Microsoft fshin një blog që u thoshte përdoruesve të trajnonin AI me libra të piratuar të Harry Potter

Pas reagimeve të forta në një postim në Hacker News, Microsoft fshiu një postim në blog që, sipas kritikëve, i inkurajonte zhvilluesit të piratonin librat e Harry Potter për të trajnuar modele të inteligjencës artificiale që më pas mund të përdoreshin për të krijuar mbeturina të inteligjencës artificiale.

Blogu, i cili është arkivuar këtu, është shkruar në nëntor 2024 nga një menaxhere e lartë produktesh, Pooja Kamath. Sipas LinkedIn-it të saj, Kamath ka qenë në Microsoft për më shumë se një dekadë dhe mbetet me kompaninë. Në vitin 2024, Microsoft e punësoi atë për të promovuar një veçori të re që blogu tha se e bënte më të lehtë “shtimin e veçorive gjeneruese të IA-së në aplikacionet tuaja me vetëm disa rreshta kodi duke përdorur Azure SQL DB, LangChain dhe LLM”.
Çfarë mënyre më të mirë për të treguar “shembuj tërheqës dhe të lidhshëm” të veçorisë së re të Microsoft-it që do të “jehonin me një audiencë të gjerë” sesa të “përdorësh një grup të dhënash të njohura” si librat e Harry Potter, tha blogu.
Librat janë “një nga seritë më të famshme dhe më të çmuara në historinë letrare”, vuri në dukje blogu, dhe fansat mund t’i përdorin LLM-të që kanë trajnuar në dy mënyra argëtuese: ndërtimin e sistemeve të pyetjeve dhe përgjigjeve që ofrojnë “përgjigje të pasura me kontekst” dhe gjenerimin e “trillimeve të reja të fansave të Harry Potter të drejtuara nga inteligjenca artificiale” që “me siguri do t’i kënaqin ata që janë në krye të listës së Potter-ave”.
Për të ndihmuar klientët e Microsoft të arrinin këtë vizion, blogu u lidh me një të dhënë të Kaggle që përfshinte të shtatë librat e Harry Potter, të cilët, sipas Ars, kanë qenë të disponueshëm në internet për vite me radhë dhe janë shënuar gabimisht si “domen publik”. Kushtet e Kaggle thonë se mbajtësit e të drejtave mund të dërgojnë njoftime për përmbajtje që shkel të drejtat e autorit dhe shkelësit e përsëritur rrezikojnë pezullime, por komentuesit e Hacker News spekuluan se të dhënat e Harry Potter kaluan pa u vënë re, me vetëm 10,000 shkarkime me kalimin e kohës, duke mos tërhequr vëmendjen e J.K. Rowling, e cila njihet për mbajtjen e të drejtave të autorit të Harry Potter. Të dhënat u fshinë menjëherë të enjten pasi Ars kontaktoi ngarkuesin, Shubham Maindola, një shkencëtar të dhënash në Indi pa lidhje të dukshme me Microsoft.
Maindola i tha Ars se “grupi i të dhënave u shënua gabimisht si Domen Publik. Nuk kishte qëllim të keqinterpretohej statusi i licencimit të veprave.”
Nuk është e qartë nëse Kamath u udhëzua të vendoste një lidhje me të dhënat e librave të Harry Potter në blog apo ishte një zgjedhje individuale. Cathay YN Smith, një profesoreshë e drejtësisë dhe bashkëdrejtoreshë e Programit të së Drejtës së Pronësisë Intelektuale të Kolegjit të Drejtësisë Chicago-Kent, i tha Ars se Kamath mund të mos e ketë kuptuar se librat ishin shumë të kohëve të fundit për t’u bërë publike.
“Dikush mund të ketë shumë njohuri rreth librave dhe teknologjisë, por jo domosdoshmërisht rreth kushteve të të drejtave të autorit dhe kohëzgjatjes së tyre”, tha Smith. “Sidomos nëse ajo sheh që diçka është shënuar nga një kompani tjetër me reputacion si pronë publike.”
Microsoft refuzoi kërkesën e Ars për të komentuar. Kaggle nuk iu përgjigj kërkesës së Ars për të komentuar.
Në Hacker News, komentuesit sugjeruan se nuk ka gjasa që dikush i njohur me serialin popullor të besojë se librat e Harry Potter ishin në domenin publik. Ata debatuan nëse blogu i Microsoft ishte “problematik për sa i përket të drejtave të autorit”, pasi Microsoft jo vetëm që i inkurajoi klientët të shkarkonin materialet shkelëse, por gjithashtu përdori vetë librat për të krijuar modele të inteligjencës artificiale të Harry Potter që mbështeteshin në personazhe të dashur për të reklamuar produktet e Microsoft.
