Prezantohet Claude Opus 4.6

Claude Opus 4.6 i ri përmirëson aftësitë e kodimit të paraardhësit të tij. Ai planifikon më me kujdes, mbështet detyrat agjentike për më gjatë, mund të funksionojë më me besueshmëri në baza kodi më të mëdha dhe ka aftësi më të mira për rishikimin e kodit dhe debugging për të kapur gabimet e veta. Dhe, për herë të parë për modelet tona të klasës Opus, Opus 4.6 përmban një dritare konteksti prej 1 milion tokenësh në beta.
Opus 4.6 mund t’i zbatojë gjithashtu aftësitë e tij të përmirësuara në një gamë të gjerë detyrash të përditshme pune: kryerjen e analizave financiare, kryerjen e kërkimeve dhe përdorimin e krijimin e dokumenteve, spreadsheet-eve dhe prezantimeve. Brenda Cowork, ku Claude mund të kryejë shumë detyra njëkohësisht në mënyrë autonome, Opus 4.6 mund t’i vërë të gjitha këto aftësi në punë për ju.
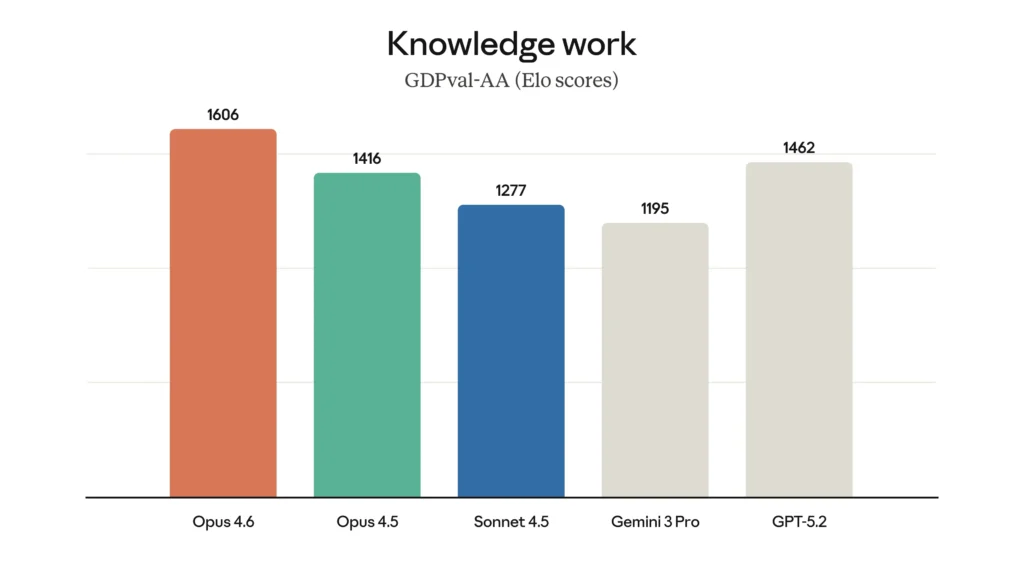
Performanca e modelit është më e mira në disa vlerësime. Për shembull, ai arrin rezultatin më të lartë në vlerësimin e kodimit agjentik Terminal-Bench 2.0 dhe kryeson të gjitha modelet e tjera të nivelit të lartë në Humanity’s Last Exam , një test kompleks arsyetimi shumëdisiplinor. Në GDPval-AA një vlerësim i performancës në detyrat e punës me njohuri me vlerë ekonomikisht në financë, juridike dhe fusha të tjera Opus 4.6 tejkalon modelin tjetër më të mirë të industrisë (GPT-5.2 i OpenAI) me rreth 144 pikë Elo, 2 dhe paraardhësin e tij (Claude Opus 4.5) me 190 pikë. Opus 4.6 gjithashtu performon më mirë se çdo model tjetër në BrowseComp, i cili mat aftësinë e një modeli për të gjetur informacione të vështira për t’u gjetur në internet.
Siç e tregojmë në kartën tonë të gjerë të sistemit, Opus 4.6 tregon gjithashtu një profil të përgjithshëm sigurie po aq të mirë ose më të mirë se çdo model tjetër i përparuar në industri, me shkallë të ulëta të sjelljes së gabuar në të gjitha vlerësimet e sigurisë.
