Blackwell i Nvidia mund të trajnojë GPT-4 në 10 ditë, por a i zgjidh kjo problemet e modeleve aktuale?
Prezantimi i Nvidia Computex 2024 në Tajvan dha një pamje të udhërrëfyesit të GPU-së dhe ndërlidhjes deri në vitin 2027. Në fjalimin e tij kryesor, CEO Jensen Huang theksoi nevojën për të rritur vazhdimisht performancën duke reduktuar kostot e trajnimit dhe konkluzioneve në mënyrë që çdo kompani të mund të përdorë AI.
Huang krahasoi zhvillimin e performancës së GPU-së gjatë tetë viteve: midis gjeneratave të GPU “Pascal” P100 dhe “Blackwell” B100, që do të dorëzohen këtë vit, performanca u rrit me më shumë se 1000 herë. Pjesa më e madhe e kësaj është për shkak të zvogëlimit të saktësisë së pikës lundruese. Nvidia mbështetet shumë në FP4 për Blackwell.
Kjo rritje e performancës duhet të bëjë të mundur trajnimin e një modeli si GPT-4 me 1.8 trilion parametra në 10,000 GPU B100 në vetëm dhjetë ditë, sipas Huang.
Megjithatë, çmimet GPU janë rritur gjithashtu me një faktor prej 7.5 gjatë tetë viteve të fundit. Një B100 pritet të kushtojë midis 35,000 dhe 40,000 dollarë. Megjithatë, rritja e performancës tejkalon shumë rritjen e çmimit.
Superkompjuterët e planifikuar me harduerin e ri krijojnë bazën për shkallëzimin e mëtejshëm të modeleve të AI. Ky shkallëzim jo vetëm që përfshin rritjen e numrit të parametrave, por edhe trajnimin e modeleve të AI me dukshëm më shumë të dhëna. Veçanërisht grupet e të dhënave multimodale që kombinojnë lloje të ndryshme informacioni si teksti, imazhet, video dhe audio do të përcaktojnë të ardhmen e modeleve të mëdha të AI në vitet e ardhshme. OpenAI prezantoi kohët e fundit GPT-4o, përsëritja e parë e një modeli të tillë.
Përveç kësaj, fuqia e rritur llogaritëse mundëson përsëritje më të shpejta gjatë testimit të parametrave të ndryshëm të modelit. Kështu, kompanitë dhe institucionet kërkimore mund të përcaktojnë në mënyrë më efikase konfigurimin optimal për rastet e përdorimit të tyre përpara se të fillojnë një trajnim përfundimtar veçanërisht intensiv me llogaritje.
Përshpejtimi ndikon gjithashtu në konkluzionet: aplikacionet në kohë reale si demonstrimet e gjuhës GPT-4o të OpenAI bëhen të mundshme.
Konkurrentët si xAI i Elon Musk gjithashtu do të trajnojnë modele të tilla. Kohët e fundit ai njoftoi se startup-i i tij i inteligjencës artificiale xAI planifikon të vërë në funksion një qendër të dhënash me 300,000 GPU Nvidia Blackwell B200 deri në verën e vitit 2025. Përveç kësaj, një sistem me 100,000 GPU H100 do të hyjë në internet brenda disa muajsh . Është e paqartë nëse kompania e tij mund t’i zbatojë këto plane. Shpenzimet ka të ngjarë të jenë mbi 10 miliardë dollarë. Kjo është ende shumë nën 100 miliardë që OpenAI dhe Microsoft raportohet se po vlerësojnë për Projektin Stargate.
Megjithatë, është e paqartë nëse shkallëzimi mund të ndihmojë gjithashtu në zgjidhjen e problemeve themelore të sistemeve të sotme të AI. Këto përfshijnë, për shembull, halucinacione të padëshiruara ku modelet gjuhësore gjenerojnë përgjigje bindëse, por faktikisht të pasakta.
Disa studiues, duke përfshirë autorët e ” Hipotezës së Përfaqësimit Platonik “, dyshojnë se përdorimi i sasive të mëdha të të dhënave të trajnimit multimodal mund të ndihmojë këtu. Shefi i AI i Metës, Yann LeCun dhe Gary Marcus, nga ana tjetër, i konsiderojnë halucinacione të tilla dhe mungesën e të kuptuarit të botës si një dobësi themelore të AI gjeneruese që nuk mund të korrigjohet.
