Modeli i ri Spark i OpenAI programon 15 herë më shpejt se GPT-5.3-Codex

GPT-5.3-Codex-Spark i ri i OpenAI premton kodim ultra të shpejtë dhe bisedor me anë të inteligjencës artificiale, nëse mund të toleroni disa kompromise.
Ekipi i Codex në OpenAI është në zjarr. Më pak se dy javë pasi publikoi një aplikacion Codex të dedikuar për Mac të bazuar në agjentë, dhe vetëm një javë pasi publikoi modelin e gjuhës GPT-5.3-Codex më të shpejtë dhe më të menaxhueshëm, OpenAI po mbështetet te rrufeja që bie për herë të tretë.
Sot, kompania ka njoftuar një vrojtim kërkimor të GPT-5.3-Codex-Spark, një version më i vogël i GPT-5.3-Codex i ndërtuar për kodim në kohë reale në Codex. Kompania raporton se gjeneron kod 15 herë më shpejt, ndërsa “mbetet shumë i aftë për detyra kodimi në botën reale”. Ka një problem dhe do të flas për të pas pak.
Codex-Spark fillimisht do të jetë i disponueshëm vetëm për përdoruesit e nivelit Pro me çmim 200 dollarë/muaj, me kufizime të veçanta çmimesh gjatë periudhës së parapamjes. Nëse ndjek strategjinë e zakonshme të publikimit të OpenAI për publikimet e Codex, përdoruesit Plus do të jenë të radhës, me nivelet e tjera që do të fitojnë akses mjaft shpejt.
(Zbulim: Ziff Davis, kompania mëmë e ZDNET, ngriti një padi në prill 2025 kundër OpenAI, duke pretenduar se ajo kishte shkelur të drejtat e autorit të Ziff Davis në trajnimin dhe operimin e sistemeve të saj të inteligjencës artificiale.)
OpenAI thotë se Codex-Spark është “modeli i saj i parë i projektuar posaçërisht për të punuar me Codex në kohë reale — duke bërë redaktime të synuara, duke riformësuar logjikën ose duke rafinuar ndërfaqet dhe duke parë rezultate menjëherë”.
Le ta dekonstruktojmë shkurtimisht këtë. Shumica e mjeteve të programimit të inteligjencës artificiale agjentike kërkojnë pak kohë për t’iu përgjigjur udhëzimeve. Në punën time të programimit, unë mund të jap një udhëzim (dhe kjo vlen si për Codex ashtu edhe për Claude Code) dhe të iki e të punoj në diçka tjetër për një kohë. Ndonjëherë janë vetëm disa minuta. Herë të tjera, mund të jetë mjaftueshëm e gjatë për të ngrënë drekë.
Me sa duket, Codex-Spark është në gjendje të përgjigjet shumë më shpejt, duke lejuar punë të shpejtë dhe të vazhdueshme. Kjo mund ta përshpejtojë ndjeshëm zhvillimin, veçanërisht për kërkesa dhe pyetje më të thjeshta.
E di që herë pas here jam mërzitur kur i kam bërë një IA-je një pyetje shumë të thjeshtë që duhej të kishte gjeneruar një përgjigje të menjëhershme, por në vend të kësaj më është dashur të prisja pesë minuta për një përgjigje.
Duke e bërë reagimin ndaj mesazheve një veçori thelbësore, modeli mbështet kodim më fluid dhe bisedor. Ndonjëherë, përdorimi i agjentëve të kodimit duket më shumë si kodim i stilit të vjetër në grupe. Ky është projektuar për të kapërcyer këtë ndjesi.
GPT-5.3-Codex-Spark nuk ka për qëllim të zëvendësojë GPT-5.3-Codex bazë. Në vend të kësaj, Spark u krijua për të plotësuar modelet e inteligjencës artificiale me performancë të lartë të ndërtuara për detyra autonome dhe afatgjata që zgjasin me orë, ditë ose javë.
Modeli Codex-Spark është menduar për punë ku reagimi ka po aq rëndësi sa inteligjenca. Ai mbështet ndërprerjen dhe ridrejtimin në mes të detyrës, duke mundësuar cikle të ngushta përsëritjeje.
Kjo është diçka që më tërheq, sepse gjithmonë mendoj për diçka më shumë për t’i thënë IA-së dhjetë sekonda pasi i kam dhënë një detyrë.