Në Claude Code, tani mund të mblidhni ekipe agjentësh për të punuar së bashku në detyra. Në API, Claude mund të përdorë ngjeshjen për të përmbledhur kontekstin e vet dhe për të kryer detyra më afatgjata pa u përballur me kufizime. Po prezantojmë gjithashtu të menduarit adaptiv, ku modeli mund të kuptojë të dhëna kontekstuale se sa duhet të përdorë të menduarit e tij të zgjeruar, dhe kontrolle të reja përpjekjesh për t’u dhënë zhvilluesve më shumë kontroll mbi inteligjencën, shpejtësinë dhe koston.
Ne kemi bërë përmirësime të konsiderueshme në Claude in Excel dhe po e publikojmë Claude in PowerPoint në një pamje paraprake kërkimore. Kjo e bën Claude shumë më të aftë për punën e përditshme.
Claude Opus 4.6 është i disponueshëm sot në claude.ai , API-në tonë dhe në të gjitha platformat kryesore të cloud-it. Nëse jeni zhvillues, përdoreni claude-opus-4-6nëpërmjet Claude API-t. Çmimi mbetet i njëjtë në 5 dollarë/25 dollarë për milion token; për detaje të plota, shihni faqen tonë të çmimeve.
Ne e trajtojmë në detaje modelin, përditësimet e produkteve tona të reja, vlerësimet tona dhe testimet tona të gjera të sigurisë më poshtë.
Ne ndërtojmë Claude me Claude. Inxhinierët tanë shkruajnë kod me Claude Code çdo ditë dhe çdo model i ri testohet së pari në punën tonë. Me Opus 4.6, kemi zbuluar se modeli i kushton më shumë vëmendje pjesëve më sfiduese të një detyre pa na u thënë, lëviz shpejt nëpër pjesët më të thjeshta, trajton probleme të paqarta me gjykim më të mirë dhe mbetet produktiv gjatë seancave më të gjata.
