Perplexity lançon agjentin AI “Computer” që koordinon 19 modele, me çmim 200 dollarë në muaj

Perplexity, kompania e kërkimit e mundësuar nga inteligjenca artificiale me vlerë 20 miliardë dollarë, të mërkurën lançoi atë që e quan produktin më ambicioz në historinë e saj trevjeçare: një platformë orkestrimi agjentësh me shumë modele të quajtur Computer që koordinon 19 modele të ndryshme të inteligjencës artificiale për të përfunduar rrjedha pune komplekse dhe afatgjata tërësisht në sfond.
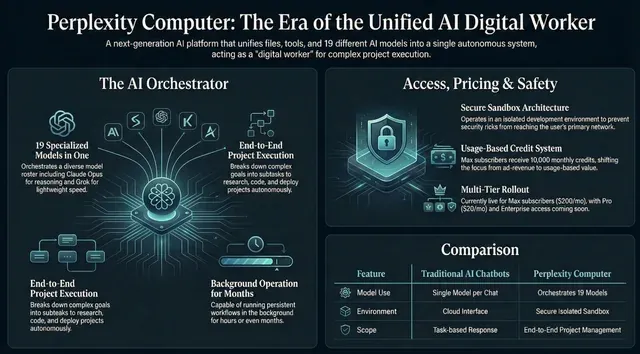
Produkti, aktualisht i disponueshëm vetëm për abonentët e Perplexity Max me 200 dollarë në muaj, është artikulimi më i qartë i kompanisë deri më tani i një teze që e ka rafinuar për më shumë se një vit: që modelet e IA-së nuk po konvergojnë në mallra me qëllim të përgjithshëm, por përkundrazi po specializohen – dhe se kompania në pozicionin më të mirë për të fituar epokën e ardhshme të IA-së është ajo që mund t’i orkestrojë të gjitha së bashku.

“Me çfarë është marrë Perplexity dy muajt e fundit? Ne kemi punuar në heshtje për gjënë e madhe të radhës,” shkroi CEO Aravind Srinivas në X, duke njoftuar se “Kompjuteri unifikon çdo aftësi aktuale të IA-së në një sistem të vetëm.” Srinivas tha se sistemi i trajton modelet si mjete të këmbyeshme dhe jo si produkte thelbësore. “Është shumë-modelë nga dizajni,” shkroi ai. “Kur modelet specializohen, ato thjesht bëhen mjete të ngjashme me sistemin e skedarëve, mjetet CLI, lidhësit, shfletuesin, kërkimin.”
Kompjuteri arrin në një moment kur industria e IA-së po përballet me një pyetje themelore: tani që modelet themelore janë bërë jashtëzakonisht të afta, kush e kap vlerën? Krijuesit e modeleve – OpenAI, Anthropic, Google – apo kompanitë që qëndrojnë sipër tyre dhe e shndërrojnë inteligjencën e papërpunuar në produkte të besueshme dhe të sakta?
Perplexity po vë një bast prej 20 miliardë dollarësh për këtë të fundit.
Në thelbin e tij, Kompjuteri funksionon si ajo që Perplexity e përshkruan si “një punëtor dixhital me qëllim të përgjithshëm” – një sistem që mund të pranojë një objektiv të nivelit të lartë nga një përdorues, ta dekompozojë atë në nëndetyra dhe t’ia delegojë këto nëndetyra cilitdo modeli të IA-së që është më i përshtatshmi për secilin prej tyre. The Verge e përshkroi atë si ekzistues “diku midis OpenClaw dhe Claude Cowork “, duke iu referuar përkatësisht agjentit autonom viral me burim të hapur dhe mjetit të bashkëpunimit të ndërmarrjeve të Anthropic.
Motori qendror i arsyetimit të platformës funksionon në Claude Opus 4.6 të Anthropic , i cili merret me logjikën e orkestrimit dhe detyrat e kodimit. Gemini i Google fuqizon pyetjet e thella kërkimore. Nano Banana e Google gjeneron imazhe dhe Veo 3.1 merret me videon. Grok i xAI është vendosur për detyra të lehta dhe të ndjeshme ndaj shpejtësisë. GPT-5.2 i OpenAI menaxhon kujtesën në kontekst të gjatë dhe kërkimin e gjerë në internet. Në total, sistemi koordinon 19 modele në backend, sipas kompanisë.
