Google pretendon se teknologjia e re e trajnimit të AI është 13 herë më e shpejtë dhe 10 herë më efikase në energji JEST i ri i DeepMind optimizon të dhënat e trajnimit për përfitime mbresëlënëse

Google DeepMind, laboratori kërkimor i AI i Google, ka publikuar një kërkim të ri mbi modelet e trajnimit të AI që pretendon se përshpejton shumë shpejtësinë e stërvitjes dhe efikasitetin e energjisë me një renditje të madhësisë, duke dhënë 13 herë më shumë performancë dhe dhjetë herë më shumë efikasitet të energjisë sesa metodat e tjera. Metoda e re e trajnimit JEST vjen në kohën e duhur ndërsa bisedat rreth ndikimit mjedisor të qendrave të dhënave të AI po nxehen.

Metoda e DeepMind, e quajtur JEST ose përzgjedhje e përbashkët e shembullit, shkëputet nga teknikat tradicionale të trajnimit të modelit të AI në një mënyrë të thjeshtë. Metodat tipike të trajnimit fokusohen në pikat individuale të të dhënave për trajnim dhe mësim, ndërsa JEST stërvitet bazuar në grupe të tëra. Metoda JEST krijon fillimisht një model më të vogël të AI që do të vlerësojë cilësinë e të dhënave nga burime jashtëzakonisht me cilësi të lartë, duke renditur grupet sipas cilësisë. Pastaj e krahason atë klasifikim me një grup më të madh dhe me cilësi më të ulët. Modeli i vogël JEST përcakton grupet më të përshtatshme për trajnim, dhe një model i madh më pas trajnohet nga gjetjet e modelit më të vogël.
Vetë punimi, i disponueshëm këtu, ofron një shpjegim më të plotë të proceseve të përdorura në studim dhe të ardhmen e kërkimit.
Studiuesit e DeepMind e bëjnë të qartë në punimin e tyre se kjo “aftësia për të drejtuar procesin e përzgjedhjes së të dhënave drejt shpërndarjes së grupeve të të dhënave më të vogla dhe të mirëkuruara” është thelbësore për suksesin e metodës JEST. Suksesi është fjala e saktë për këtë hulumtim; DeepMind pretendon se “qasja jonë tejkalon modelet më të fundit me deri në 13× më pak përsëritje dhe 10× më pak llogaritje.”
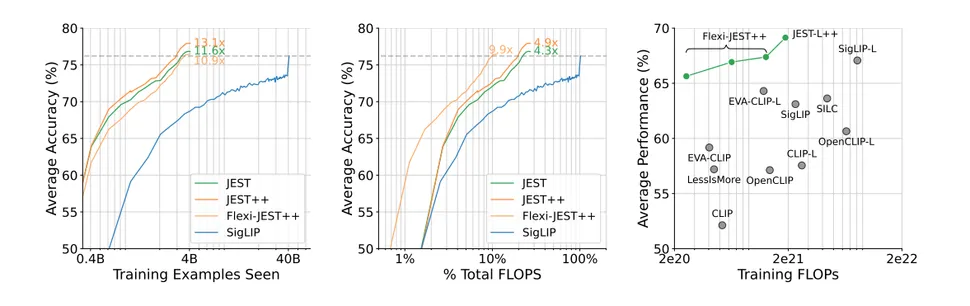
Natyrisht, ky sistem mbështetet tërësisht në cilësinë e të dhënave të tij të trajnimit, pasi teknika e bootstrapping shpërbëhet pa një grup të dhënash të kuruar nga njeriu me cilësinë më të lartë të mundshme. Askund nuk është më e vërtetë mantra “mbeturinat brenda, mbeturinat jashtë” sesa kjo metodë, e cila përpiqet të “kalojë përpara” në procesin e saj të trajnimit. Kjo e bën metodën JEST shumë më të vështirë për hobiistët ose zhvilluesit amatorë të AI-së për t’u përshtatur se shumica e të tjerëve, pasi aftësitë kërkimore të nivelit të ekspertëve ka të ngjarë të kërkohen për të kuruar të dhënat fillestare të trajnimit të klasës më të lartë.
Hulumtimi JEST vjen jo shumë shpejt, pasi industria e teknologjisë dhe qeveritë botërore po fillojnë diskutimet mbi kërkesat ekstreme të fuqisë së inteligjencës artificiale. Ngarkesa e punës së AI mori rreth 4.3 GW në 2023 , pothuajse përputhet me konsumin vjetor të energjisë të kombit të Qipros. Dhe gjërat definitivisht nuk po ngadalësohen: një kërkesë e vetme ChatGPT kushton 10 herë më shumë se një kërkim në Google në fuqi, dhe CEO i Arm vlerëson se AI do të zërë një të katërtën e rrjetit të energjisë elektrike të Shteteve të Bashkuara deri në vitin 2030.
Nëse dhe si metodat JEST adoptohen nga lojtarët kryesorë në hapësirën e AI, mbetet për t’u parë. GPT-4o thuhet se ka kushtuar 100 milionë dollarë për t’u trajnuar , dhe modelet e ardhshme më të mëdha së shpejti mund të arrijnë shifrën miliardë dollarëshe, kështu që firmat ka të ngjarë të kërkojnë mënyra për të shpëtuar kuletat e tyre në këtë departament. Shpresuesit mendojnë se metodat JEST do të përdoren për të mbajtur normat aktuale të produktivitetit të trajnimit me tërheqje shumë më të ulëta të energjisë, duke lehtësuar kostot e AI dhe duke ndihmuar planetin. Megjithatë, ka shumë më tepër gjasa që makina e kapitalit të mbajë pedalin tek metali, duke përdorur metodat JEST për të mbajtur fuqinë në maksimum për rezultate stërvitore tepër të shpejta. Kursimet e kostos kundrejt shkallës së prodhimit, kush do të fitojë?