Blogu i Microsoft u postua më shumë se një vit më parë, në një kohë kur firmat e inteligjencës artificiale filluan të përballeshin me padi për modelet e inteligjencës artificiale, të cilat dyshohet se kishin shkelur të drejtat e autorit duke u trajnuar mbi materiale të piratuara dhe duke i riprodhuar veprat fjalë për fjalë.
Blogu rekomandoi që përdoruesit të mësonin të trajnonin modelet e tyre të IA-së duke shkarkuar të dhënat e Harry Potter dhe më pas duke ngarkuar skedarë teksti në Azure Blob Storage. Ai përfshinte modele shembullore të bazuara në një të dhënë që Microsoft me sa duket e kishte ngarkuar në Azure Blob Storage, i cili përfshinte vetëm librin e parë, Harry Potter dhe Guri i Magjistarit.
Duke trajnuar modele të mëdha gjuhësore (LLM) në skedarë teksti, fansat e Harry Potter mund të krijonin sisteme pyetje-përgjigje të afta për të nxjerrë fragmente relevante nga librat. Një shembull i pyetjes së ofruar ishte “Ushqimet e Botës Magjike”, e cila nxirrte një fragment nga Guri i Magjistarit ku Harry mahnitet me ëmbëlsira të çuditshme si Fasulet me Çdo Shije të Bertie Bott dhe bretkosat me çokollatë. Një pyetje tjetër që pyeste “Si u ndie Harry kur mësoi për herë të parë se ishte Magjistar?” gjeneroi një rezultat që tregonte fragmente të ndryshme të hershme në libër.
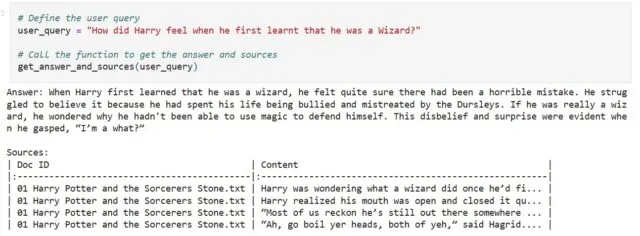
Por ndoshta një rast përdorimi edhe më emocionues, sugjeroi Kamath, ishte gjenerimi i trillimeve nga fansat për të “eksploruar aventura të reja” dhe “madje për të krijuar funde alternative”. Ky model mund të kërkonte shpejt të dhënat për fragmente “të ngjashme në kontekst” që mund të përdoreshin për të nxjerrë histori të reja që përputhen me rrëfimet ekzistuese dhe përfshijnë “elemente nga fragmentet e rikuperuara”, tha blogu.
Si shembull, Kamath trajnoi një modele për të shkruar një histori për Harry Potter që ajo mund ta përdorte për të tregtuar artikullin për të cilin po shkruante në blog. Ajo i kërkoi modeles të shkruante një histori në të cilën Harry takon një mik të ri në trenin Hogwarts Express, i cili i tregon gjithçka rreth Mbështetjes Vektoriale Native të Microsoft në SQL “në botën e Babanacëve”.
Duke u bazuar në pjesë të Gurit të Magjistarit ku Harry mëson për Kuidiçin dhe njihet me Hermione Granger, tregimi me fansa tregonte një djalë që i shiste Harryt veçorinë e re “të mahnitshme” të Microsoft. Për ta bërë këtë, ai e krahasoi atë me një magji që të ndihmon të gjesh saktësisht atë që të nevojitet midis mijëra opsioneve, menjëherë, ndërsa deklaroi se ishte perfekte për të mësuarit automatik, inteligjencën artificiale dhe sistemet e rekomandimit.
Duke i zbehur më tej vijat ndarëse midis markave Microsoft dhe Harry Potter, Kamath krijoi gjithashtu një imazh që tregon Harryn me mikun e tij të ri, të stampuar me një logo të Microsoft.
Smith i tha Ars se të dy rastet e përdorimit mund të frustrojnë mbajtësit e të drejtave, varësisht nga përmbajtja në rezultatet e modelit.
“Mendoj se riprodhimi dhe krijimi i trillimeve me fansa, të dyja mund të sinjalizojnë problemet e të drejtave të autorit, në atë që trillimet me fansa shpesh duhet të heqin elementët shprehës, një personazh të mbrojtur me të drejta autori, një personazh që është mjaftueshëm i famshëm për t’u mbrojtur nga një ligj i të drejtave të autorit ose nga histori apo sekuenca të komplotit”, tha Smith. “Nëse këto gjëra kopjohen dhe riprodhohen, atëherë ky rezultat mund të jetë potencialisht shkelës.”
Por është gjithashtu ende një zonë gri. Duke parë blogun, Smith tha: “Do të isha i shqetësuar”, por “nuk do të thoja se është automatikisht shkelje”.