Ky listë modelesh nuk është fikse. Perplexity thotë se modele të reja mund të shtohen ndërsa ato demonstrojnë forcë në fusha specifike, dhe formacioni ekzistues do të ndryshojë ndërsa modelet evoluojnë. Përdoruesit gjithashtu mund të hyjnë vetë në rolin e orkestruesit, duke u caktuar manualisht nëndetyra modeleve të veçanta nëse preferojnë.
Ajo që e dallon Computer nga mjetet ekzistuese të agjentëve është kombinimi i fushëveprimit dhe aksesueshmërisë. Një përdorues mund të përshkruajë një rezultat të dëshiruar – të themi, “Planifikoni një udhëtim njëjavor në Japoni, gjeni fluturime nën 1,200 dollarë dhe ndërtoni një itinerar të plotë me rezervime në restorante” – dhe Computer do ta ndajë në mënyrë autonome atë projekt në komponentë, do t’ia caktojë secilin modelit të duhur dhe do të punojë mbi të në sfond. Perplexity thotë se sistemi mund të funksionojë në heshtje për periudha të gjata, duke kontaktuar përdoruesin vetëm kur ka nevojë vërtet për të dhëna.
Themeli intelektual i Kompjuterit mbështetet në të dhënat që Perplexity ka mbledhur në të gjithë bazën e klientëve të ndërmarrjeve të saj – të dhëna që, sipas kompanisë, asnjë kompani tjetër e IA-së nuk ka qasje në të njëjtën shkallë.
Në një konferencë shtypi të kohëve të fundit në të cilën VentureBeat mori pjesë së bashku me gazetarë të tjerë në San Francisko, drejtuesit e Perplexity ndanë statistikat e përdorimit të ndërmarrjeve që ilustronin një ndryshim dramatik në mënyrën se si bizneset përdorin modelet e inteligjencës artificiale. Në janar 2025, më shumë se 90 përqind e detyrave të ndërmarrjeve në platformën Perplexity ishin të shpërndara në vetëm dy modele. Deri në dhjetor 2025, asnjë model i vetëm nuk zotëronte më shumë se 25 përqind të përdorimit në të gjitha bizneset dhe llojet e detyrave.
Ky ndryshim, thanë drejtuesit, u nxit pjesërisht nga drejtimi gjithnjë e më inteligjent i modeleve në anën e Perplexity, dhe pjesërisht nga një realitet i thjeshtë: modelet po përmirësohen në gjëra të ndryshme, jo në të njëjtat gjëra. Një model i ri kufitar u shfaq mesatarisht çdo 17.5 ditë në vitin 2025, dhe secili prej tyre solli pika të forta të dallueshme në vend të përmirësimit uniform.
Për shembull, Claude është shfaqur si modeli i zgjedhur për detyrat e inxhinierisë së softuerëve – një reputacion aq i fortë saqë edhe OpenClaw, agjenti autonom viral i krijuar nga programuesi austriak Peter Steinberger (i cili më pas u punësua nga OpenAI), fillimisht u ndërtua mbi aftësitë e kodimit të Claude. Por pikat e forta të Claude në kodim nuk përkthehen në shkrim ose gjenerim krijues, ku Gemini tenton të tejkalojë performancën. Dhe në rikthimin në kontekst të gjatë dhe kërkimin e gjerë në internet, GPT-5.2 ka përparësi.
“Ajo që kemi mësuar gjatë kësaj kohe është se ata nuk po e bëjnë komoditet. Ata po specializohen”, tha një drejtues i lartë i Perplexity në konferencën informuese, duke e karakterizuar Claude Opus 4.6 si “një shkrimtar të tmerrshëm”, ndërsa vuri në dukje aftësitë e tij në kodim dhe duke shtuar: “Të gjithë kanë siguri pune në këtë drejtim”.
