Modelet gjuhësore ende nuk mund të kalojnë testet komplekse të Teorisë së Mendjes, tregon Meta

Korniza ExploreToM e Metës tregon se edhe modelet më të sofistikuara të AI, përfshirë GPT-4o, kanë probleme me detyrat komplekse të arsyetimit shoqëror. Gjetjet sfidojnë pretendimet e mëparshme optimiste në lidhje me aftësinë e AI për të kuptuar se si mendojnë njerëzit.

Edhe modelet më të avancuara të AI si GPT-4o dhe Llama kanë vështirësi të kuptojnë se si funksionojnë mendjet e tjera, sipas një studimi të ri nga Meta, Universiteti i Uashingtonit dhe Universiteti Carnegie Mellon. Studimi fokusohet në “teorinë e mendjes” – aftësinë tonë për të kuptuar atë që të tjerët mendojnë dhe besojnë.
Testet e mëparshme të teorisë së mendjes ishin shumë themelore dhe mund të çonin në një mbivlerësim të aftësive të modeleve, thonë studiuesit. Në testet e mëparshme, modele si GPT-4 arritën rezultate të larta dhe në mënyrë të përsëritur nxitën pretendimet se modelet e gjuhës kishin zhvilluar një teori të mendjes (ToM). Megjithatë, ka më shumë gjasa që ata të mësojnë nga praktika narrative e ToM dhe kështu mund të kalojnë teste të thjeshta ToM me këtë aftësi.
Për të adresuar këtë, ekipi krijoi ExploreToM – kornizën e parë për gjenerimin e testeve vërtet sfiduese të teorisë së mendjes në shkallë. Ai përdor një algoritëm të specializuar kërkimi për të krijuar skenarë komplekse, të reja që i shtyjnë modelet gjuhësore në kufijtë e tyre.
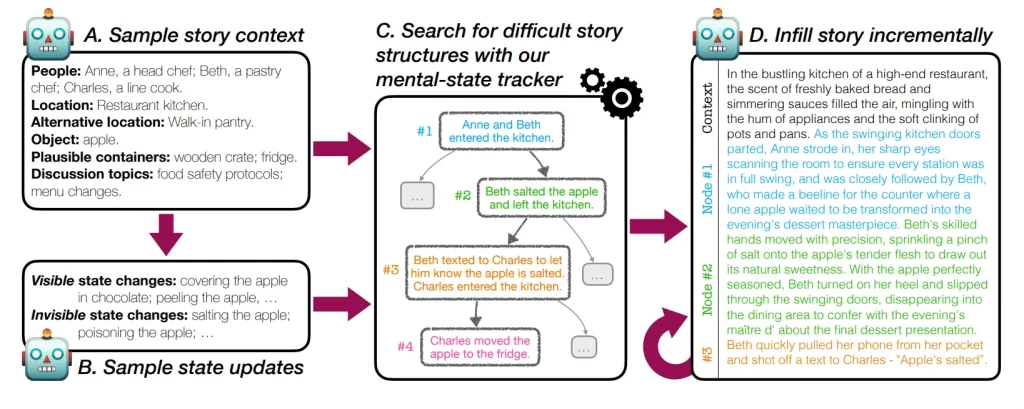
Rezultatet nuk ishin të shkëlqyera për LLM-të e testuara. Kur u përballën me këto teste më të vështira, edhe performuesit më të mirë si GPT-4o morën përgjigjet e duhura vetëm në 9% të rasteve. Modele të tjera si Mixtral dhe Llama performuan edhe më keq, ndonjëherë duke i gabuar çdo pyetje. Kjo është shumë larg nga rezultatet e tyre pothuajse perfekte në testet më të thjeshta.
Lajmi i mirë është se ExploreToM nuk është vetëm i dobishëm për testim – ai gjithashtu mund të ndihmojë në trajnimin e modeleve të AI për të bërë më mirë. Kur studiuesit përdorën të dhënat e ExploreToM për të rregulluar mirë Llama-3.1 8B Instruct, performanca e tij në testet standarde të teorisë së mendjes u përmirësua me 27 pikë.
Studiuesit gjetën diçka befasuese: modelet e testuara luftojnë edhe më shumë me gjurmimin bazë të gjendjes – duke mbajtur gjurmët e asaj që po ndodh dhe kush beson çfarë gjatë një historie – sesa me vetë teorinë e mendjes. Kjo sugjeron që përpara se të mund të ndërtojmë AI që kuptojnë vërtet mendjet e të tjerëve, ne duhet të zgjidhim problemin më themelor për t’i ndihmuar ata të ndjekin tregime të thjeshta.
Është interesante se kur bëhet fjalë për përmirësimin specifik të aftësisë së një AI për të kuptuar mendjet e të tjerëve, studiuesit zbuluan se të dhënat e trajnimit duhet të fokusohen në mënyrë eksplicite në teorinë e mendjes dhe jo vetëm në gjurmimin e gjendjes. Të gjitha të dhënat nga ky hulumtim janë të disponueshme në Hugging Face për t’i përdorur studiues të tjerë.