Opus 4.6 shpesh mendon më thellë dhe e rishikon më me kujdes arsyetimin e tij përpara se të vendoset për një përgjigje. Kjo prodhon rezultate më të mira në problemet më të vështira, por mund të shtojë kosto dhe vonesë në ato më të thjeshta. Nëse po vini re se modeli po mendon shumë për një detyrë të caktuar, ne rekomandojmë uljen e përpjekjes nga cilësimi i tij i parazgjedhur (i lartë) në mesatar. Mund ta kontrolloni këtë lehtësisht me parametrin.
Ja disa nga gjërat që partnerët tanë të Qasjes së Hershme na treguan rreth Claude Opus 4.6, duke përfshirë prirjen e tij për të punuar në mënyrë autonome pa u mbështetur në dorë, suksesin e tij aty ku modelet e mëparshme dështuan dhe efektin e tij në mënyrën se si punojnë ekipet.
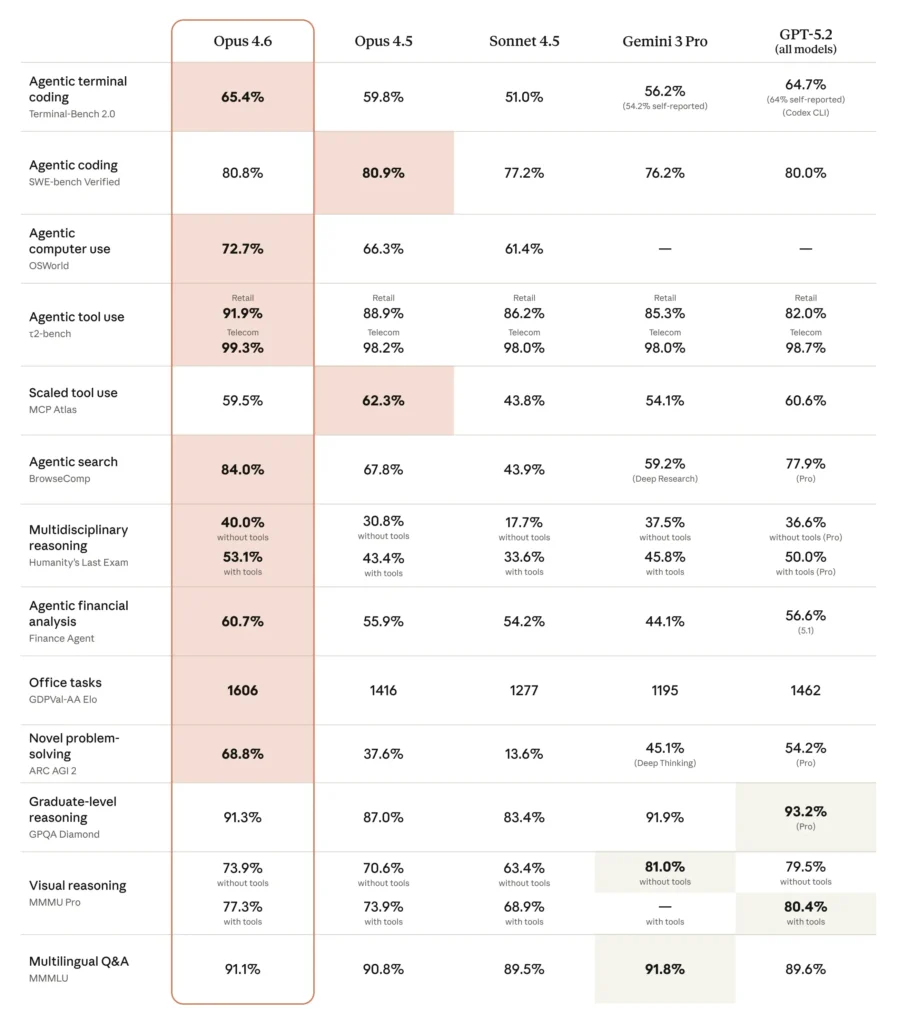
Në kodimin agjentik, përdorimin e kompjuterëve, përdorimin e mjeteve, kërkimin dhe financën, Opus 4.6 është një model lider në industri, shpesh me një diferencë të madhe. Tabela më poshtë tregon se si Claude Opus 4.6 krahasohet me modelet tona të mëparshme dhe me modelet e tjera të industrisë në një sërë standardesh.
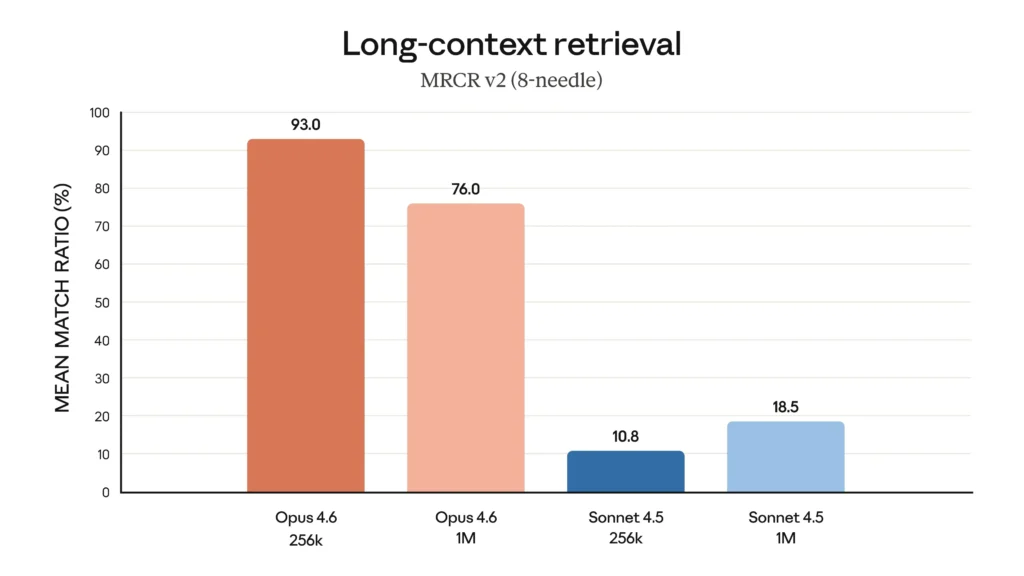
Opus 4.6 është shumë më i mirë në nxjerrjen e informacionit përkatës nga grupe të mëdha dokumentesh. Kjo shtrihet edhe në detyrat me kontekst të gjatë, ku ai mban dhe gjurmon informacionin mbi qindra mijëra tokena me më pak devijim, dhe mbledh detaje të fshehura që edhe Opus 4.5 do t’i humbiste.
