Një studim i ri i Apple tregon se modelet e mëdha gjuhësore (LLM) mund të zbulojnë çfarë po bëni përmes të dhënave audio dhe të lëvizjes

Studiuesit e Apple kanë publikuar një studim që shqyrton se si LLM-të mund të analizojnë të dhënat audio dhe të lëvizjes për të pasur një pasqyrë më të mirë të aktiviteteve të përdoruesit.
Një punim i ri i titulluar ” Përdorimi i LLM-ve për Bashkimin e Vonë Multimodal të Sensorëve për Njohjen e Aktivitetit ” ofron një pasqyrë se si Apple mund të jetë duke marrë në konsideratë përfshirjen e analizës LLM së bashku me të dhënat tradicionale të sensorëve për të fituar një kuptim më të saktë të aktivitetit të përdoruesit.
Kjo, argumentojnë ata, ka potencial të madh për ta bërë analizën e aktivitetit më të saktë, edhe në situata kur nuk ka të dhëna të mjaftueshme nga sensorët.
Nga studiuesit:
“Rrjedhat e të dhënave të sensorëve ofrojnë informacion të vlefshëm rreth aktiviteteve dhe kontekstit për aplikacionet pasuese, megjithëse integrimi i informacionit plotësues mund të jetë sfidues. Ne tregojmë se modelet e mëdha gjuhësore (LLM) mund të përdoren për bashkim të vonë për klasifikimin e aktiviteteve nga të dhënat e serive kohore audio dhe lëvizjeje. Ne kemi kuruar një nëngrup të të dhënave për njohje të larmishme të aktiviteteve në të gjitha kontekstet (p.sh., aktivitete shtëpiake, sporte) nga të dhënat Ego4D. LLM-të e vlerësuara arritën rezultate F1 të klasifikimit zero dhe me një goditje me 12 klasa, dukshëm mbi shansin, pa trajnim specifik për detyrën. Klasifikimi me zero goditje nëpërmjet bashkimit të bazuar në LLM nga modelet specifike të modalitetit mund të mundësojë aplikacione kohore multimodale ku ka të dhëna të kufizuara trajnimi të harmonizuara për të mësuar një hapësirë të përbashkët ngulitjeje. Për më tepër, bashkimi i bazuar në LLM mund të mundësojë vendosjen e modelit pa kërkuar memorie dhe llogaritje shtesë për modele multimodale specifike për aplikacionin e synuar.”
Me fjalë të tjera, LLM-të janë në fakt mjaft të mirë në nxjerrjen e përfundimeve se çfarë po bën një përdorues nga sinjalet bazë audio dhe lëvizjeje, edhe kur nuk janë trajnuar posaçërisht për këtë. Për më tepër, kur u jepet vetëm një shembull i vetëm, saktësia e tyre përmirësohet edhe më tej.
Një dallim i rëndësishëm është se në këtë studim, LLM-së nuk iu dha regjistrimi aktual audio, por përkundrazi, përshkrime të shkurtra me tekst të gjeneruara nga modelet audio dhe një model lëvizjeje i bazuar në IMU (i cili gjurmon lëvizjen përmes të dhënave të akselerometrit dhe xhiroskopit), siç tregohet më poshtë:
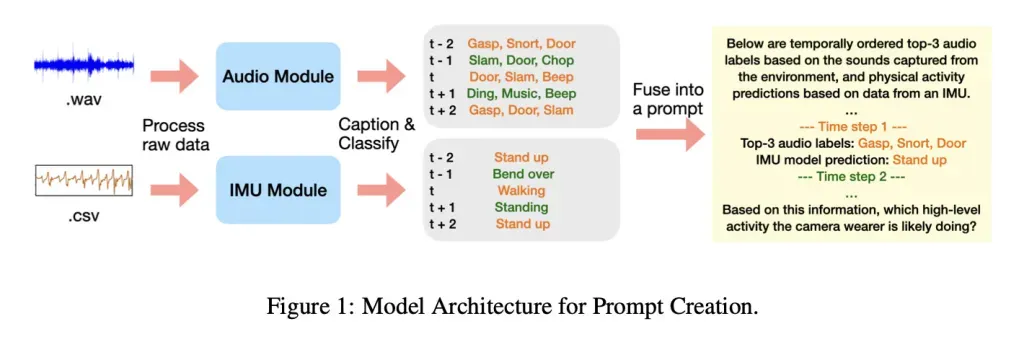
Në punim, studiuesit shpjegojnë se përdorën Ego4D, një grup të dhënash masive mediash të xhiruara në perspektivën e personit të parë. Të dhënat përmbajnë mijëra orë mjedise dhe situata të botës reale, nga detyrat shtëpiake deri te aktivitetet në natyrë.
