Standardi i ri i Sierra zbulon se sa mirë performojnë agjentët e AI në punën reale

Sierra, startup-i i përvojës së klientit me AI i krijuar nga anëtari i bordit të OpenAI, Bret Taylor dhe veterani i Google AR/VR, Clay Bavor, ka zhvilluar një standard të ri për të vlerësuar performancën e agjentëve bisedues të AI. I quajtur TAU-bench, agjentët testohen në përfundimin e detyrave komplekse ndërkohë që kanë shkëmbime të shumta me përdoruesit e simuluar nga LLM për të mbledhur informacionin e kërkuar. Rezultatet e hershme tregojnë se agjentët e AI të ndërtuar me konstruksione të thjeshta LLM, si thirrja e funksionit ose ReAct, nuk ia dalin mirë në lidhje me “detyrat relativisht të thjeshta”, duke nënvizuar besimin që kompanitë kanë nevojë për arkitektura më të sofistikuara agjentësh.
Zhvilluesit e interesuar për të ekzaminuar kodin e TAU-bench mund ta shkarkojnë atë nga depoja e Sierra GitHub.
“Në Sierra, përvoja jonë në aktivizimin e agjentëve bisedues në botën reale që përballen me përdoruesit e ka bërë një gjë jashtëzakonisht të qartë: një matje e fortë e performancës dhe besueshmërisë së agjentëve është kritike për vendosjen e tyre të suksesshme. Përpara se kompanitë të vendosin një agjent të AI, ato duhet të matin se sa mirë po funksionon në një skenar sa më real që të jetë e mundur,” shkruan Karthik Narasimhan, kreu i kërkimit në Sierra.
Ai pretendon se standardet ekzistuese, të tilla si WebArena, SWE-bench dhe Agentbench, nuk janë në disa fusha kyçe. Megjithëse ata mund të zbulojnë aftësitë e nivelit të lartë të një agjenti, ata vlerësojnë vetëm një raund të vetëm të ndërveprimit njeri-agjent si më poshtë:
Përdoruesi: “Si është moti sot në Nju Jork?”
AI: “Sot në Nju Jork, është me diell me një temperaturë maksimale prej 75°F (24°C) dhe një temperaturë minimale prej 60°F (16°C).”
Kjo është kufizuese sepse, në skenarët e jetës reale, agjentët do të duhet të marrin këtë informacion duke përdorur shkëmbime të shumta dinamike:
Përdoruesi: “Dua të rezervoj një fluturim.”
AI: “Sigurisht! Nga dhe për nga do të dëshironit të fluturonit?”
Përdoruesi: “Nga Çikago në Miami.”
AI: “E kuptova. Kur do të dëshironit të udhëtoni?”
Përdoruesi: “Të Premten tjetër.”
AI: “Mirë. Keni një preferencë për orën e nisjes?”
… (biseda vazhdon)
Narasimhan argumenton se këto standarde fokusohen gjithashtu në statistika të rendit të parë, siç është performanca mesatare. Megjithatë, ato nuk ofrojnë matje të besueshmërisë ose përshtatshmërisë.
Për të adresuar këto çështje me Tau-bench, Sierra identifikoi tre kërkesa për standardin. E para është se shumica e cilësimeve të botës reale kërkojnë që agjentët të ndërveprojnë pa probleme me njerëzit dhe API-të programatike për një periudhë të gjatë kohore për të mbledhur informacion dhe për të zgjidhur probleme komplekse. Më pas, agjentët duhet të jenë në gjendje të ndjekin me saktësi politikat ose rregullat komplekse specifike për detyrën. Së fundi, agjentët duhet të jenë të qëndrueshëm dhe të besueshëm në shkallë për t’u dhënë kompanive paqe mendore për të ditur se si do të sillen.
TAU-bench cakton disa detyra për agjentët që të plotësojnë, nga puna me bazat e të dhënave realiste dhe API-të e mjeteve deri te dokumentet e politikave specifike të domenit që diktojnë sjelljen e kërkuar të agjentit dhe një simulator përdoruesi të bazuar në LLM të udhëhequr nga udhëzimet për skenarë të ndryshëm për të gjeneruar biseda realiste me agjentin. Çdo detyrë vlerëson aftësinë e agjentit për të ndjekur rregullat, për të arsyetuar, për të ruajtur informacionin në kontekste të gjata dhe komplekse dhe për të komunikuar në një bisedë realiste.
