VibeVoice i Microsoft është një model i ri podcast-i me AI që mund të gjenerojë edhe këndim spontan

Sistemi VibeVoice i Microsoft mund të gjenerojë deri në 90 minuta bisedë që përfshin deri në katër folës.
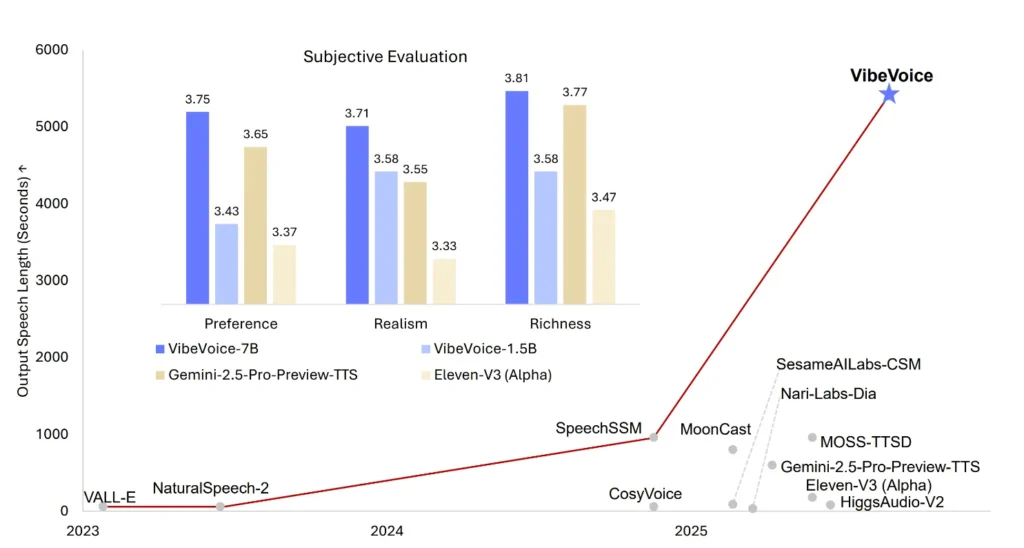
Modelet e mëparshme të gjenerimit të të folurit zakonisht kishin vështirësi me daljet më të gjata ose bisedat në grup. Sipas raportit teknik të Microsoft, VibeVoice është i pari që trajton biseda në grup që zgjasin një orë e gjysmë në një ekzekutim të vetëm.
Çelësi është një metodë e re e kompresimit të audios. Studiuesit e Microsoft zhvilluan një Speech Tokenizer që është 80 herë më efikas se qasjet e mëparshme, në mënyrë që sistemi të mund të gjenerojë dhe ruajë biseda të gjata pa hasur probleme me kujtesën.
Në demo, disa shembuj përfshijnë muzikë në sfond, por dokumenti teknik e bën të qartë se vetë modeli është i fokusuar vetëm në sintezën e të folurit dhe nuk përpunon zhurmën në sfond, muzikën ose efekte të tjera zanore. Deri më tani, VibeVoice mbështet anglishten dhe kinezishten, me disa veçori ndërgjuhësore.
Një shembull i aftësive të VibeVoice për të shkruar me format të gjatë është një bisedë 93-minutëshe rreth ndryshimeve klimatike me katër folës të ndryshëm. Sistemi prodhon dinamika realiste diskutimi, mosmarrëveshje dhe reagime emocionale, së bashku me pauza natyrale, tranzicione të buta midis folësve dhe intonacion të varur nga konteksti.
VibeVoice e ndan përpunimin në dy pjesë: njëra merret me cilësinë e zërit dhe zërin, tjetra menaxhon kuptimin dhe rrjedhën e bisedës. Ai përdor një model të para-trajnuar të të folurit Qwen2.5 (1.5 ose 7 miliardë parametra) për të kontrolluar dialogun, ndërsa një kokë difuzioni me katër shtresa me rreth 123 milionë parametra gjeneron audion.