Modeli Spark, si parazgjedhje, përdor redaktime të lehta dhe të synuara, duke bërë ndryshime të shpejta në vend që të marrë ndryshime të mëdha. Gjithashtu, nuk kryen automatikisht teste, përveç nëse kërkohet.
OpenAI ka qenë në gjendje të zvogëlojë vonesën (kthim më të shpejtë) në të gjithë rrjedhën e kërkesës-përgjigjes. Ai thotë se shpenzimet e përgjithshme për çdo udhëtim vajtje-ardhje klient/server janë zvogëluar me 80%. Shpenzimet e përgjithshme për çdo token janë zvogëluar me 30%. Koha deri te tokeni i parë është zvogëluar me 50% përmes inicializimit të seancës dhe optimizimeve të transmetimit.
Një mekanizëm tjetër që përmirëson reagimin gjatë përsëritjes është futja e një lidhjeje të përhershme WebSocket, kështu që lidhja nuk ka nevojë të rinegociohet vazhdimisht.
Në janar, OpenAI njoftoi një partneritet me prodhuesin e çipave të inteligjencës artificiale, Cerebras. Ne kemi trajtuar Cerebras për njëfarë kohe. Kemi trajtuar shërbimin e tij të nxjerrjes së përfundimeve, punën e tij me DeepSeek, punën e tij në rritjen e performancës së modelit Llama të Meta-s dhe njoftimin e Cerebras për një çip të inteligjencës artificiale vërtet të madh , që synon të dyfishojë performancën e LLM.
GPT-5.3-Codex-Spark është arritja e parë e rëndësishme për partneritetin OpenAI/Cerebras të njoftuar muajin e kaluar. Modeli Spark funksionon në Wafer Scale Engine 3 të Cerebras, i cili është një arkitekturë çipi AI me performancë të lartë që rrit shpejtësinë duke i vendosur të gjitha burimet llogaritëse në një procesor të vetëm në shkallë wafer, me madhësinë e një petulle.
Zakonisht, një pllakë gjysmëpërçuese përmban një mori procesorësh, të cilët më vonë në procesin e prodhimit priten dhe vendosen në paketimin e tyre. Pllaka Cerebras përmban vetëm një çip, duke e bërë atë një procesor shumë, shumë të madh me lidhje shumë, shumë të lidhura ngushtë.
Sipas Sean Lie, CTO dhe bashkëthemelues i Cerebras, “Ajo që na emocionon më shumë te GPT-5.3-Codex-Spark është partneriteti me OpenAI dhe komunitetin e zhvilluesve për të zbuluar se çfarë bën të mundur nxjerrja e përfundimeve të shpejta — modele të reja ndërveprimi, raste të reja përdorimi dhe një përvojë modeli thelbësisht të ndryshme. Ky parapamje është vetëm fillimi.”
Tani, ja ku janë të metat.
Së pari, OpenAI thotë se “kur kërkesa është e lartë, mund të shihni akses më të ngadaltë ose radhë të përkohshme ndërsa balancojmë besueshmërinë midis përdoruesve”. Pra, shpejt, përveç nëse shumë njerëz duan të shkojnë shpejt.
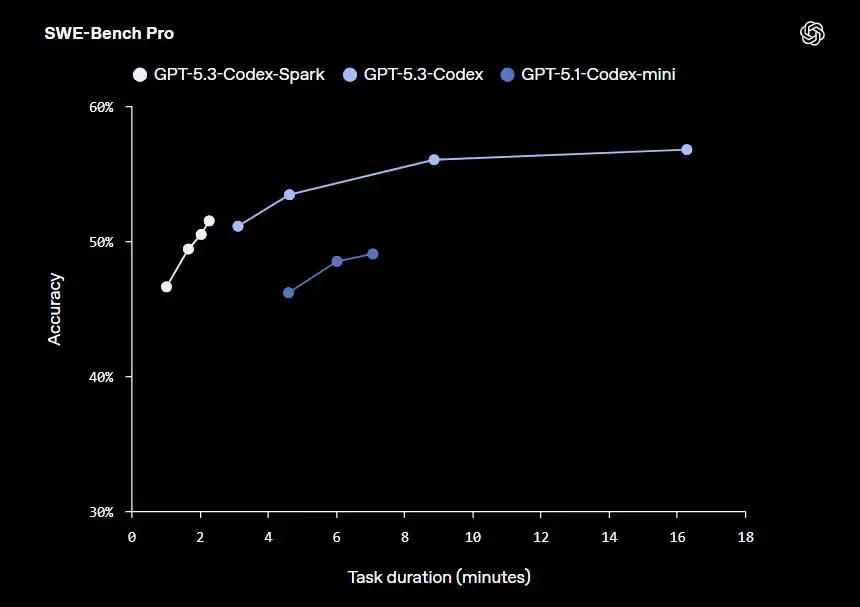
Ja ku është pika kyçe. Kompania thotë, “Në SWE-Bench Pro dhe Terminal-Bench 2.0, dy teste që vlerësojnë aftësitë e inxhinierisë së softuerëve agjentë, GPT-5.3-Codex-Spark ka performancë më të dobët se GPT-5.3-Codex, por mund t’i kryejë detyrat në një kohë shumë më të shkurtër.”