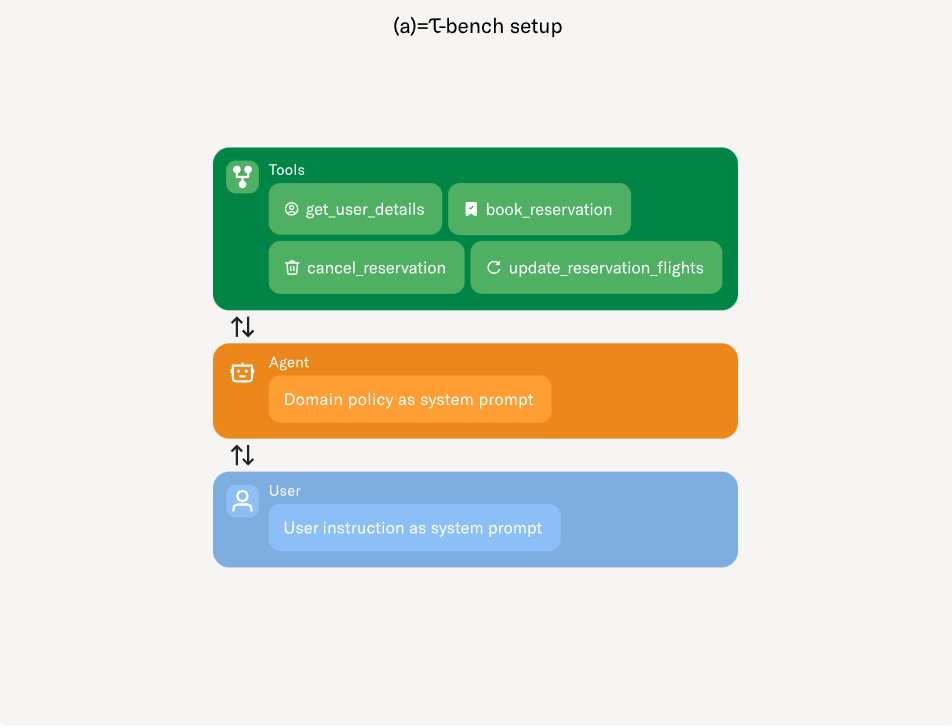
Narasimhan përshkruan katër karakteristika kryesore të standardit të ri të Sierra:
Dialogu realist dhe përdorimi i mjeteve: Nëpërmjet modelimit gjenerues për gjuhën, TAU-bench paraqet skenarë komplekse të përdoruesve të prodhuar duke përdorur gjuhën natyrore në vend që të mbështeten në shkrimin kompleks të rregullave.
Detyra të hapura dhe të larmishme: TAU-bench përmban struktura të pasura, të detajuara, ndërfaqe dhe grupe rregullash, duke lejuar krijimin e detyrave pa zgjidhje të thjeshta dhe të paracaktuara. Kjo sfidon agjentët e AI për të trajtuar situata të ndryshme që ata mund të hasin në botën reale.
Vlerësimi besnik objektiv: Ky pikë referimi nuk shikon cilësinë e bisedës. Në vend të kësaj, ai vlerëson rezultatin, gjendjen përfundimtare pas përfundimit të detyrës. Të bësh këtë i jep një masë objektive nëse agjenti i AI arrin me sukses qëllimin e detyrës, duke eliminuar nevojën për gjyqtarë njerëzorë ose vlerësues shtesë.
Korniza modulare: Për shkak se TAU-bench është ndërtuar si një grup blloqesh ndërtimi, është e lehtë të shtoni elementë të rinj si domenet, hyrjet në bazën e të dhënave, rregullat, API-të, detyrat dhe metrikat e vlerësimit.
Sierra testoi TAU-bench duke përdorur 12 LLM të njohura nga OpenAI, Anthropic (Claude 3.5 Sonet nuk ishte përfshirë), Google dhe Mistral. U zbulua se të gjithë kishin vështirësi në zgjidhjen e detyrave. Në fakt, agjenti me performancën më të mirë nga GPT-4o i OpenAI kishte një shkallë mesatare suksesi më pak se 50 përqind në dy fusha.
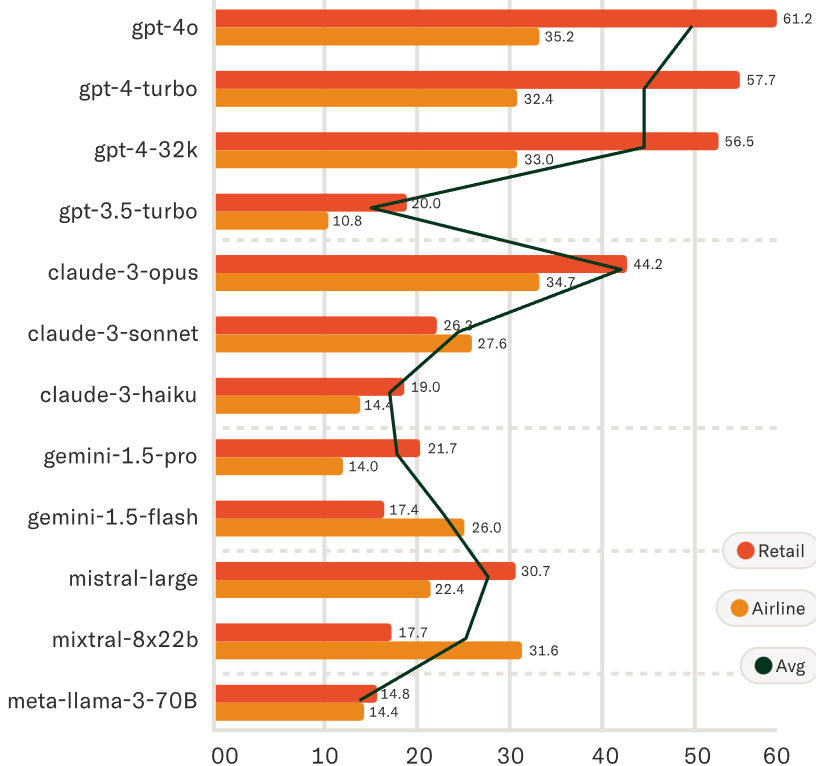
Për më tepër, të gjithë agjentët e testuar performuan “jashtëzakonisht dobët” në besueshmërinë dhe “nuk ishin në gjendje të zgjidhnin vazhdimisht të njëjtën detyrë kur episodi rishfaqet”.
E gjithë kjo e çon Narasimhanin në përfundimin se nevojiten LLM më të avancuara për të përmirësuar arsyetimin dhe planifikimin së bashku me krijimin e skenarëve më kompleksë. Ai gjithashtu bën thirrje për metoda të reja për ta bërë më të lehtë shënimin përmes përdorimit të mjeteve të automatizuara dhe që të zhvillohen metrika vlerësimi më të hollësishme për të testuar aspekte të tjera të sjelljes së një agjenti, si toni dhe stili i tij.