Kjo dinamikë specializimi krijon atë që Perplexity e sheh si një avantazh strukturor. Një ekip marketingu që përdor Claude, argumentuan drejtuesit, në përgjithësi do të japë rezultate më të këqija se një ekip që përdor Gemini. Një ekip inxhinierik që përdor Gemini do të performojë më dobët se një ekip që përdor Claude. Asnjë kompani nuk operon vetëm me një lloj ekipi – dhe asnjë model i vetëm nuk mund t’i shërbejë të gjithëve po aq mirë.
Lançimi i kompjuterit vjen menjëherë pas OpenClaw, agjentit autonom me burim të hapur që u bë viral në fillim të këtij muaji dhe e shtyu OpenAI të punësonte krijuesin e tij. OpenClaw kapi imagjinatën e komunitetit të IA-së duke demonstruar se çfarë mund të arrinte një agjent plotësisht autonom kur i jepej akses i gjerë në të gjithë ekosistemin dixhital të një përdoruesi – skedarë, email, aplikacione mesazhesh, çelësa API dhe më shumë.
Por kjo demonstroi edhe rreziqet. Në një incident të shpërndarë gjerësisht këtë javë, studiuesja e sigurisë së Meta AI, Summer Yue, postoi pamje të ekranit në X të përpjekjeve të saj frenetike për të ndaluar OpenClaw që të fshinte të gjithë kutinë e saj të email-eve — një proces që agjentja e kishte nisur dhe që po refuzonte ta ndalonte. “Më duhej të IKJA drejt Mac Mini-t tim sikur po shpërndaja një bombë”, shkroi Yue.
Perplexity ka qenë i zëshëm rreth arsyes pse Computer funksionon tërësisht në cloud në vend që të ketë qasje në makinën lokale të përdoruesit – një qasje e ndjekur nga rivalë si Claude i Anthropic dhe Operator i OpenAI.
Kompania argumenton se qasja lokale krijon rrezik të panevojshëm, duke e krahasuar atë me programet keqdashëse në lehtësinë me të cilën mund të dëmtojë të dhënat ose të ekspozojë informacione të ndjeshme. Në vend të kësaj, kompjuteri vepron brenda asaj që Perplexity e përshkruan si një sandbox zhvillimi të sigurt, që do të thotë se dështimet e sigurisë janë të përmbajtura dhe nuk mund të përhapen në rrjetin ose pajisjen kryesore të përdoruesit. Kompania tha gjithashtu se ka kryer mijëra detyra brenda kompanisë duke përdorur kompjuterin, nga publikimi i tekstit në internet deri te ndërtimi i aplikacioneve.
Dallimi shtrihet edhe te aksesueshmëria. Aty ku OpenClaw kërkon akses në terminal, konfigurim të çelësit API dhe një makinë të dedikuar (zakonisht një Mac mini), Kompjuteri është projektuar për t’u thirrur nga një telefon, një mesazh Slack ose aplikacioni Perplexity.
Në konferencën për shtyp, drejtuesit shpjeguan më hollësisht filozofinë, duke i pozicionuar aftësitë e agjentëve të shfletuesit të Computer – të ndërtuara mbi teknologjinë e shfletuesit Comet të Perplexity – si qendrore të produktit. Një drejtues vuri në dukje se shifrat e përdorimit të agjentëve të shfletuesit të Perplexity janë tre deri në pesë herë më të larta se shifrat e agjentëve të ChatGPT të publikuara nga The Information në janar, pavarësisht bazës shumë më të vogël të përdoruesve të Perplexity.
Ambiciet e produkteve të Perplexity mbështeten nga një biznes që, sipas metrikave të vetë kompanisë, po rritet më shpejt se baza e përdoruesve të tij – dhe drejtuesit thonë se kompania mezi ka filluar të përqendrohet në monetizimin.
Në konferencën për shtyp, drejtuesit zbuluan se Perplexity rriti përdoruesit me 3.7 herë në vitin 2025 dhe të ardhurat me 4.7 herë, që do të thotë se kompania po nxjerr më shumë vlerë nga përdoruesit e saj ekzistues me kalimin e kohës. Abonimet e konsumatorëve mbeten komponenti më i madh i të ardhurave, por biznesi i ndërmarrjeve po rritet me atë që drejtuesit e pranuan si një operacion jashtëzakonisht të dobët.