Nga studimi:
“Ne kemi kuruar një set të dhënash të aktiviteteve të përditshme nga seti i të dhënave Ego4D duke kërkuar aktivitete të jetës së përditshme brenda përshkrimeve narrative të ofruara. Seti i të dhënave i kuruar përfshin mostra 20 sekondëshe nga dymbëdhjetë aktivitete të nivelit të lartë: pastrim me fshesë me korrent, gatim, larje rrobash, të ngrënit, të luajturit basketboll, të luajturit futboll, të luajturit me kafshët shtëpiake, leximi i një libri, përdorimi i një kompjuteri, larja e enëve, shikimi i televizorit, stërvitja/ngritja e peshave. Këto aktivitete u përzgjodhën për të përfshirë një gamë të detyrave shtëpiake dhe të fitnesit, dhe bazuar në përhapjen e tyre në setin më të gjerë të të dhënave.”
Studiuesit i kaluan të dhënat audio dhe të lëvizjes përmes modeleve më të vogla që gjeneruan mbishkrime teksti dhe parashikime të klasës, më pas i futën këto rezultate në LLM të ndryshme (Gemini-2.5-pro dhe Qwen-32B) për të parë se sa mirë mund ta identifikonin aktivitetin.
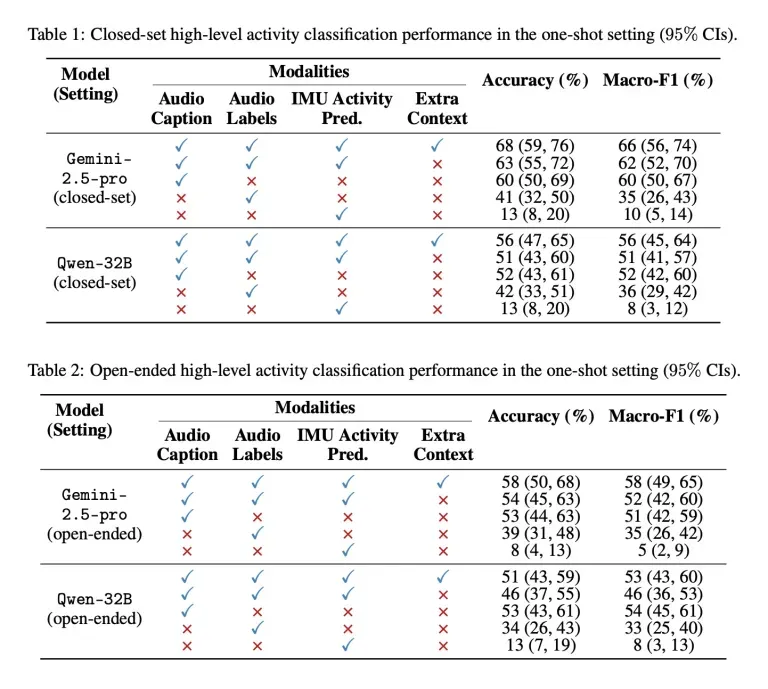
Pastaj, Apple krahasoi performancën e këtyre modeleve në dy situata të ndryshme: njëra në të cilën atyre iu dha lista e 12 aktiviteteve të mundshme për të zgjedhur (grup i mbyllur) dhe një tjetër ku atyre nuk iu dha asnjë opsion (i hapur).
Për secilin test, atyre iu dhanë kombinime të ndryshme të titrave audio, etiketave audio, të dhënave të parashikimit të aktivitetit të IMU-së dhe kontekstit shtesë, dhe ja si vepruan ata:
Në fund, studiuesit vërejnë se rezultatet e këtij studimi ofrojnë njohuri interesante se si kombinimi i modeleve të shumëfishta mund të sjellë përfitime për të dhënat e aktivitetit dhe shëndetit, veçanërisht në rastet kur të dhënat e papërpunuara të sensorëve vetëm nuk janë të mjaftueshme për të dhënë një pamje të qartë të aktivitetit të përdoruesit.
Ndoshta më e rëndësishmja, Apple publikoi materiale plotësuese së bashku me studimin, duke përfshirë ID-të e segmenteve Ego4D, pullat kohore, udhëzimet dhe shembujt e njëhershëm të përdorur në eksperimente, për të ndihmuar studiuesit e interesuar në riprodhimin e rezultateve.