Modelet e inteligjencës artificiale shpesh japin përgjigjet e sakta, por tregojnë burime të gabuara

Vetëm pse një model gjuhësor i përgjigjet një pyetjeje në lidhje me një PDF nuk do të thotë se e ka gjetur përgjigjen aty ku pretendon.
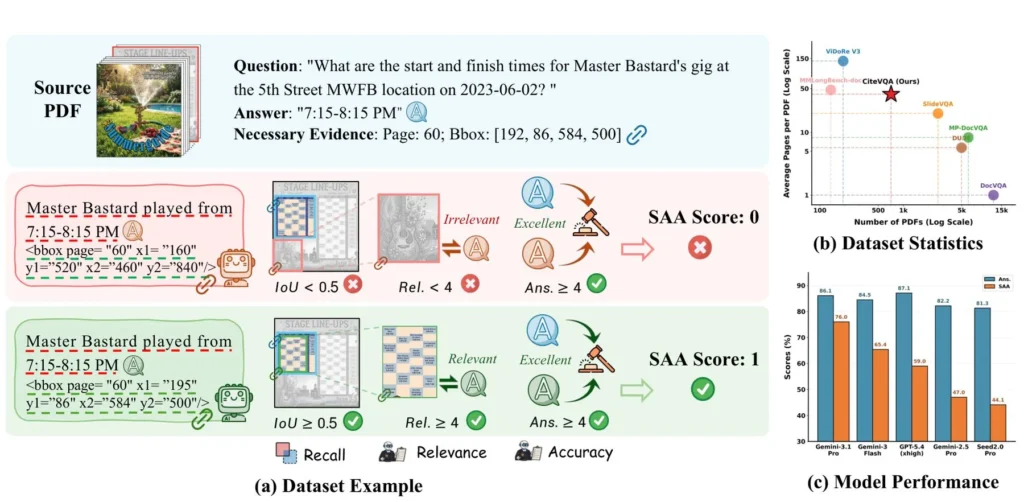
Studiuesit në Universitetin e Pekinit dhe Laboratorin e Inteligjencës Artificiale të Shangait ndërtuan një pikë referimi të re të quajtur CiteVQA për të zbuluar këtë boshllëk midis marrjes së përgjigjes së saktë dhe drejtimit të burimit të duhur. Ata e quajnë atë “halucinacion atribuimi”.
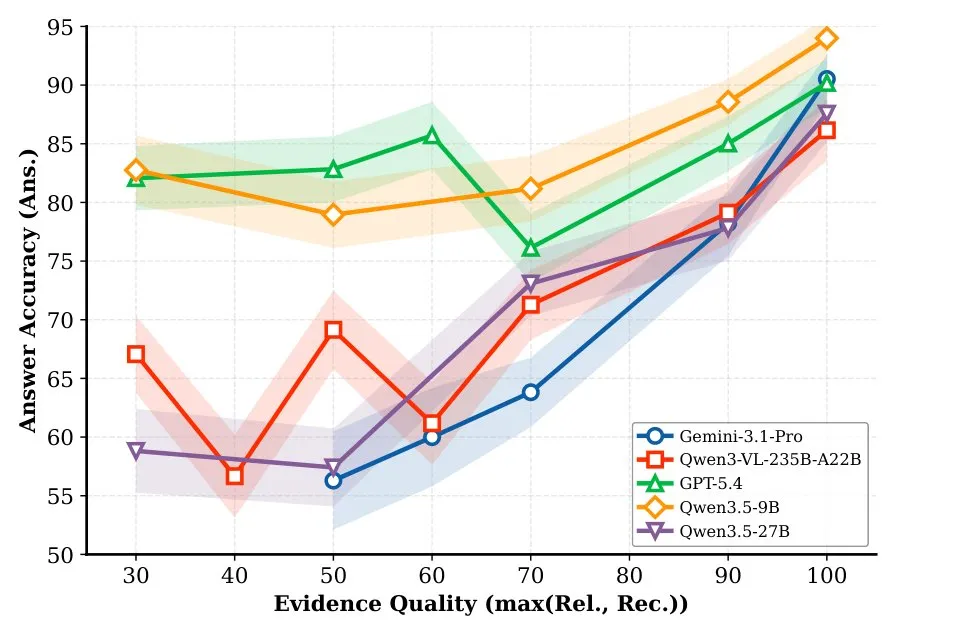
Testet standarde të analizës së dokumenteve si DocVQA ose MMLongBench-Doc vlerësojnë vetëm përgjigjen përfundimtare. Ato nuk mund të tregojnë nëse një model ka nxjerrë në të vërtetë informacion nga dokumenti apo thjesht ka hamendësuar bazuar në atë që tashmë e dinte. Megjithatë, në ligj, auditimet financiare ose mjekësi, gjurmueshmëria është ajo që e bën një rezultat të inteligjencës artificiale të përdorshëm në radhë të parë, argumenton dokumenti.
CiteVQA i bën modelet të mbështesin çdo deklaratë me një shënues të saktë në dokument. Ato duhet të tregojnë paragrafin, tabelën ose figurën e saktë. Vetëm një numër faqeje nuk mjafton. Seti i të dhënave mbulon 1,897 pyetje në 711 PDF nga shtatë fusha lëndore: 451 në anglisht dhe 260 në kinezisht. Dokumentet mesatarisht kanë 40.6 faqe secili, shumë më gjatë se shumica e standardeve.