“Ne kemi vetëm pesë persona në ekipin tonë të shitjeve të ndërmarrjeve”, tha një drejtues ekzekutiv, përpara se të shtonte se të ardhurat e kompanisë për punonjës që punon në marrëveshje mund të jenë të pakrahasueshme në industri. Një tjetër drejtues ekzekutiv vuri në dukje se 92 përqind e Fortune 500 kanë përdorim të Perplexity – megjithëse kjo shifër përfshin punonjësit që regjistrohen me llogari personale dhe adresa email-i pune për versionin e konsumatorit, jo domosdoshmërisht kontrata formale të ndërmarrjeve.
Një bisedë e zakonshme shitjesh në ndërmarrje, thanë drejtuesit, fillon me: “A e dinit se tashmë 3,000 punonjës tuaj përdorin Perplexity, dhe ata po përdorin versionin për konsumatorin që nuk i përmbahet të gjitha politikave tuaja të sigurisë?”
Veçanërisht, Perplexity nuk po synon të fitojë të ardhura nga reklamat, edhe pse konkurrentë si OpenAI po lëvizin drejt modeleve të mbështetura nga reklamat. Ekzekutivët thanë se reklamat janë në thelb të papajtueshme me misionin e saktësisë së kompanisë. “Sfida me reklamat është, e dini, se një përdorues thjesht do të fillojë të dyshojë në gjithçka”, tha një ekzekutiv. Kompania konfirmoi se nuk ka marrë parasysh asnjë aspekt ekonomik në integrimet e saj të blerjeve dhe shprehu dyshime se çdo monetizim i bazuar në blerje do të materializohej këtë vit.
Lidhur me çështjen e një IPO-je, Srinivas tregoi se kompania ka “karakteristika shumë të mira që mund të bëhen publike” duke pasur parasysh shpenzimet e ulëta kapitale dhe marzhet e shëndetshme, por nuk u zotua për një afat kohor. Një tjetër drejtues paralajmëroi se “shumë biseda për IPO-në janë entuziazëm” dhe se “nëse premton më shumë dhe nuk i përmbush premtimet, tregu të godet rëndë”.
TestingCatalog raportoi gjithashtu këtë javë se një zonë e re cilësimesh ” Përdorimi dhe Kreditet ” është shfaqur në versionet e zhvillimit të Perplexity, e cila do t’u lejonte përdoruesve të blinin kredite shtesë për të zgjatur përdorimin – duke lehtësuar potencialisht reagimin nga abonentët të cilët panë kufizimet e tyre të pyetjeve të Deep Research të ulura nga afërsisht 500 në ditë në vetëm 20 në muaj midis fundit të vitit 2025 dhe fillimit të vitit 2026.
Ndoshta elementi më pak i diskutuar, por më i rëndësishëm strategjikisht i historisë së Perplexity është biznesi i saj i API-ve të kërkimit – një lojë infrastrukturore që e pozicionon kompaninë jo vetëm si një produkt për konsumatorin, por si një shtresë themelore për ekosistemin më të gjerë të IA-së.
Në konferencën për shtyp, drejtuesit zbuluan se Perplexity lançoi API-në e saj të kërkimit afërsisht katër muaj më parë dhe tashmë katër nga “Mag Seven” – shtatë kompanitë më të mëdha të teknologjisë sipas kapitalizimit të tregut – e përdorin atë në prodhim në shkallë të konsiderueshme. “Ju që mbuloni Mag Seven, e dini që ata nuk aktivizojnë një veçori në prodhim nëse nuk kanë kryer vlerësime rigoroze dhe nuk e kanë krahasuar atë”, u tha një drejtues gazetarëve.
Ky zbulim sugjeron që kompanitë më të mëdha të teknologjisë në botë kanë vlerësuar indeksin e kërkimit të Perplexity kundrejt alternativave dhe kanë arritur në përfundimin se është më i optimizuar për rastet e përdorimit të bazuara në inteligjencën artificiale – një objektiv optimizimi thelbësisht i ndryshëm nga indeksi tradicional i Google, i cili ishte projektuar për njerëzit që skanojnë listat e lidhjeve.