Smith i tha Ars se, duke tërhequr blogun, Microsoft “ndoshta ishte i zgjuar”, pasi gjykatat vetëm në përgjithësi kanë thënë se trajnimi i IA-së në libra me të drejta autoriale është përdorim i drejtë. Por gjykatat vazhdojnë të hetojnë pyetje në lidhje me materialet e trajnimit të piratuara të IA-së.
Në faqen e fshirë të të dhënave të Kaggle, Maindola më parë shpjegoi se për të gjetur burimin e të dhënave, ai “shkarkoi librat elektronikë dhe më pas i konvertoi ato në skedarë txt”.
Nëse Microsoft është përballur ndonjëherë me pyetje nëse kompania ka përdorur me vetëdije libra të piratuar për të trajnuar modelet shembull, përdorimi i drejtë “mund të jetë një argument i vështirë”, tha Smith.
Komentuesit e Hacker News sugjeruan që blogu mund të konsiderohej si përdorim i drejtë, pasi udhëzuesi i trajnimit ishte për “qëllime edukative”, dhe Smith tha se Microsoft mund të ngrinte disa “argumente të mira” në mbrojtje të tij.
Megjithatë, ajo sugjeroi gjithashtu që Microsoft mund të konsiderohet përgjegjës për kontributin në shkelje në një nivel të caktuar, pasi e la blogun aktiv për një vit. Përpara se të hiqej, të dhënat e Kaggle u shkarkuan më shumë se 10,000 herë.
“Rezultati përfundimtar është të krijosh diçka që shkel të drejtat e autorit duke thënë, ‘Hej, ja ku jeni, shkoni kapni atë material që shkel të drejtat dhe përdoreni në sistemin tonë’,” tha Smith. “Ata potencialisht mund të kenë një lloj përgjegjësie dytësore kontribuese për shkeljen e të drejtave të autorit, shkarkimin e tij, si dhe përdorimin e tij për të inkurajuar të tjerët ta përdorin atë për qëllime trajnimi.”
Në Hacker News, komentuesit e kritikuan ashpër blogun, përfshirë një të vetëshpallur ish-punonjës të Microsoft i cili pretendoi se Microsoft i lejon punonjësit “të shkruajnë në blog pa pasur nevojë të kalojnë nëpër ndonjë proces miratimi ose redaktimi”.
Duket sikur dikush ka marrë një vendim të gabuar në lidhje me atë që duhet të shënohet në një postim në blogun e një kompanie (dhe ndoshta çfarë përbën aktivitet etik) dhe se postimi është hequr sapo dikush e ka vënë re, tha ish-punonjësi.
Të tjerë sugjeruan se faji ishte vetëm i ngarkuesit të Kaggle, Maindola, i cili i tha Ars se të dhënat nuk duhej të ishin shënuar kurrë si “domen publik”. Por kritikët e Microsoft kundërshtuan, duke vënë në dukje se faqja e Kaggle e bëri të qartë se nuk ishte dhënë asnjë leje e veçantë dhe se punonjësi i Microsoft duhet ta kishte ditur më mirë. “Ata nuk kanë nevojë të dinë ndonjë detaj për të ditur se këto prona i përkasin kompanive të mëdha dhe nuk janë të lira për t’u marrë”, tha një komentues.
Librat e Harry Potter nuk ishin të vetmit libra të shënjestruar, vuri në dukje postimi, duke lidhur me një mostër të veçantë të Azure që përmban serinë Foundation të Isaac Asimov, e cila gjithashtu nuk është në domenin publik.
“Microsoft mund të kishte përdorur çdo grup të dhënash për blogun e tyre, madje mund të kishin zgjedhur të përdornin romane aktuale në domenin publik”, shkroi një komentues tjetër i Hacker News. “Në vend të kësaj, ata zgjodhën të përdorin vepra të shkruara me të drejta autoriale që JK nuk i ka publikuar në domenin publik (përveç nëse përdoruesi ‘Shubham Maindola’ është alter egoja e JK-së).”
Smith sugjeroi që Microsoft mund ta kishte shmangur reagimin e ashpër të kësaj jave duke shqyrtuar më me kujdes blogjet, duke vënë në dukje se “nëse një kompani nuk i pëlqen rreziku, kjo ndoshta do të sinjalizohej”. Por ajo gjithashtu e kuptoi preferencën e Kamath për Harry Potter mbi shumë personazhe të harruar prej kohësh që ekzistojnë në domenin publik. Në Hacker News, disa komentues mbrojtën blogun e Kamath, duke kërkuar që ai të konsiderohet si përdorim i drejtë, pasi organizatat jofitimprurëse dhe institucionet arsimore mund të bënin të njëjtën gjë në një kontekst mësimdhënieje pa problem.
Do të isha shqetësuar nëse do të isha unë ai që do ta pastronte këtë për Microsoft-in, por në të njëjtën kohë, e kuptoj plotësisht se çfarë po bënte ky punonjës, tha Smith. Askush nuk dëshiron të shkruajë trillime fansash për libra që janë në domenin publik.