Një ankesë e zakonshme në lidhje me modelet e inteligjencës artificiale është ” kalbja e kontekstit “, ku performanca përkeqësohet ndërsa bisedat tejkalojnë një numër të caktuar tokenësh. Opus 4.6 performon dukshëm më mirë se paraardhësit e tij: në variantin 8-gjilpërash 1M të MRCR v2 – një test krahasues gjilpërash në kashtë që teston aftësinë e një modeli për të rikuperuar informacionin “e fshehur” në sasi të mëdha teksti – Opus 4.6 shënon 76%, ndërsa Sonnet 4.5 shënon vetëm 18.5%. Ky është një ndryshim cilësor në atë se sa kontekst mund të përdorë në të vërtetë një model duke ruajtur performancën maksimale.
Në përgjithësi, Opus 4.6 është më i mirë në gjetjen e informacionit në kontekste të gjata, më i mirë në arsyetim pas përthithjes së atij informacioni dhe në përgjithësi ka aftësi arsyetimi dukshëm më të mira në nivel eksperti.
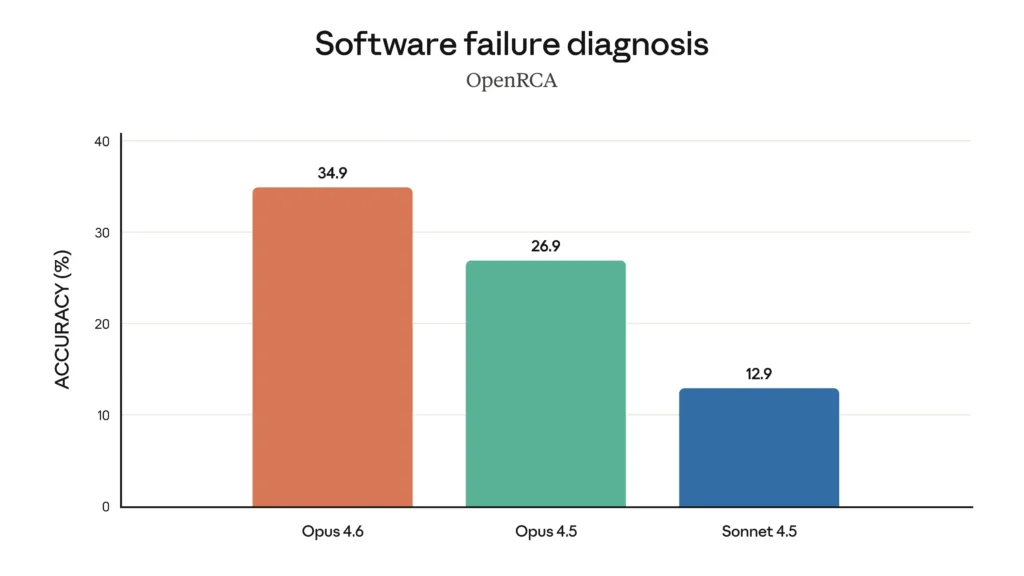
Së fundmi, grafikët më poshtë tregojnë se si Claude Opus 4.6 performon në një sërë kriteresh që vlerësojnë aftësitë e tij në inxhinierinë e softuerëve, aftësinë e kodimit shumëgjuhësh, koherencën afatgjatë, aftësitë e sigurisë kibernetike dhe njohuritë e tij në shkencat e jetës.
