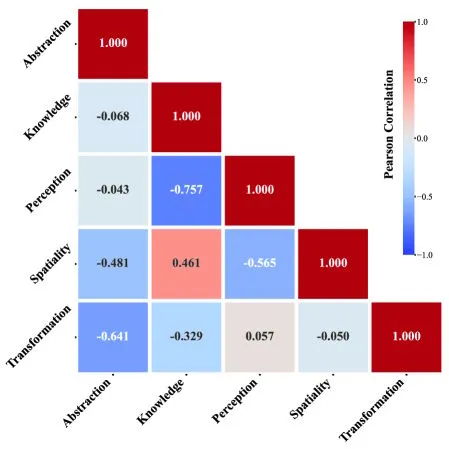
Një analizë korrelacioni në të gjitha modelet nxjerr në pah disa modele interesante. Modelet që kanë rezultate të mira në detyrat e njohurive kanë tendencë të jenë të forta edhe në detyrat hapësinore, gjë që përputhet me kërkimin e neuroshkencës mbi hipokampusin dhe rolin e tij të dyfishtë në navigim dhe të mësuarit konceptual.
Ana tjetër është më pak intuitive: performanca e fortë e njohurive në fakt korrelon me dobësi në perceptim. Abstraksioni nuk korrelon pozitivisht me asnjë aftësi tjetër, por modelet që shkëlqejnë në detyrat e abstraksionit në fakt kanë tendencë të jenë më të dobëta në transformim dhe arsyetim hapësinor.
Seti i plotë i të dhënave, mjetet e referencës dhe modelet janë të disponueshme publikisht në video-reason.com. Studiuesit theksojnë se përparimet arkitekturore si ndjekja e gjendjes dhe mekanizmat e vetë-korrigjimit do të jenë të nevojshme për të tejkaluar kufirin e performancës që kanë identifikuar.
Në shtator të vitit 2025, një studim që përfshinte Google Deepmind sugjeroi që modeli video Veo 3 i Google ka aftësi çuditërisht të gjithanshme me zero-shot: mund të zgjidhë labirinte, të dallojë simetri dhe të simulojë marrëdhënie fizike pa ndonjë trajnim specifik për detyrën. Studiuesit e morën këtë si një shenjë të hershme se modelet video mund të bëhen themele universale për vizionin automatik, ashtu si modelet e mëdha gjuhësore tashmë shërbejnë si shtylla kurrizore për përpunimin e tekstit. Disa, përfshirë CEO-n e Deepmind, Demis Hassabis, besojnë se modelet video përfundimisht mund të formojnë bazën për modelet botërore.