Me harduerin e disponueshëm së shpejti, këtyre pyetjeve mund t’u jepet përgjigje eksperimentale – modelet e besueshme do të ishin në interes të kompanive, pasi ato do të mundësonin përdorimin në shumë fusha kritike të aplikimit.
Një rrugë e mundshme mund të jenë modelet e AI që kuptojnë më shumë rreth botës fizike: “Gjenerata e ardhshme e AI duhet të bazohet fizikisht, shumica e AI-së së sotme nuk i kuptojnë ligjet e fizikës, nuk është e bazuar në botën fizike”, tha Huang. në prezantimin e tij.
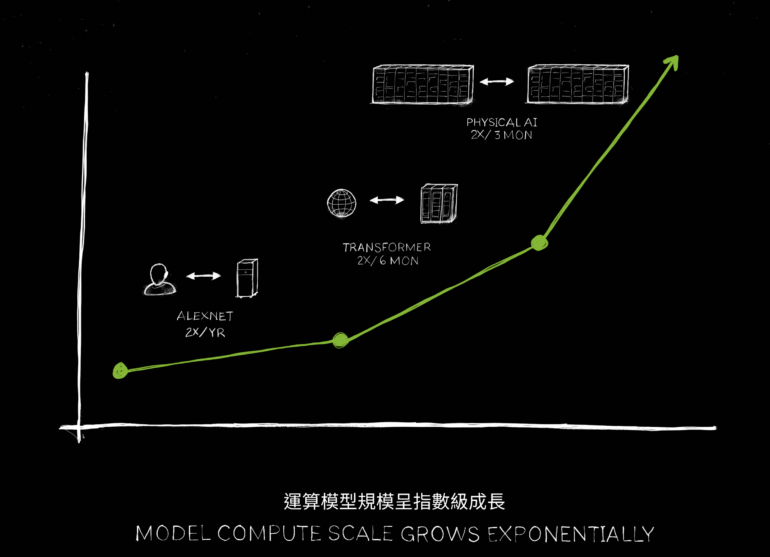
Ai pret që modele të tilla jo vetëm të mësojnë nga videot si Sora e OpenAI-t, por edhe të mësojnë në simulime dhe nga njëri-tjetri – të ngjashme me sistemet si AlphaGo e DeepMind. “Është e arsyeshme që shkalla e gjenerimit të të dhënave do të vazhdojë të përparojë dhe çdo herë që gjenerimi i të dhënave rritet sasia e llogaritjes që duhet të ofrojmë duhet të rritet me të. Ne duhet të hyjmë në një fazë ku AI-të mund të mësojnë ligjet e fizikën dhe kuptojnë dhe bazohen në të dhënat e botës fizike, dhe kështu ne presim që modelet të vazhdojnë të rriten, dhe ne kemi nevojë gjithashtu për GPU më të mëdha.”
Kjo rritje e fuqisë së kërkuar informatike është sigurisht në interesin e kompanisë – dhe Nvidia njoftoi gjithashtu detaje për gjeneratat e ardhshme të GPU: “Blackwell Ultra” (B200) do të pasojë në 2025, “Rubin” (R100) në 2026 dhe “Rubin”. Ultra” në 2027. Kësaj i shtohen përmirësimet në ndërlidhjet shoqëruese dhe ndërprerësit e rrjetit. “Vera”, një pasardhëse e CPU “Grace” Arm CPU e Nvidia, është planifikuar gjithashtu për vitin 2026.

Me Blackwell Ultra, Rubin dhe Rubin Ultra, Nvidia dëshiron të zgjerojë më tej dominimin e saj në tregun e harduerit për aplikacionet e AI përmes përditësimeve vjetore. Kompania tashmë ka arritur një pozicion pothuajse monopol këtu me çipat Hopper. AMD dhe Intel po përpiqen të shkundin këtë dominim me përshpejtuesit e tyre të AI.