Modelet gjuhësore të mëdha (LLM) hasin vështirësi me arsyetimin klinik dhe thjesht po përputhin modele

Një studim i ri në JAMA Network Open ngre dyshime të reja nëse modelet e mëdha gjuhësore (LLM) mund të arsyetojnë në të vërtetë përmes rasteve mjekësore apo nëse ato thjesht përputhen me modele që kanë parë më parë. Studiuesit thonë se këto modele nuk janë gati për punë klinike.
Studiuesit e udhëhequr nga Suhana Bedi filluan me 100 pyetje nga testi standard MedQA, një test standard me zgjedhje të shumëfishta për njohuritë mjekësore. Për secilën pyetje, ata zëvendësuan përgjigjen e saktë me “Asnjë nga përgjigjet e tjera” (NOTA).
Një ekspert klinik shqyrtoi çdo pyetje të modifikuar për të konfirmuar se NOTA ishte e vetmja përgjigje e saktë. Në fund, 68 pyetje përmbushën këtë standard. Për t’i zgjidhur këto pyetje saktë, studentët e LLM-së duhej të pranonin se asnjë nga opsionet e zakonshme nuk zbatohej dhe të zgjidhnin NOTA-n në vend të saj. Kjo krijoi një test të drejtpërdrejtë: a mund të arsyetojnë vërtet studentët e LLM-së, apo thjesht po ndjekin modele përgjigjesh të njohura nga trajnimi?
Çdo model pati rënie të saktësisë kur u përball me pyetjet e rishikuara, por disa prej tyre hasën shumë më tepër vështirësi se të tjerët. LLM-të standarde si Claude 3.5 (-26.5 pikë përqindjeje), Gemini 2.0 (-33.8), GPT-4o (-36.8) dhe LLaMA 3.3 (-38.2) pësuan të gjitha një goditje të madhe.
Modelet e fokusuara në arsyetim si Deepseek-R1 (-8.8) dhe o3-mini (-16.2) rezistuan më mirë, por prapëseprapë humbën terren. Studiuesit provuan gjithashtu nxitje të “zinxhirit të mendimit”, duke u kërkuar modeleve të paraqisnin arsyetimin e tyre hap pas hapi, por as kjo nuk i ndihmoi modelet të arrinin me besueshmëri përgjigjen e saktë mjekësore.
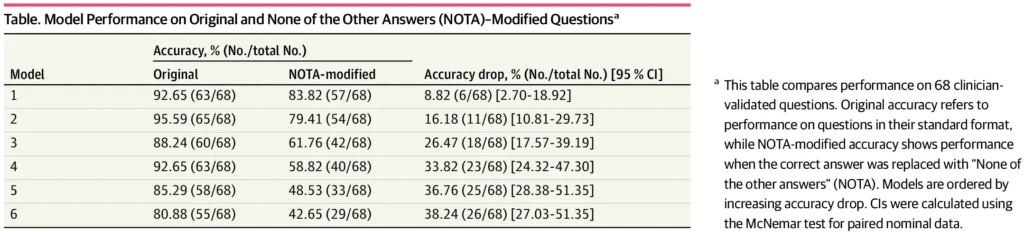
Sipas autorëve, këto rezultate nxjerrin në pah një problem thelbësor: modelet e sotme mbështeten kryesisht në përputhjen statistikore të modeleve, jo në arsyetimin e vërtetë. Disa prej tyre kanë rënë nga 80 në 42 përqind saktësi me vetëm ndryshime të vogla në pyetje. Kjo i bën ato të rrezikshme për praktikën mjekësore, ku rastet e pazakonta ose komplekse janë të zakonshme.
Mjekët shpesh hasin gjendje të rralla ose simptoma të papritura që nuk përputhen me modelet e teksteve shkollore. Nëse LLM-të thjesht përputhen me përgjigje të njohura në vend që të arsyetojnë për secilin rast, ka të ngjarë që ata të mos i interpretojnë ose t’i keqinterpretojnë këto raste të jashtëzakonshme. Gjetjet vënë në pikëpyetje nëse LLM-të aktuale janë mjaftueshëm të forta ose të besueshme për përdorim klinik, pasi mjekësia kërkon sisteme që mund të përballojnë paqartësinë dhe të përshtaten me situata të reja.
Është e njohur mirë se studentët e LLM-së mund të japin përgjigje krejtësisht të ndryshme nëse pyetja ndryshon pak ose përfshin informacione të parëndësishme. Edhe modelet e fokusuara në arsyetim nuk janë imune ndaj këtij problemi.
Por ende nuk është e qartë nëse këtyre sistemeve u mungojnë vërtet aftësitë e arsyetimit logjik apo thjesht nuk mund t’i zbatojnë ato në mënyrë të besueshme. Aktualisht, debatet rreth “arsyetimit” të LLM-së janë të bllokuara nga përkufizime të paqarta dhe standarde të paqarta, gjë që e bën të vështirë gjykimin se çfarë mund të bëjnë në të vërtetë këto modele.