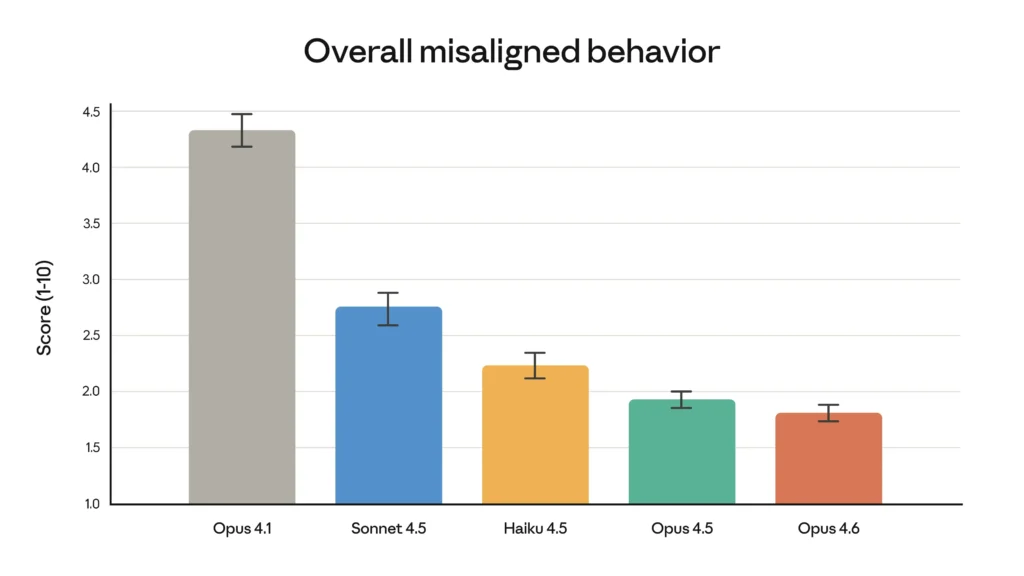
Këto përfitime në inteligjencë nuk vijnë me koston e sigurisë. Në auditimin tonë të automatizuar të sjelljes, Opus 4.6 tregoi një shkallë të ulët të sjelljeve të gabuara, të tilla si mashtrimi, servilizmi, inkurajimi i iluzioneve të përdoruesit dhe bashkëpunimi me keqpërdorimin. Në përgjithësi, është po aq i harmonizuar sa paraardhësi i tij, Claude Opus 4.5, i cili ishte modeli ynë më i harmonizuar deri më sot. Opus 4.6 gjithashtu tregon shkallën më të ulët të refuzimeve të tepërta – ku modeli nuk arrin t’u përgjigjet pyetjeve të mira – nga çdo model i kohëve të fundit Claude.
Për Claude Opus 4.6, ne ekzekutuam grupin më gjithëpërfshirës të vlerësimeve të sigurisë nga çdo model tjetër, duke aplikuar shumë teste të ndryshme për herë të parë dhe duke përmirësuar disa që kemi përdorur më parë. Ne përfshimë vlerësime të reja për mirëqenien e përdoruesit, teste më komplekse të aftësisë së modelit për të refuzuar kërkesa potencialisht të rrezikshme dhe vlerësime të përditësuara të aftësisë së modelit për të kryer fshehurazi veprime të dëmshme. Ne gjithashtu eksperimentuam me metoda të reja nga interpretabiliteti , shkenca e funksionimit të brendshëm të modeleve të IA-së, për të filluar të kuptojmë pse modeli sillet në mënyra të caktuara – dhe, në fund të fundit, për të kapur problemet që testimi standard mund të mos i dallojë.
Një përshkrim i detajuar i të gjitha vlerësimeve të aftësive dhe sigurisë është i disponueshëm në kartën e sistemit Claude Opus 4.6.
Gjithashtu, kemi aplikuar masa të reja mbrojtëse në fushat ku Opus 4.6 tregon pika të forta të veçanta që mund të përdoren si në mënyrë të rrezikshme ashtu edhe në mënyrë të dobishme. Në veçanti, meqenëse modeli tregon aftësi të përmirësuara të sigurisë kibernetike, kemi zhvilluar gjashtë sonda të reja të sigurisë kibernetike – metoda për zbulimin e përgjigjeve të dëmshme – për të na ndihmuar të gjurmojmë forma të ndryshme të keqpërdorimit të mundshëm.
Gjithashtu, po përshpejtojmë përdorimet e modelit në mbrojtje kibernetike, duke e përdorur atë për të ndihmuar në gjetjen dhe korrigjimin e dobësive në softuerët me burim të hapur (siç e përshkruajmë në postimin tonë të ri në blog për sigurinë kibernetike ). Mendojmë se është thelbësore që mbrojtësit kibernetikë të përdorin modele të inteligjencës artificiale si Claude për të ndihmuar në barazimin e kushteve të lojës. Siguria kibernetike ecën me shpejtësi dhe ne do të përshtatim dhe përditësojmë masat tona mbrojtëse ndërsa mësojmë më shumë rreth kërcënimeve të mundshme; në të ardhmen e afërt, mund të ndërmarrim ndërhyrje në kohë reale për të bllokuar abuzimin.
