Pretendimet e Apple për modelet e mëdha të arsyetimit përballen me shqyrtim të ri nga një studim i fundit
Një studim i përsëritur i punimit kontrovers të Apple “Iluzioni i të Menduarit” konfirmon disa nga kritikat e tij kryesore, por sfidon përfundimin qendror të studimit.
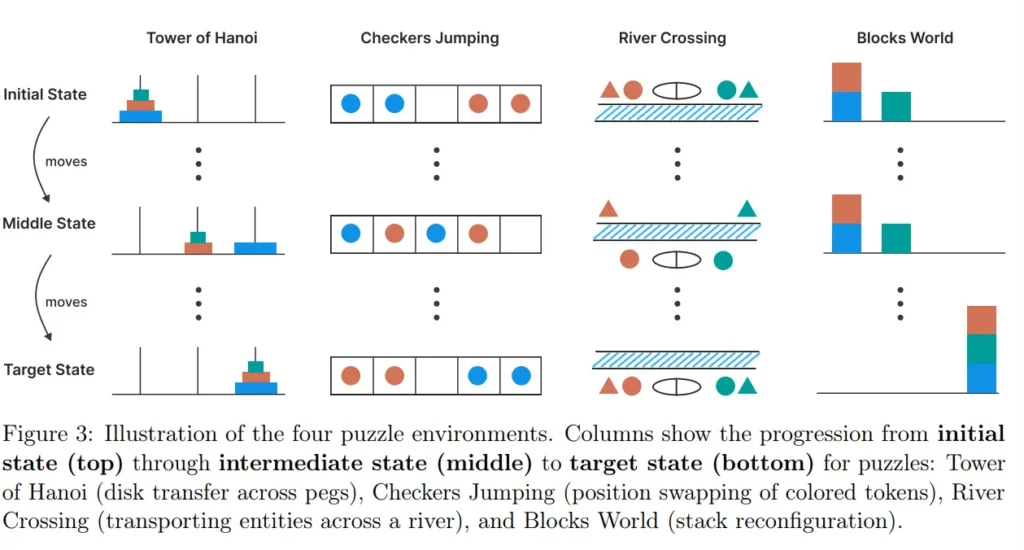
Studiues nga Qendra CSIC-UPM për Automatizim dhe Robotikë në Spanjë rikrijuan dhe zgjeruan eksperimentet kryesore nga puna origjinale e Apple, e cila u shfaq për herë të parë në qershor 2025 dhe shkaktoi debate të mëdha në komunitetin e IA-së. Pretendimi i Apple ishte se edhe modelet më të fundit të arsyetimit të madh (LRM) kanë vështirësi me detyrat që kërkojnë planifikim simbolik bazë. Studimi zbuloi se performanca e këtyre modeleve bie ndjeshëm kur kompleksiteti i detyrave rritet përtej një niveli të moderuar dhe se ato ndonjëherë veprojnë tepër të kujdesshëm me probleme më të thjeshta.
Studimi i ri mbështet kryesisht vëzhgimet e Apple, por kundërshton interpretimin e tyre. Ekipi spanjoll argumenton se mangësitë e modeleve nuk janë vetëm për shkak të mungesës së “aftësisë së të menduarit”, por rrjedhin edhe nga mënyra se si janë hartuar detyrat, si janë strukturuar kërkesat dhe metodat stokastike të optimizimit të përdorura.
Për të testuar planifikimin afatgjatë, studiuesit përdorën enigmën klasike të Kullave të Hanoi-t me modele si Gemini 2.5 Pro. Ata e ndanë problemin në nëndetyra më të vogla, në mënyrë që modelet të mos kishin nevojë ta gjeneronin të gjithë zgjidhjen menjëherë.
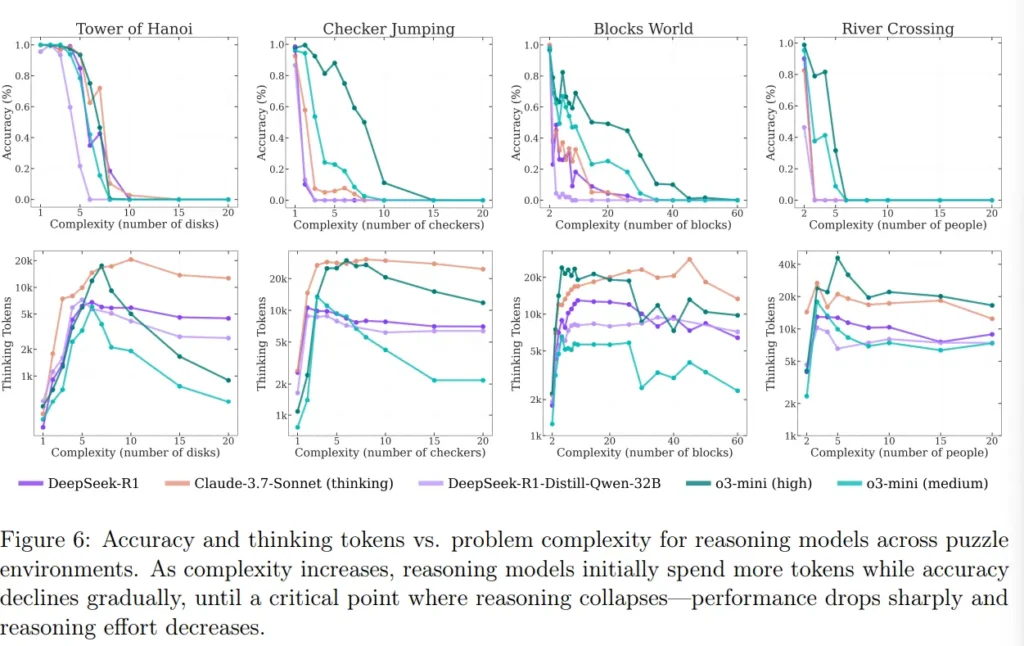
Kjo zgjidhje hap pas hapi funksionoi mjaft mirë për konfigurime me deri në shtatë disqe. Por performanca ra me tetë ose më shumë disqe, duke përputhur rënien e papritur në studimin e Apple ndërsa kompleksiteti rritej.
Interpretimi i ri e thekson përdorimin e tokenëve si çelës: numri i tokenëve që modeli shpenzon e ndjek nga afër nëse beson se një zgjidhje është e mundur. Për sa kohë që modeli mendon se mund ta zgjidhë detyrën, ai rrit përdorimin e burimeve. Nëse vendos se problemi është i pazgjidhshëm, ai ndërpritet shpejt – duke sugjeruar një lloj menaxhimi të pasigurisë implicite.
Studiuesit provuan gjithashtu një qasje me shumë agjentë, ku dy modele gjuhësore propozuan me radhë hapa zgjidhjeje. Kjo çoi në shkëmbime të gjata dhe konsum të lartë të tokenëve, por rrallë prodhoi zgjidhje të vlefshme.
Ndërkohë që modelet ndiqnin të gjitha rregullat, ato shpesh ngecnin në cikle të pafundme lëvizjesh të vlefshme, por të parëndësishme. Autorët arrijnë në përfundimin se modeleve u mungon aftësia për të njohur dhe ekzekutuar strategji të nivelit më të lartë, edhe kur ato veprojnë simbolikisht saktë.
Ndryshe nga Apple, e cila i pa këto dështime si dëshmi të mungesës së aftësive njohëse, ekipi spanjoll fajëson gjithashtu strukturën e shpejtë dhe mungesën e mekanizmave globalë të kërkimit.