“Çdo gjë në indeksin tonë është e optimizuar, jo që një njeri të shohë 10 lidhje blu,” shpjegoi një drejtues. “Është për një inteligjencë artificiale që të jetë në gjendje të marrë ato fragmente dhe t’i konsumojë ato në këtë dritare konteksti dhe pastaj të arsyetojë përmes tyre.”
Kompania konfirmoi gjithashtu se ka infrastrukturë kërkimi plotësisht të pavarur, duke mos u mbështetur më në API të palëve të treta nga Google ose Bing për indeksin e saj – një ndryshim i rëndësishëm nga vitet e mëparshme.
Për modelet kineze me burim të hapur, të cilat Perplexity i përdor në orkestrimin e saj, kompania i ekzekuton të gjitha konkluzionet nga qendrat e saj të të dhënave në SHBA, duke i trajnuar modelet për saktësi pas trajnimit, duke hequr atë që drejtuesit e përshkruan si “propagandë e mbushur me shtet” dhe duke ndërtuar bërthama konkluzionesh të personalizuara. Kompania e bëri metodologjinë e saj me burim të hapur për çpropagandimin e modeleve kineze që t’i përdorin edhe të tjerët.
API- ja e kërkimit krijon një rrotë të fuqishme të dhënash, argumentuan drejtuesit: Perplexity mund të vëzhgojë se cilat fragmente shfaqen renditësi i kërkimit për një pyetje të caktuar, pastaj të gjurmojë se cilat nga ato fragmente përdor në të vërtetë LLM në rezultatin e saj përfundimtar. Ky lak reagimi e bën pyetjen tjetër mbi një temë të ngjashme më të zgjuar – një avantazh që bizneset e kërkimit të pastër API si Exa nuk mund ta kopjojnë sepse u mungon produkti i konsumatorit që gjeneron pyetje dhe reagime nga përdoruesit.
Ambiciet e Perplexity nuk janë pa ndërlikime. Kompania përballet me padi aktive nga botues të shumtë dhe peizazhi ligjor u bë më i diskutueshëm këtë javë.
Siç raportoi Melia Russell e Business Insider, Perplexity ngriti një mocion më 24 shkurt në betejën e saj ligjore të vazhdueshme me Dow Jones (botuesin e The Wall Street Journal) dhe New York Post, duke pretenduar se botuesit “zgjodhën me kujdes” përgjigjet nga motori i kërkimit i Perplexity për të mbështetur pretendimet e tyre për të drejtat e autorit. Kompania tha se identifikoi qindra kërkesa që botuesit paraqitën të cilat “ishin përpjekje të qarta për të nxitur përgjigje që shkelin të drejtat e autorit”, duke përfshirë një rast ku një përdorues dyshohet se ka shtypur butonin “riprovo” më shumë se 50 herë.
Në konferencën për shtyp, drejtuesit e Perplexity e paraqitën debatin më të gjerë për të drejtat e autorit në terma historikë, duke vënë në dukje se valë padish kanë shoqëruar çdo ndryshim të madh teknologjik që nga radioja. Ata shprehën besim se kompanitë e inteligjencës artificiale në fund të fundit do të triumfojnë, veçanërisht në çështjen nëse njohuria themelore – ndryshe nga shprehja unike krijuese – mund të aksesohet lirisht nga sistemet e inteligjencës artificiale. “Vendet kanë ligje për të drejtat e autorit për një arsye: për të promovuar inovacionin”, tha një drejtues, duke vënë në dukje se ligji mbron shprehjen unike duke e mbajtur të hapur njohurinë themelore.