Ne kemi bërë përditësime të konsiderueshme në Claude, Claude Code dhe Claude Developer Platform për ta lejuar Opus 4.6 të performojë në mënyrën më të mirë.
Platforma e Zhvilluesve Claude
Në API, po u japim zhvilluesve kontroll më të mirë mbi përpjekjet e modelit dhe më shumë fleksibilitet për agjentët që funksionojnë për një kohë të gjatë. Për ta bërë këtë, po prezantojmë veçoritë e mëposhtme:
Të menduarit adaptiv. Më parë, zhvilluesit kishin vetëm një zgjedhje binare midis aktivizimit ose çaktivizimit të të menduarit të zgjeruar. Tani, me të menduarit adaptiv, Claude mund të vendosë se kur do të ishte i dobishëm arsyetimi më i thellë. Në nivelin e parazgjedhur të përpjekjes (i lartë), modeli përdor të menduarit e zgjeruar kur është i dobishëm, por zhvilluesit mund ta rregullojnë nivelin e përpjekjes për ta bërë atë pak a shumë selektiv.
Përpjekje. Tani ka katër nivele përpjekjesh për të zgjedhur: i ulët, mesatar, i lartë (parazgjedhur) dhe maksimal. Ne i inkurajojmë zhvilluesit të eksperimentojnë me opsione të ndryshme për të gjetur se çfarë funksionon më mirë.
Kompaktimi i kontekstit (beta). Bisedat dhe detyrat agjentike që zhvillohen gjatë shpesh shfaqen në dritaren e kontekstit. Kompaktimi i kontekstit përmbledh automatikisht dhe zëvendëson kontekstin më të vjetër kur biseda i afrohet një pragu të konfigurueshëm, duke i lejuar Claude të kryejë detyra më të gjata pa arritur kufijtë.
Konteksti i tokenëve 1M (beta). Opus 4.6 është modeli ynë i parë i klasit Opus me kontekst tokenësh 1M. Çmimi premium zbatohet për kërkesat që tejkalojnë 200 mijë tokena (10 dollarë/37.50 dollarë për milion tokena hyrës/dalës).
128 mijë tokenë dalës. Opus 4.6 mbështet dalje deri në 128 mijë tokenë, gjë që i lejon Claude të kryejë detyra me rezultate më të mëdha pa i ndarë ato në kërkesa të shumëfishta.
Përfundimi vetëm për SHBA-në. Për ngarkesat e punës që duhet të ekzekutohen në Shtetet e Bashkuara, përfundimi vetëm për SHBA-në është i disponueshëm me çmimin e tokenit 1.1×.
Përditësimet e produkteve
Në të gjithë Claude dhe Claude Code, ne kemi shtuar veçori që u lejojnë punonjësve të njohurive dhe zhvilluesve të përballen me detyra më të vështira me më shumë mjete që përdorin çdo ditë.
Ne kemi prezantuar ekipet e agjentëve në Claude Code si një pamje paraprake kërkimore. Tani mund të krijoni agjentë të shumtë që punojnë paralelisht si një ekip dhe të koordinohen në mënyrë autonome – më së miri për detyrat që ndahen në punë të pavarura dhe që kërkojnë shumë lexim, si rishikimet e bazës së kodit. Mund të merrni përsipër çdo nën-agjent direkt duke përdorur Shift+Lart/Poshtë ose tmux .
Claude tani funksionon më mirë edhe me mjetet e zyrës që përdorni tashmë. Claude në Excel trajton detyra afatgjata dhe më të vështira me performancë të përmirësuar dhe mund të planifikojë para se të veprojë, të përthithë të dhëna të pastrukturuara dhe të nxjerrë strukturën e duhur pa udhëzime, si dhe të trajtojë ndryshime me shumë hapa me një kalim të vetëm. Kombinojeni këtë me Claude në PowerPoint dhe së pari mund të përpunoni dhe strukturoni të dhënat tuaja në Excel, pastaj t’i sillni në jetë vizualisht në PowerPoint. Claude lexon paraqitjet, fontet dhe modelet kryesore të diapozitivave për të qëndruar në markë, pavarësisht nëse po ndërtoni nga një shabllon ose po gjeneroni një paketë të plotë nga një përshkrim. Claude në PowerPoint tani është i disponueshëm në pamjen paraprake të kërkimit për planet Max, Team dhe Enterprise.