Javën e kaluar, në njoftimin për GPT-5.3-Codex, OpenAI tha se GPT-5.3-Codex ishte modeli i parë që klasifikoi si “aftësi të lartë” për sigurinë kibernetike, sipas Kornizës së saj të Përgatitjes të publikuar. Nga ana tjetër, kompania pranoi se GPT-5.3-Codex-Spark “nuk ka një shans të besueshëm për të arritur pragun e Kornizës sonë të Përgatitjes për aftësi të larta në sigurinë kibernetike”.
Mendo për këto pohime, lexues i dashur. Kjo IA nuk është aq e zgjuar, por i bën ato gjëra jo aq të zgjuara shumë më shpejt. Shpejtësia 15 herë më e madhe nuk është aspak për t’u nënçmuar. Por a doni vërtet që një IA të bëjë gabime kodimi 15 herë më shpejt dhe të prodhojë kod që është më pak i sigurt?
Më lejo të të them këtë. “Ëh, mjafton” nuk mjafton kur ke mijëra përdorues të inatosur që të sulmojnë me pishtarë dhe sfurqe sepse papritmas ua prishe programin me një version të ri. Më pyet si e di.
Javën e kaluar, mësuam se OpenAI përdor Codex për të shkruar Codex. Gjithashtu e dimë se e përdor atë për të qenë në gjendje të ndërtojë kod shumë më shpejt. Pra, kompania ka qartë një rast përdorimi për diçka që është shumë më e shpejtë, por jo aq inteligjente. Ndërsa e kuptoj më mirë se çfarë është kjo dhe ku përshtatet Spark, do t’ju njoftoj.
OpenAI ndau se po punon drejt mënyrave të dyfishta të arsyetimit dhe punës në kohë reale për modelet e saj Codex.
Kompania thotë, “Codex-Spark është hapi i parë drejt një Codex me dy mënyra plotësuese: arsyetim dhe ekzekutim me horizont më të gjatë, dhe bashkëpunim në kohë reale për përsëritje të shpejtë. Me kalimin e kohës, mënyrat do të përzihen.”
Modeli i rrjedhës së punës që parashikon është interesant. Sipas OpenAI, qëllimi është që përfundimisht “Codex t’ju mbajë në një cikël të ngushtë ndërveprues, ndërsa delegon punë më të gjata te nën-agjentët në sfond, ose shpërndan detyrat në shumë modele paralelisht kur dëshironi gjerësi dhe shpejtësi, kështu që nuk keni nevojë të zgjidhni një modalitet të vetëm paraprakisht”.
Në thelb, po punon drejt më të mirës së të dy botëve. Por tani për tani, mund të zgjidhni midis shpejtësisë dhe saktësisë. Kjo është një zgjedhje e vështirë. Por saktësia po bëhet gjithnjë e më e saktë dhe tani, të paktën, mund të zgjidhni shpejtësinë kur ta dëshironi (për sa kohë që mbani parasysh kompromiset dhe paguani për nivelin Pro).
Po ju? A do të ndërronit disa aftësi inteligjence dhe sigurie për përgjigje kodimi 15 herë më të shpejta? A ju tërheq ideja e një bashkëpunëtori të inteligjencës artificiale në kohë reale dhe të ndërprerë, apo preferoni një model më të qëllimshëm dhe me saktësi më të lartë për punë serioze zhvillimi?
Sa të shqetësuar jeni për dallimin në sigurinë kibernetike midis Codex-Spark dhe modelit të plotë GPT-5.3-Codex? Dhe nëse jeni përdorues Pro, a e shihni veten duke kaluar midis modaliteteve “të shpejta” dhe “inteligjente” në varësi të detyrës?