Në lidhje me agjentët e përdoruesve konkretisht, drejtuesit argumentuan se agjenti i inteligjencës artificiale i një përdoruesi është ligjërisht dhe teknologjikisht një zgjatim i përdoruesit, jo një aktor i pavarur. Në padinë kundër Amazon , e cila sfidon aftësinë e Perplexity për të vepruar si një agjent blerjesh në emër të përdoruesve, një drejtues ofroi një analogji të theksuar: “Ajo që pretendon Amazon është se nuk duhet të jeni në gjendje të punësoni blerësin tuaj personal. Ai duhet të punësohet prej tyre. Ata duan që ju të përdorni Rufusin.”
Ekzekutivët sqaruan gjithashtu qasjen e kompanisë ndaj citimeve, duke vënë në dukje se citimi i një burimi si The New York Times ( e cila aktualisht po padit kompaninë ) nuk do të thotë domosdoshmërisht që Perplexity e ka gjetur atë botim direkt. “Ne mund ta marrim përmbledhjen e kësaj diku tjetër, por ne citojmë, gjithmonë përpiqemi ta citojmë atë burim origjinal”, tha një ekzekutiv. “Pra, drejtojeni atë trafik te New York Times nëse dikush klikon në vend që ta drejtoni atë te një përmbledhje.”
Lançimi i kompjuterit kristalizon një tension që është krijuar në industrinë e inteligjencës artificiale prej muajsh. Prodhuesit kryesorë të modeleve – OpenAI, Anthropic, Google – kanë qenë në garë për të ndërtuar produkte gjithëpërfshirëse që i mbajnë përdoruesit brenda ekosistemeve të tyre. Codex dhe ChatGPT të OpenAI, Claude Code dhe Cowork të Anthropic, Gemini i Google – të gjithë supozojnë se një familje modelesh mund të përballojë gamën e plotë të nevojave të përdoruesve.
Hutimi po bën bastin e kundërt: që e ardhmja i përket shtresës së orkestrimit, jo shtresës së modelit. Është një bast me paralele historike. Në ditët e para të cloud computing, kompanitë që ndërtuan shtresat më të mira të abstraksionit mbi infrastrukturën e mallrave – jo vetë ofruesit e infrastrukturës – shpesh kapën vlerë të jashtëzakonshme. Hutimi po pozicionohet si ajo shtresë abstraksioni për IA-në.
Rreziku, sigurisht, është që krijuesit e modeleve mund të kufizojnë aksesin në API ose të degradojnë shërbimin për konkurrentët e platformës. Srinivas ka thënë se nuk është i shqetësuar, duke vënë në dukje se ka marrë urime nga Anthropic dhe Google pas lançimit të Computer dhe se krijuesit e modeleve përfitojnë kur sistemet e tyre janë pjesë e rrjedhave më të gjera të punës. Por historia e industrisë së inteligjencës artificiale në dinamikën e platformave sugjeron se kjo ulje e tensioneve mund të mos zgjasë përgjithmonë.
Për liderët e teknologjisë së ndërmarrjeve që vlerësojnë strategjitë e tyre të inteligjencës artificiale, Computer ngre një pyetje praktike: a duhet që organizatat të standardizohen në një ekosistem ofruesi të vetëm modeli, duke pranuar kufizimet e tij në këmbim të thjeshtësisë? Apo duhet të investojnë në orkestrimin me shumë modele, duke fituar akses në aftësitë më të mira të të gjithë ofruesve me koston e kompleksitetit shtesë?
Hutimi është se, ndërsa modelet vazhdojnë të specializohen dhe hendeku midis pikave të tyre të forta përkatëse zgjerohet, përgjigjja do të bëhet e qartë. Të dhënat e përdorimit të ndërmarrjeve të kompanisë – që tregojnë një treg që kaloi nga dominimi i dy modeleve në dominimin e asnjë modeli në vetëm 12 muaj – sugjerojnë se ndryshimi është tashmë në proces.
Kompjuteri është aktualisht i disponueshëm për abonentët e Perplexity Max, me një lançim për përdoruesit Pro dhe Enterprise të planifikuar në javët në vijim. Kompania ka njoftuar gjithashtu një ngjarje për zhvilluesit më 11 mars, ku planifikon të ndajë më shumë detaje rreth API-t të saj të kërkimit, integrimeve të renditjes dhe infrastrukturës që fuqizon grupin e saj të orkestrimit.